
1.整体性能分析
图7-11和图7-12分别显示了优化后的Viola-Jones人脸检测算法在AMD HD7970和NVIDIA GTX680两个不同GPU计算平台上的性能及相对于CPU版本的性能提升。值得注意的是,OpenCL版本的性能测定包含了OpenCL程序运行的所有时间,包括:OpenCL初始化时间、CPU和GPU间的数据传输时间以及kernel的运行时间。
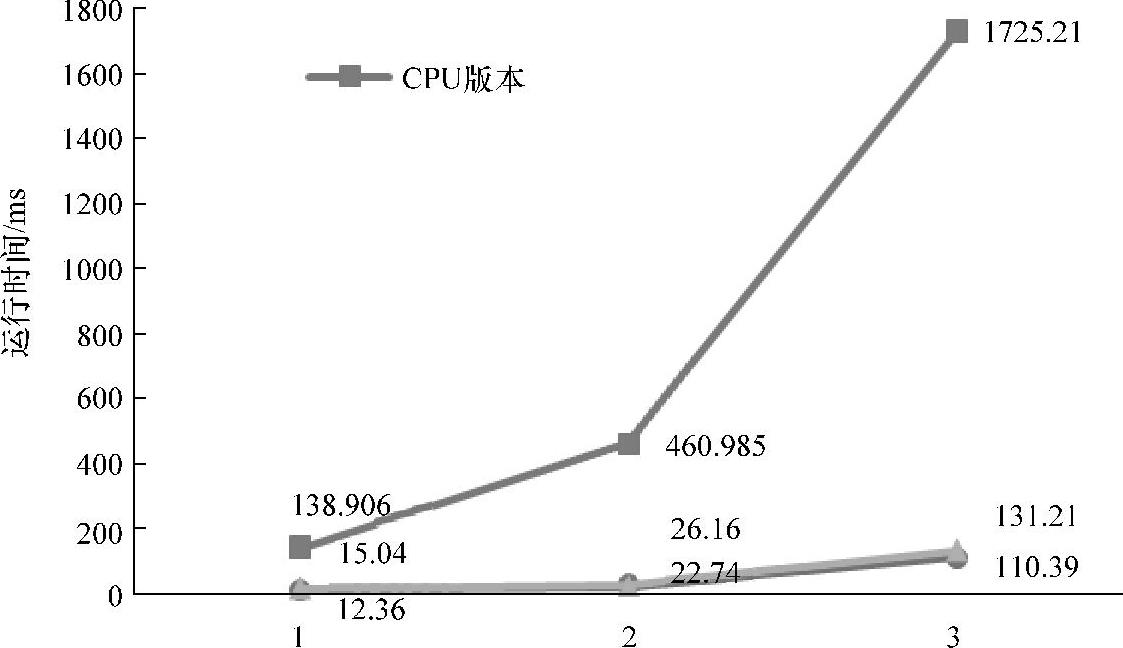
图7-11 OpenCL版本与CPU版本性能对比
从中我们可以看出,与人脸检测的CPU版本的性能相比,本书实现的OpenCL版本在两个GPU计算平台上处理不同的图片都达到了可观的加速比:在AMD HD7970 GPU计算平台上,实现了11.24~20.27的性能加速;在NVIDIA GTX680计算平台上,实现了9.24~17.62的性能加速。可以看到,NVIDIA GTX 680 GPU与AMD HD7970 GPU相比,在性能提升方面略有差距。这主要是因为前者在峰值计算性能和峰值访存带宽这两个主要的性能参数方面,弱于后者。
图7-11和图7-12不仅说明了我们优化框架的有效性,有效地解决了算法负载不均衡的问题;而且说明了虽然两个GPU计算平台的架构不同,计算单元的组织也不相同,但是二者都采用了层次式架构,优化技术和方法也大致相同,只要对性能参数进行精心抽取和定义(如7.3.3小节中的每个work-group一次处理的窗口数N以及work-group内线程处理一次协同处理的窗口数M等),是完全可以实现不同GPU计算平台间性能移植的。
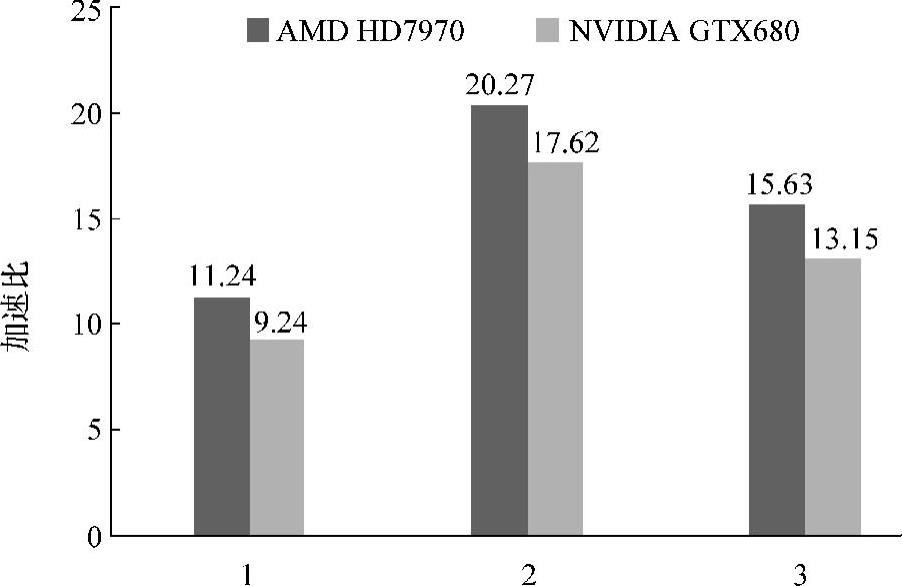
图7-12 在两个GPU上的性能加速
同时,我们可以看到,对于不同图像,GPU的加速效果也是不同的。主要有两方面的原因:第一,GPU是大规模并行处理器,理论上,图片规模越大,计算量越大,越能充分利用GPU计算平台强大的计算能力,加速效果也就越好。第二,图像的背景和人脸数目不同,算法的总体计算量也不同。同时,算法在处理不同图片时的负载不均衡的程度也不尽相同,从而进一步影响GPU计算平台对性能的提升效果。
2.不同优化方法对性能的影响
图7-13显示了以Naïve版本为基准,采用不同优化方法后,在两个GPU计算平台上所带来的性能提升。
从图7-13中,我们可以看到六点:
