如上节分析,Viola-Jones人脸检测算法虽然具有很好的并行性,但在GPU移植中存在负载不均衡的非规则特性。这种非规则特性是GPU计算平台的梦魇:一方面,GPU具有大规模细粒度并行的架构特点,负载不均衡会导致GPU计算资源利用率的降低;另一方面,现代GPU的线程调度采用静态调度策略,如不进行针对性优化,无法自动处理负载不均衡问题。更为严重的是,传统的GPU编程和优化方法并没有涉及对负载不均衡现象的处理和优化。因此,负载不均衡现象将会成为人脸检测算法在GPU计算平台上的性能瓶颈,仅仅使用传统GPU编程和优化方法(即计算、访存和数据本地化优化),无法克服该瓶颈,将严重制约算法性能。对此,本书将针对Viola-Jones人脸检测算法的特性,结合GPU的架构特征,提出一种并行优化框架,以突破由于负载不均衡导致的性能瓶颈。图7-5显示了该优化框架的整体架构。
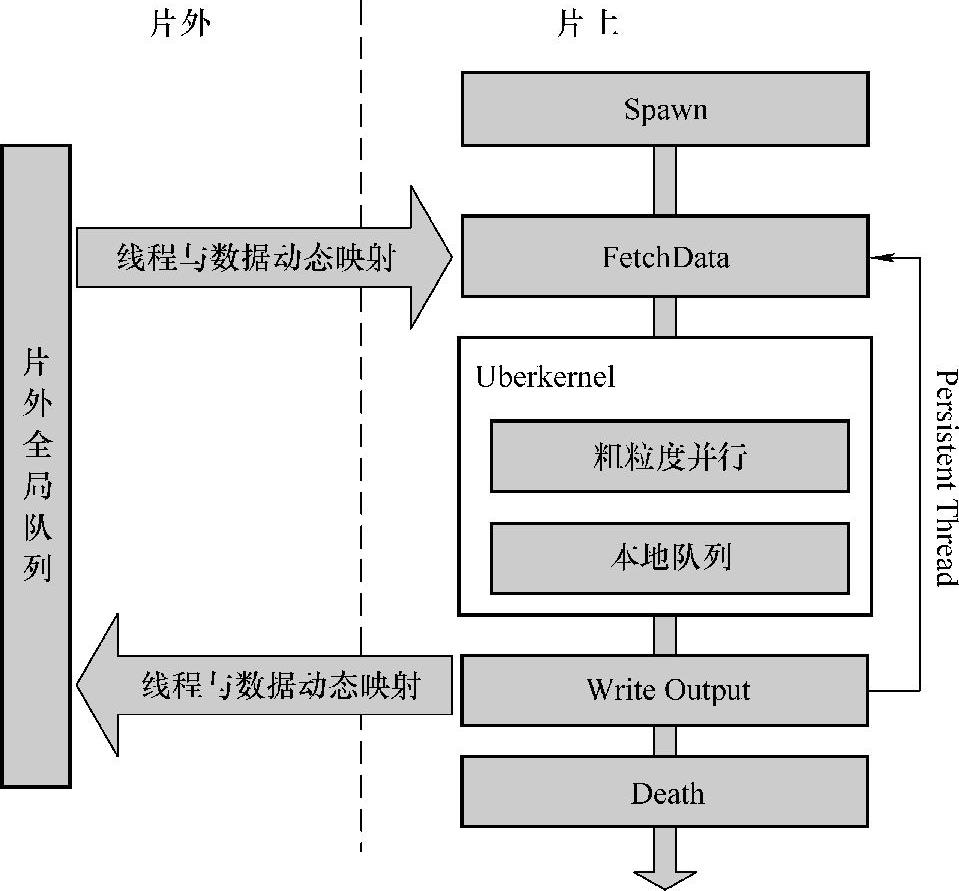
图7-5 并行优化框架
并行优化框架主要由六部分组成:粗粒度并行、Persistent Thread、Uberkernel、线程与数据的动态映射、全局及本地队列。这六个组成部分相互协同,共同解决由于负载不均衡导致的性能瓶颈问题:
 Uberkernel。将执行人脸检测算法主要计算部分的多个kernel合并为一个Uberkernel,统一负责人脸检测。这样一方面可以减少kernel的启动和全局同步开销,另一方面也可解决图像级负载不均衡问题。
Uberkernel。将执行人脸检测算法主要计算部分的多个kernel合并为一个Uberkernel,统一负责人脸检测。这样一方面可以减少kernel的启动和全局同步开销,另一方面也可解决图像级负载不均衡问题。
 Persistent Thread与粗粒度并行。Persistent Thread和粗粒度并行共同定义了Uberkernel的线程组织和运行方式,作为解决线程间负载不均衡问题的基础。粗粒度并行通过重新定义线程组织方式,提升GPU并行粒度:由thread变为warp(wavefront,AMD GPU),在一定程度上缓和负载不均衡对性能的影响。Persistent Thread重新定义GPU thread的运行方式,使thread的生命周期和OpenCL kernel的生命周期相同,可循环处理多个任务。
Persistent Thread与粗粒度并行。Persistent Thread和粗粒度并行共同定义了Uberkernel的线程组织和运行方式,作为解决线程间负载不均衡问题的基础。粗粒度并行通过重新定义线程组织方式,提升GPU并行粒度:由thread变为warp(wavefront,AMD GPU),在一定程度上缓和负载不均衡对性能的影响。Persistent Thread重新定义GPU thread的运行方式,使thread的生命周期和OpenCL kernel的生命周期相同,可循环处理多个任务。
