Viola-Jones人脸检测算法在GPU计算平台上的Naïve版本采用最基本、最简单的并行化策略,即仅并行化检测窗口的检测,具体为:①每次只处理一幅缩放图像,在CPU端循环启动OpenCL kernel以处理所有的缩放图像;②对于每幅缩放图像,每个线程负责一个检测窗口,多个检测窗口可进行并行检测;③使用LDS完成数据本地化,实现work-group内线程的数据共享,减少对访存带宽的依赖;④在线程组织上,采取有多少检测窗口,就开启多少线程的策略,每个work-group大小为256,并采取二维组织形式:16×16。
然而,与CPU版本的性能相比,Naïve版本性能并没有提升,反而有所下降。这主要有两方面的原因:一是没有充分发掘并行性,Naïve版本仅仅开发了三级并行性中的一级,即检测窗口并行;二是在Naïve实现版本中,线程间存在严重的负载不均衡现象,这是GPU这种大规模细粒度并行处理器的梦魇。这使得GPU计算资源远未得到充分利用,从而导致性能的严重降低。其中第二个原因是最主要、最关键的因素。
Viola-Jones人脸检测算法的串行实现中,级联分类器之所以能够提高检测速度,是因为在一般的输入图像中,大部分区域都不包含人脸。通过前面的几级简单分类器可直接滤去这些区域,只对少量的极可能包含人脸的区域使用更为复杂的分类器进行检测。在这个检测过程中,随着弱分类器数量的增加,通过Adaboost构建的强分类器的检测表现也会不断提高。但这种方法也导致了该算法在GPU的实现和优化中,会导致严重的负载不均衡现象,大大限制了其在GPU上的性能。图7-4说明了这种负载不均衡现象的产生过程。
如图7-4所示,假设有9个检测窗口,共开启9个线程,每个线程负责一个窗口的检测。当使用级联分类器进行检测时:窗口(0,0)首先被Stage0分类器检测为肯定不是人脸而被丢弃,在此后的检测过程中,线程(0,0)将一直处于空闲状态,其他线程继续工作;接着在下一级检测中,窗口(1,1)被stage1分类器也检测为不是人脸,因此线程(1,1)在随后的检测中,也将处于空闲状态;更为不幸的是,随着检测的进行,越来越多的窗口被检测为不是人脸而被丢弃,也就是说越来越多的线程处于空闲状态;直到最后一个阶段,只有线程(1,2)处于忙碌状态,而其他线程都处于空闲状态。更为严重的是,根据级联分类器的定义,检测越靠后,分类器级数越高,相对应的计算量就越大。因此,实际的负载不均衡现象远比图7-4描述的严重得多。