 在两个GPU计算平台上,不同优化方法带来的性能提升虽有差异,但趋势大致相同。这不仅说明了两个GPU计算平台在整体架构设计上的统一性,而且说明了在两个GPU计算平台上,线程间负载不均衡都是最严重的性能瓶颈,都是导致性能降低的主要因素。
在两个GPU计算平台上,不同优化方法带来的性能提升虽有差异,但趋势大致相同。这不仅说明了两个GPU计算平台在整体架构设计上的统一性,而且说明了在两个GPU计算平台上,线程间负载不均衡都是最严重的性能瓶颈,都是导致性能降低的主要因素。
 线程与任务的动态映射带来的性能提升最大,注意这里的线程与任务动态映射实际指的是动态映射+全局队列,因为两者是一个统一整体,没有必要分开说明。从性能图中可以看出,采用传统GPU静态编程模式,work-group间的负载不均衡会导致性能的极大降低,这是因为图片中绝大部分区域没有人脸,大量的线程可能运行很短的时间就会退出等待,只有少量线程在运行。而线程和任务的动态映射很好地解决了这个问题,因为线程和任务动态映射的核心是根据线程的实际任务负载情况,动态进行任务的分配。这样就可以让执行大任务的线程,执行的任务数量就少一些;执行小任务量的线程,执行的任务数量就多一些。这就从根本上解决了work-group间负载不均衡的问题。(www.daowen.com)
线程与任务的动态映射带来的性能提升最大,注意这里的线程与任务动态映射实际指的是动态映射+全局队列,因为两者是一个统一整体,没有必要分开说明。从性能图中可以看出,采用传统GPU静态编程模式,work-group间的负载不均衡会导致性能的极大降低,这是因为图片中绝大部分区域没有人脸,大量的线程可能运行很短的时间就会退出等待,只有少量线程在运行。而线程和任务的动态映射很好地解决了这个问题,因为线程和任务动态映射的核心是根据线程的实际任务负载情况,动态进行任务的分配。这样就可以让执行大任务的线程,执行的任务数量就少一些;执行小任务量的线程,执行的任务数量就多一些。这就从根本上解决了work-group间负载不均衡的问题。(www.daowen.com)
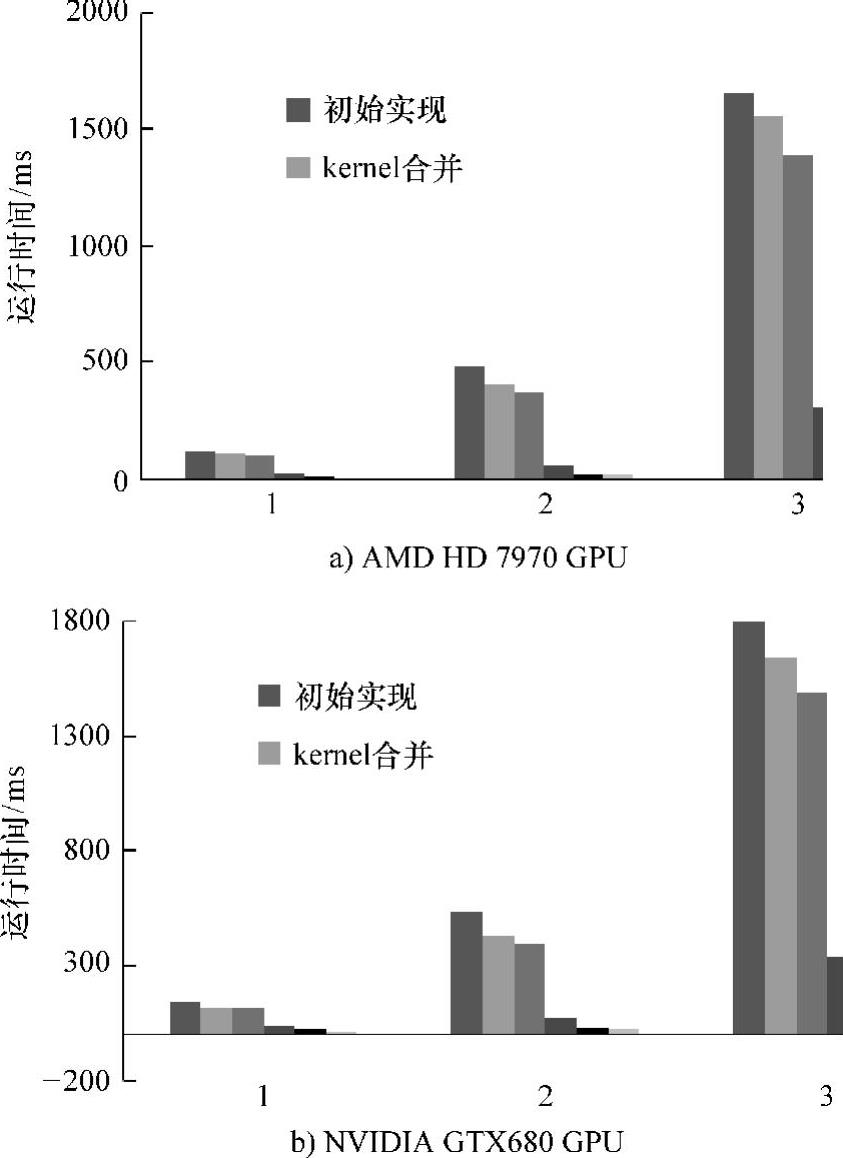
图7-13 不同优化方法在两个GPU计算平台上的性能提升