 动态映射与全局队列。在线程和任务的映射上,本书不采用传统GPU编程中的静态映射方式,而是构建线程与任务的动态映射机制,根据线程的任务负载情况,实现线程和任务的动态映射。同时构建以此为任务调度策略的全局队列,解决work-group间负载不均衡的问题。
动态映射与全局队列。在线程和任务的映射上,本书不采用传统GPU编程中的静态映射方式,而是构建线程与任务的动态映射机制,根据线程的任务负载情况,实现线程和任务的动态映射。同时构建以此为任务调度策略的全局队列,解决work-group间负载不均衡的问题。
 本地队列。构建位于共享内存(LDS,AMD GPU)的本地队列,work-group内的所有线程协同工作,解决work-group内的负载不均衡问题。
本地队列。构建位于共享内存(LDS,AMD GPU)的本地队列,work-group内的所有线程协同工作,解决work-group内的负载不均衡问题。
本节将对以上关键优化方法和技术进行详细讨论和介绍。
1.Uberkernel
如7.2.2小节所述,为检测图像中不同大小的人脸,需要按照一定的缩放因子对图像进行缩放,直到缩放图像和检测窗口为同等大小为止,这样就形成了一个缩放图像集。如果一次只处理一幅图像,并通过在CPU端通过多次启动GPUkernel循环处理这些缩放图像,不仅会增加GPU kernel的启动和全局同步开销,而且当缩放图像过小而不能充分利用GPU的计算资源时,会导致GPU计算资源的极大浪费,由此会产生图像级负载不均衡。
为此,我们引入了Uberkernel机制,其核心是通过kernel合并,一次处理多幅甚至所有图像。这样仅通过一次或几次OpenCL kernel的启动就全部处理完所有的缩放图像。Uberkernel的具体流程如图7-6所示。
在GPU的Global Memory中设立一个统一地址空间,将所有图片按照缩放比例,顺序放入统一地址空间中。同时,OpenCL kernel将对这些缩放图片按照统一方式进行处理。当图片太大,统一地址空间不能全部容纳所有缩放图片时,则按照统一地址空间最大化利用的原则(尽可能填满统一地址空间)对缩放图片进行分组,然后循环处理每组图片。该机制尽可能地保证每个OpenCLkernel的工作量足以充分利用GPU所有的计算资源,很好地解决了图像级负载不均衡问题。
2.粗粒度并行与Persistent thread