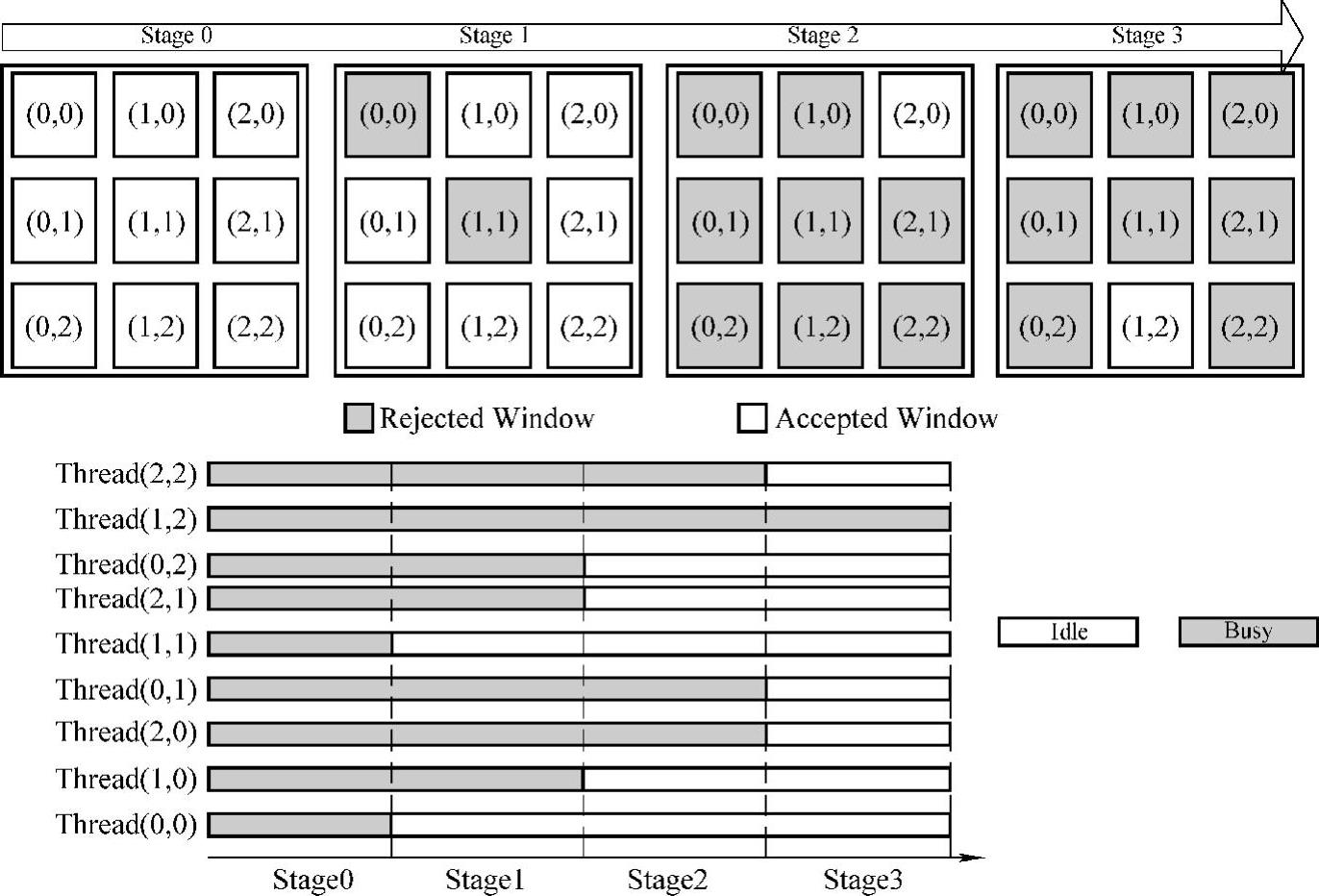
图7-4 线程间负载不均衡现象
由此可见,虽然级联分类器方法在串行算法中可大大减少工作量,提高检测速度。但在GPU实现中却会导致严重的线程间负载不均衡现象,成为性能瓶颈,严重制约算法性能。特别是在大多数图像中,人脸区域可能只占很少一部分。如果对该算法的GPU实现不进行改进,这也就意味着在实际GPU程序中,只有一小部分线程会一直处于工作状态,直到检测结束。而绝大部分线程可能很快就退出并在CPU端等待全局同步了。这显然是我们不愿意看到的结果。(www.daowen.com)
此外,为了检测图像中大小不同的人脸,需要将图像按照一定的缩放因子进行放缩。Naïve实现在CPU端循环处理这些缩放图像。这样处理不仅增加了GPU kernel的启动和同步开销,而且当缩放图像过小时(如只有几个甚至一个检测窗口时)而不能充分利用GPU的计算资源时,就不能充分利用GPU强大的计算能力,造成资源浪费。
因此,在实际图片的人脸检测中,Viola-Jones人脸检测算法存在三级负载不均衡:
 thread级。线程负责的检测窗口中的图像越接近于人脸,该线程的工作量越大;否则,工作量越小。
thread级。线程负责的检测窗口中的图像越接近于人脸,该线程的工作量越大;否则,工作量越小。
 work-group级。当一个work-group处理的图像区域包含人脸时,工作量巨大;否则,工作量可能会很小。
work-group级。当一个work-group处理的图像区域包含人脸时,工作量巨大;否则,工作量可能会很小。
 图像级。当图像不断放缩而不能充分利用GPU计算资源时,就会导致图像级的负载不均衡。
图像级。当图像不断放缩而不能充分利用GPU计算资源时,就会导致图像级的负载不均衡。
本书下面的内容将着重讨论如何解决这些负载不均衡的问题。幸运的是,在解决负载不均衡问题的同时,并行性没有充分发掘的问题也一并得到了解决。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