 本地队列也有效地提升了算法性能。这说明了三点:①work-group内同样存在线程间负载不均衡问题,同样会影响程序性能;②work-group内线程间负载不均衡对性能的影响没有work-group间的负载不均衡对性能的影响大,这是因为一个work-group处理的图像区域毕竟有限,线程间的计算量并不会差距太大;③本地队列很好地解决了work-group内线程间的负载不均衡问题。
本地队列也有效地提升了算法性能。这说明了三点:①work-group内同样存在线程间负载不均衡问题,同样会影响程序性能;②work-group内线程间负载不均衡对性能的影响没有work-group间的负载不均衡对性能的影响大,这是因为一个work-group处理的图像区域毕竟有限,线程间的计算量并不会差距太大;③本地队列很好地解决了work-group内线程间的负载不均衡问题。
 传统优化方法带来的性能提升并不明显。这就说明了负载不均衡是人脸检测算法在GPU计算平台上的性能瓶颈,传统意义上引起性能下降的因素在该算法上体现得并不明显。但同时也说明了,只要解决负载不均衡问题,传统优化方法依然会改善GPU计算资源的利用率,同样可以带来性能提升。
传统优化方法带来的性能提升并不明显。这就说明了负载不均衡是人脸检测算法在GPU计算平台上的性能瓶颈,传统意义上引起性能下降的因素在该算法上体现得并不明显。但同时也说明了,只要解决负载不均衡问题,传统优化方法依然会改善GPU计算资源的利用率,同样可以带来性能提升。
 虽然Persistent Thread和kernel合并对性能的提升有限,但是两者是整个优化框架的基础。对性能影响最大的线程与任务的动态映射机制构建的基础就是Per-sistent Thread和kernel合并。粗粒度并行虽然无法测试对性能的具体影响,但同样作为优化框架的基础,同本地队列一起,克服work-group内线程间的负载不均衡问题,从而在一定程度上提升算法性能。
虽然Persistent Thread和kernel合并对性能的提升有限,但是两者是整个优化框架的基础。对性能影响最大的线程与任务的动态映射机制构建的基础就是Per-sistent Thread和kernel合并。粗粒度并行虽然无法测试对性能的具体影响,但同样作为优化框架的基础,同本地队列一起,克服work-group内线程间的负载不均衡问题,从而在一定程度上提升算法性能。
 通过该算法的优化,说明了只要经过精心优化,具有负载不均衡特征的非规则算法在GPU计算平台上也能够取得非常好的加速比。因此,GPU不仅对规则的数据级并行能够取得很好的加速效果,对于不规则的任务级并行,只要优化方法得当,也会取得相当可观的性能加速效果。这无疑会大大扩展GPU计算平台的应用场景。