在Uberkernel的线程组织及运行方式上,本书引入粗粒度并行与Persistent thread。
传统GPU编程是大规模细粒度并行,即一次开启大量线程,并以单个软件线程(thread)作为并行粒度。这种编程方式无疑是线程间存在负载不均衡特性算法的噩梦。为此,本书在Viola-Jones人脸检测算法的GPU实现中,采用硬件线程(NVIDIA GPU为warp,含32个thread,AMD GPU为wavefront,含64个thread)作为并行粒度,同时,硬件线程内多个thread协同工作,共同处理分配的检测窗口,其协同工作方式在5.本地队列中会详细讨论。粗粒度并行的实现方式较为简单:一个work-group只包含一个warp或者wavefront,work-group将作为全局队列任务分配的单位。
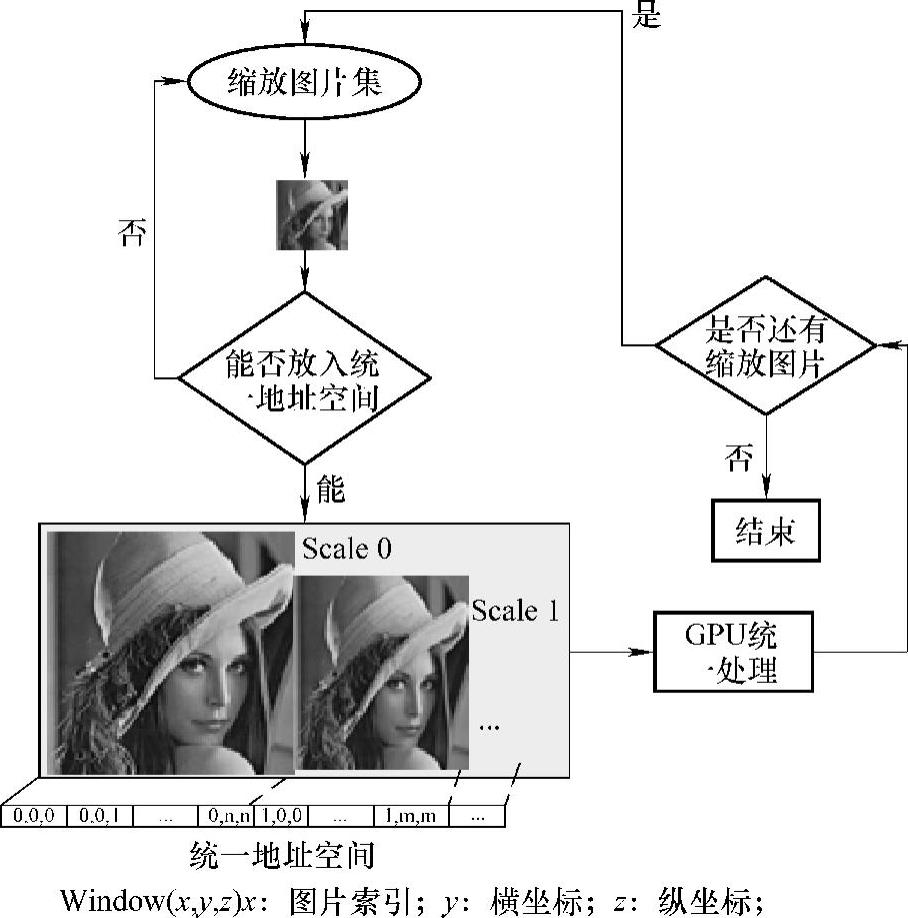
图7-6 Uberkernel的具体流程
采用粗粒度并行编程方式的优势主要有三个:
 移除本地同步操作。wavefront/warp是GPU最基本的执行和调度单元。当一个work-group内只包含一个wavefront/warp时,可移除本地同步操作,减少本地同步开销,在一定程度上提高程序性能。
移除本地同步操作。wavefront/warp是GPU最基本的执行和调度单元。当一个work-group内只包含一个wavefront/warp时,可移除本地同步操作,减少本地同步开销,在一定程度上提高程序性能。
 一个work-group只包含一个wavefront/warp,我们可以将work-group看成是一个与其他work-group执行相互独立的MIMD(Mutiple Instruction Multiple Data,多指令多数据)线程。即保证了SIMD执行方式的有效性,又提供了MIMD式的工作粒度。
一个work-group只包含一个wavefront/warp,我们可以将work-group看成是一个与其他work-group执行相互独立的MIMD(Mutiple Instruction Multiple Data,多指令多数据)线程。即保证了SIMD执行方式的有效性,又提供了MIMD式的工作粒度。
 减轻work-group内线程间的负载不均衡。在粗粒度并行模式下,任务的分配以work-group为单位,work-group内的所有线程协同处理所分配的计算任务。这种工作模式结合我们下面即将讨论的本地队列,可大大减小work-group内线程的负载不均衡现象。
减轻work-group内线程间的负载不均衡。在粗粒度并行模式下,任务的分配以work-group为单位,work-group内的所有线程协同处理所分配的计算任务。这种工作模式结合我们下面即将讨论的本地队列,可大大减小work-group内线程的负载不均衡现象。
当然,粗粒度编程方式也存在一个劣势:由于GPU硬件资源的限制,每个CU上同时运行的work-group数目是有限制的,因此,当work-group包含的线程数目较少时,可能会导致CU上同时运行的线程不足,从而不能有效隐藏访存延迟。幸运的是,由于人脸检测算法较大的计算密度,这个劣势可以消除。在实际实现中,结合数据本地化,为每个CU部署8~12个work-group,即可有效隐藏访存延迟。
在运行方式上,传统GPU线程的生命周期一般为五个过程:启动、获取操作数据、处理数据、写回处理结果、退出,其运行及调度方式都是静态且由GPU硬件控制。这种运行方式显然对于解决负载不均衡的问题是非常不利的。因此,本书引入的Persistent Thread,其生命周期和OpenCL kernel的生命周期相同,并可循环处理多个任务:线程在将一次数据处理的结果写回后,不是立即退出,而是判断是否还有别的任务需要处理。如果有,线程将继续获取任务进行处理,如没有才退出。这样在Viola-Jones人脸检测算法中,可为每个线程分配多个检测窗口,线程将循环处理这些检测窗口,直到将分配给它的窗口全部处理完毕。同时,线程与检测窗口的映射将根据线程的任务负载情况采用动态映射方式,从而最大限度地保证了线程间的负载均衡。这将在线程与任务的动态映射中进行详细讨论。
3.线程与任务的动态映射
在线程与任务的映射方面,传统GPU编程采用静态编程模式,即在GPU ker-nel启动之前,线程和任务的映射就已经确定,线程由GPU硬件顺序调度执行,每个线程处理的任务和任务数都是固定的。这种编程模式虽然很好地满足了规则的数据并行应用,但是,对于具有线程间负载不均衡特征的人脸检测算法,无法解决其存在的负载不均衡问题。本书在Persistent Thread的基础上,引入GPU动态编程模式,该模式具有以下四个特征:
 固定开启线程数目。根据目标GPU计算平台的CU数量,确定开启的线程数目。在人脸检测算法中,共开启8N(AMD GPU)或者12N(NVIDIA GPU)个work-group,其中N为CU数目。每个work-group包含64(AMD GPU)或32(NVIDIA GPU)个线程。
固定开启线程数目。根据目标GPU计算平台的CU数量,确定开启的线程数目。在人脸检测算法中,共开启8N(AMD GPU)或者12N(NVIDIA GPU)个work-group,其中N为CU数目。每个work-group包含64(AMD GPU)或32(NVIDIA GPU)个线程。