通过该算法的优化,说明了只要经过精心优化,具有负载不均衡特征的非规则算法在GPU计算平台上也能够取得非常好的加速比。因此,GPU不仅对规则的数据级并行能够取得很好的加速效果,对于不规则的任务级并行,只要优化方法得当,也会取得相当可观的性能加速效果。这无疑会大大扩展GPU计算平台的应用场景。
3.以往工作对比
虽然有很多关于Viola-Jones人脸检测算法的GPU移植工作,但很少有发布出来的代码或者库。而针对不同图片,人脸检测算法的性能又具有很大的差异性。因此,在与以往工作的对比上,本书只选取了OpenCV2.4库中该算法的OpenCL实现版本。但考虑到OpenCV在计算机视觉领域应用的广泛性,这个对比也在一定程度上体现了我们工作的有效性。
图7-14显示了本书实现与OpenCV2.4中人脸检测算法的OpenCL版本的性能对比。从图中可以看出,相对于OpenCV库的实现,本书实现在两个GPU计算平台上,针对不同图片都取得了较大的性能提升。具体为:在AMDHD7970计算平台上,取得了27.1%~37.9%的性能提升;在NVIDIA GTX 680计算平台上取得了20.6%~31.7%的性能提升。
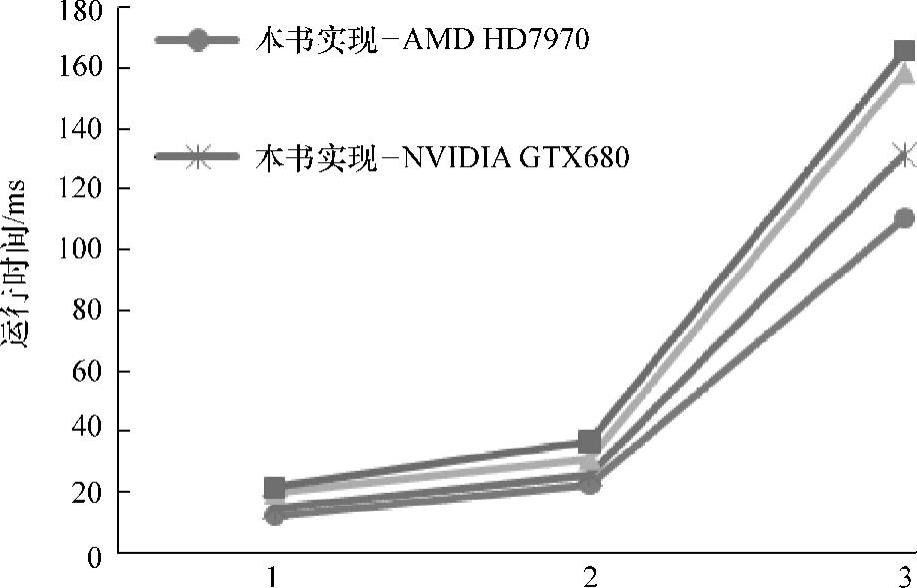
图7-14 本书实现与OpenCV的性能对比
本书实现取得性能提升的主要原因是work-group间负载不均衡问题的解决:OpenCV库的OpenCL实现版本中,全局队列依旧采用静态调度方式,没有很好地解决全局队列的任务调度问题,work-group间的负载不均衡问题依然没有改善。而在本书中,实现了线程与任务的动态映射机制,全局队列可以根据线程的实际任务负载情况进行任务分配,很好地解决了work-group间的负载不均衡问题。
总之,本书提出的优化框架很好地解决了Viola-Jones人脸检测算法在GPU的实现和优化中,由于负载不均衡导致的性能瓶颈,取得了可观的性能加速比。该框架的六个组成部分,即各司其职,又相互协作,共同提升了人脸检测算法在GPU计算平台上的性能。同时,该框架不仅适用于人脸检测算法,而且对于其他具有类似特征的算法,也具有很好的指导意义和参考价值。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