 每个线程分配多个计算任务。结合Persistent Thread编程方式,每个线程循环处理多个任务。
每个线程分配多个计算任务。结合Persistent Thread编程方式,每个线程循环处理多个任务。
 在线程的任务分配方面,在GPU kernel启动之后,根据线程的实际任务负载情况确定线程与任务的映射关系。
在线程的任务分配方面,在GPU kernel启动之后,根据线程的实际任务负载情况确定线程与任务的映射关系。
 该策略将作为全局队列的任务调度机制,根据粗粒度并行的定义,以work-group为单位进行任务分配。
该策略将作为全局队列的任务调度机制,根据粗粒度并行的定义,以work-group为单位进行任务分配。
图7-7显示了线程与任务动态映射的过程:首先每个work-group的第0号线程作为标记线程,访问位于全局内存上的原子变量G,在获得原子变量访问权后,对原子变量加N(N为work-group每次处理的窗口数目,在AMD GPU上N为64,在NVIDIA GPU上N为32);然后判断G是否小于检测窗口总数Total+N,如小于,则获取该work-group要处理的检测窗口,否则对应work-group退出;最后将待处理的N个检测窗口返回给对应的work-group。work-group以5.本地队列机制处理完这些检测窗口后,再重复以上操作,直到所有检测窗口都处理完毕为止。注意,所有检测窗口以队列形式存储在全局内存上,全局内存的构建组织方式将在4.详细讨论。图7-8为线程与任务动态映射的伪代码。(www.daowen.com)
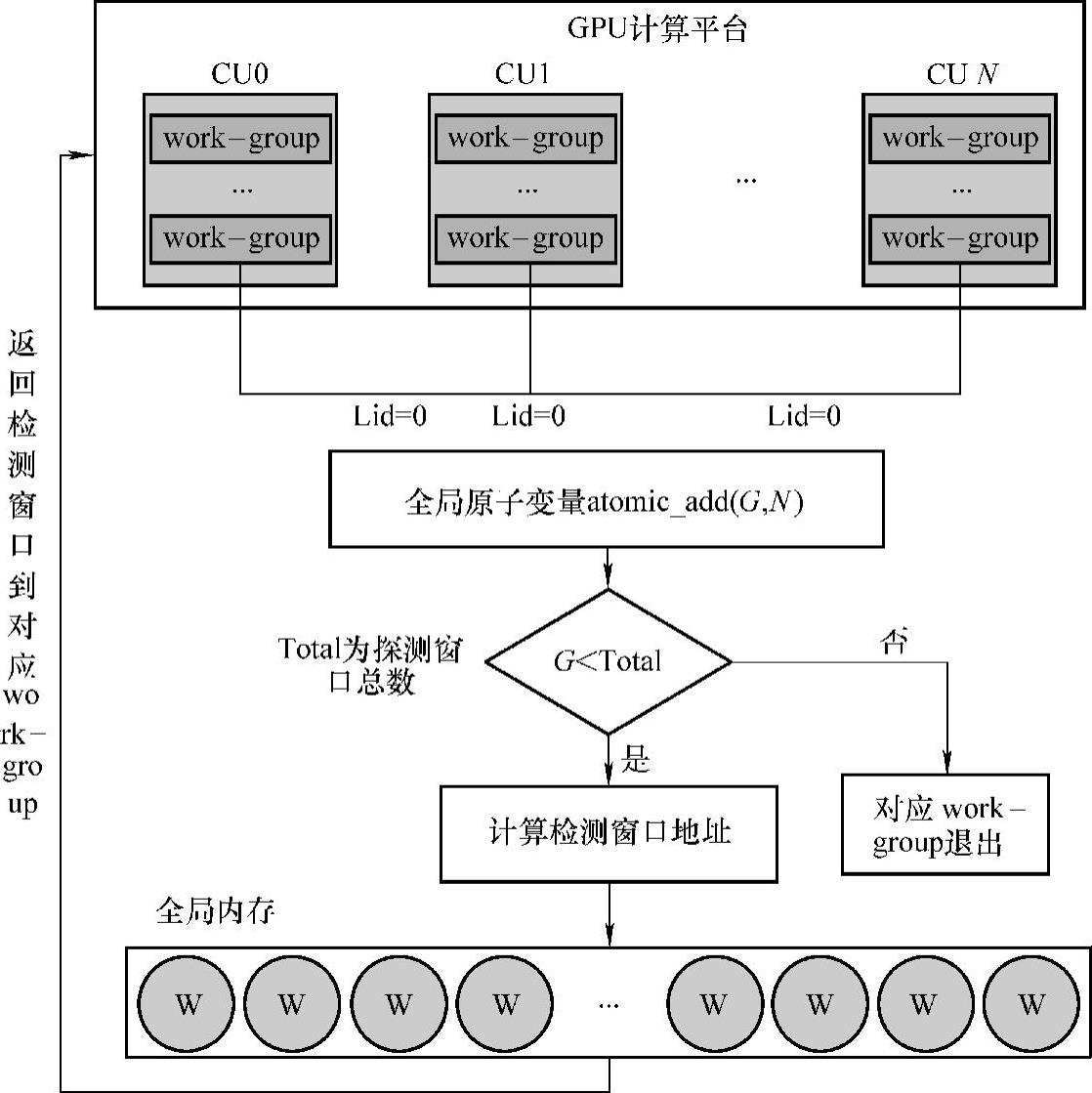
图7-7 线程与任务动态映射示意图

图7-8 动态映射伪代码
动态编程模式根据线程的实际任务负载情况进行任务分配,即当work-group处理的窗口包含人脸而导致计算量过大时,该work-group处理的窗口数目就会变少;反之,当work-group处理的窗口计算量小时,该work-group就会处理更多的窗口。因此,动态编程模式在一定程度上解决了work-group间负载不均衡的问题。
当然,动态编程模式会因原子变量访问导致额外的开销。但一方面,由于work-group的调度执行存在一定的时间间隔,所以这个开销会非常小;另一方面,相对于负载不均衡导致的性能瓶颈,这个开销几乎可以忽略不计。因此,动态编程方式会大幅提高人脸检测算法在GPU上的性能。
4.全局队列
线程与任务的动态映射机制能够很好地解决work-group间负载不均衡问题的前提是,位于全局内存上的待检测窗口必须被很好地组织,能够及时响应访存请求。因此,本书引入全局队列。
全局队列的作用是以队列的形式组织好待检测窗口,在线程与负载动态映射机制下,能方便地建立起线程与数据的动态映射关系。结合前面讨论的Uberkernel和Persistent Thread,全局任务队列的工作流程如下:首先将Uberkernel中所有的探测窗口都加入到该队列中;其次以32(NVIDA GPU)或者64(AMD GPU)为单位将探测窗口分成若干任务组,并将其作为任务调度单位;最后,根据线程与任务动态映射机制,以work-group为分配单元,根据线程的实际任务负载情况,完成任务的动态分配。
全局队列除任务与负载动态映射机制外,没有使用更加复杂的任务调度方式。这里有两方面的原因:一方面,全局队列位于全局内存上,其访存和原子操作的开销都非常昂贵。复杂的任务调度方式不仅难以实现,而且可能会产生昂贵的调度开销,在性能的提升上得不偿失。另一方面,线程与数据动态映射机制已经决定了全局任务队列的任务调度方式,且这种任务调度方式足够解决work-group间的负载不均衡现象。
5.本地队列
线程与任务的动态映射及全局队列机制的引入,较好地解决了work-group间负载不均衡的问题,而work-group内线程间负载不均衡的问题由位于片上本地内存(共享内存,NVIDIA GPU)的本地队列解决。
图7-9详细显示了本地队列及其任务处理过程。work-group将其负责处理的待检测窗口组织为位于片上本地内存的队列,然后使用级联分类器进行检测。每级分类器将会检测队列中的所有窗口,通过本级检测的窗口将会重新进入队列,等待下一级分类器的进一步检测;否则,该窗口将会被丢弃。其检测过程分为两个阶段:
 第一为单独处理阶段
第一为单独处理阶段
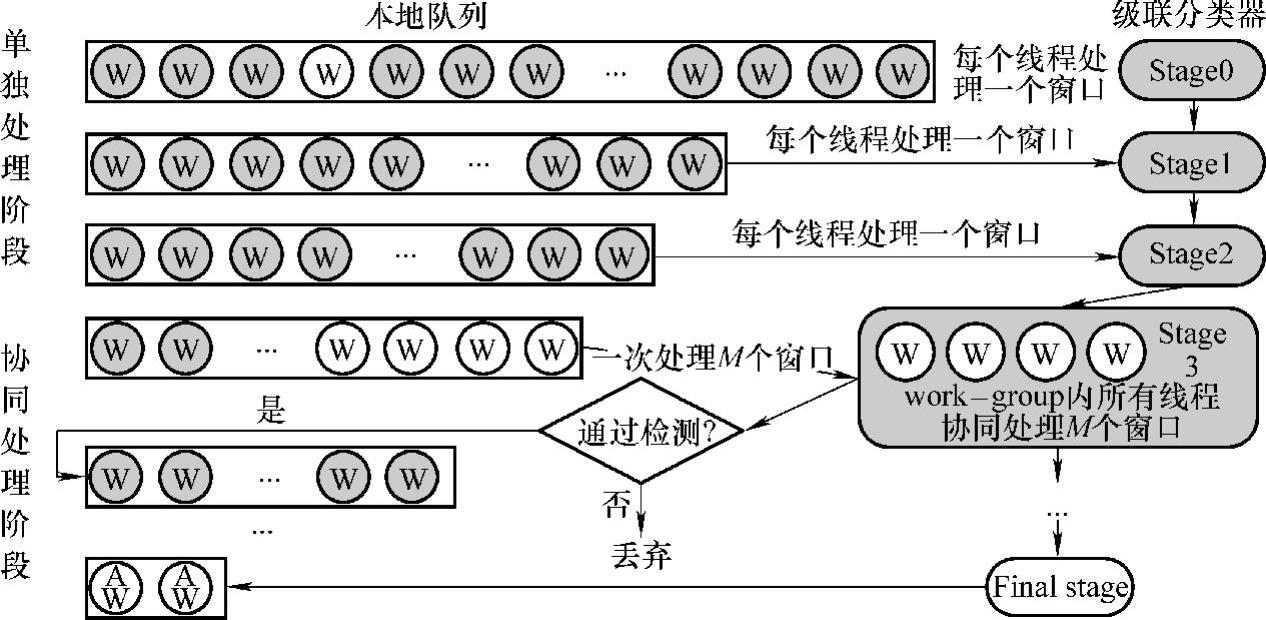
图7-9 本地队列
因为0~2级分类器特征数目较少,可以很快计算完成,故令每个线程单独负责处理一个窗口。在这个过程中,当使用1~2级分类器进行检测时,会有线程处于空闲状态,但这个时间太短,不足以引起性能瓶颈,反而会减少协同处理开销。
 第二为协同处理阶段
第二为协同处理阶段
随着分类器级数的增大,特征数目和计算量会急剧增长。同时,经过0~2级分类器的检测,队列中的待检测窗口数目也会减少。此时进入协同处理阶段。即一次从队列中取出M(在AMD GPU上M为4,Nvidia GPU上M为2)个检测窗口,由work-group内所有线程协同处理(通过检测的窗口返回队列),直到队列中的所有窗口都通过本级分类器检测为止;然后进入下一级分类器继续检测;最后只有经过最后一级分类器检测的检测窗口中才包含人脸。
由此可见,本地队列基本上解决了work-group内部线程间负载不均衡的问题。
6.其他优化方法
除以上优化方法外,Viola-Jones人脸检测算法还使用了GPU传统优化方法:
 开发ILP。开发ILP的主要有两种方式:一是循环展开;二是调整代码顺序,使相同指令类型(GPU的指令类型可分为三种:读内存指令、计算指令以及写内存指令。在执行过程中,GPU会将相互独立、相同类型且相邻的指令打包在一起并行执行)的代码打包在一起,编写对编译器友好的代码。
开发ILP。开发ILP的主要有两种方式:一是循环展开;二是调整代码顺序,使相同指令类型(GPU的指令类型可分为三种:读内存指令、计算指令以及写内存指令。在执行过程中,GPU会将相互独立、相同类型且相邻的指令打包在一起并行执行)的代码打包在一起,编写对编译器友好的代码。
 指令选择优化。因为人脸检测函数较高的计算密度,选择高吞吐量的指令对性能的提升就变得尤为重要。在改算法的实现中,共采取了两种指令优化:一是使用位运算指令代替乘法和除法指令;二是用mad24、MUl24指令代替乘加指令。
指令选择优化。因为人脸检测函数较高的计算密度,选择高吞吐量的指令对性能的提升就变得尤为重要。在改算法的实现中,共采取了两种指令优化:一是使用位运算指令代替乘法和除法指令;二是用mad24、MUl24指令代替乘加指令。
 减少动态指令。主要方法是减少条件分支。因为人脸检测算法中存在着大量的条件判断语句,因此使用?:语句代替if…else…语句是减少动态指令的主要方式。
减少动态指令。主要方法是减少条件分支。因为人脸检测算法中存在着大量的条件判断语句,因此使用?:语句代替if…else…语句是减少动态指令的主要方式。
7.性能移植优化
如前文所述,虽然GPU架构日益多样化,但是统一的层次式架构模式为性能移植提供了可能。只要完成关键性能参数的抽取,并建立完善的性能参数传递机制,就可实现不同GPU硬件平台间的性能移植。
两个GPU计算平台的关键性能参数抽取如表7-1所示。在性能参数传递机制构建方面,利用OpenCL程序运行时编译的特点,通过宏定义将性能参数在编译时传入OpenCL kernel,根据目标平台,传入相应的性能参数。根据以上方法,本书在不修改代码的前提下,最终实现了Viola-Jones人脸检测算法在AMD Radeon HD7970和NVIDIA GTX680两个不同GPU计算平台上的性能移植。
表7-1 不同GPU计算平台的关键性能参数

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






