不包括灰度化和滤波的情况下,如图6-12(见彩插)所示,OpenCV_CPU_Canny耗时412.9375ms,同时Open_CVCUDA_Canny也耗时256.3164ms,而本文所移植与优化后的My_CUDA_Canny仅仅耗时34.7043ms,相对于OpenCV_CPU_Canny实现了11.8987倍的性能加速比。这充分体现了该异构平台GPU的并行计算的优势,尤其是大规模并行处理。然而OpenCV_CUDA_Canny性能较低,其主要原因在于:它选择了texture memory,该内存主要适用于对大量数据的随机访问和非对齐访问。但是global memory性能提升空间相对更大,若合理使用global memory可以实现合并访问,有效提高算法性能,例如6.4.1小节中的cache line机制。
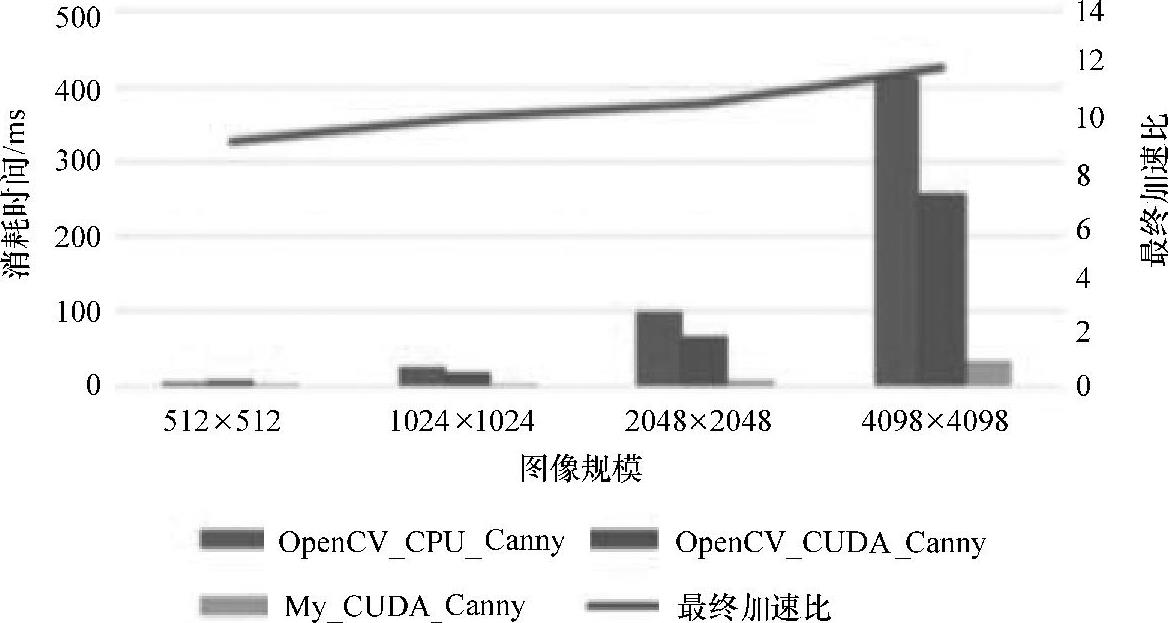
图6-12 CPU与GPU版本Canny算子性能对比图
对于整个Canny边缘检测算法,如图6-13所示,对于整个边缘检测算法,在512×512图像数据规模下实现了13.2倍的性能加速比。在4096×4096图像数据规模下My_CUDA_DetectedEdge仅仅耗时49.9948ms,而OpenCV_CPU_Detected-Edge耗时890.7573ms,My_CUDA_DetectedEdge相对于OpenCV_CPU_Detected-Edge实现了17.8169倍的性能加速比。
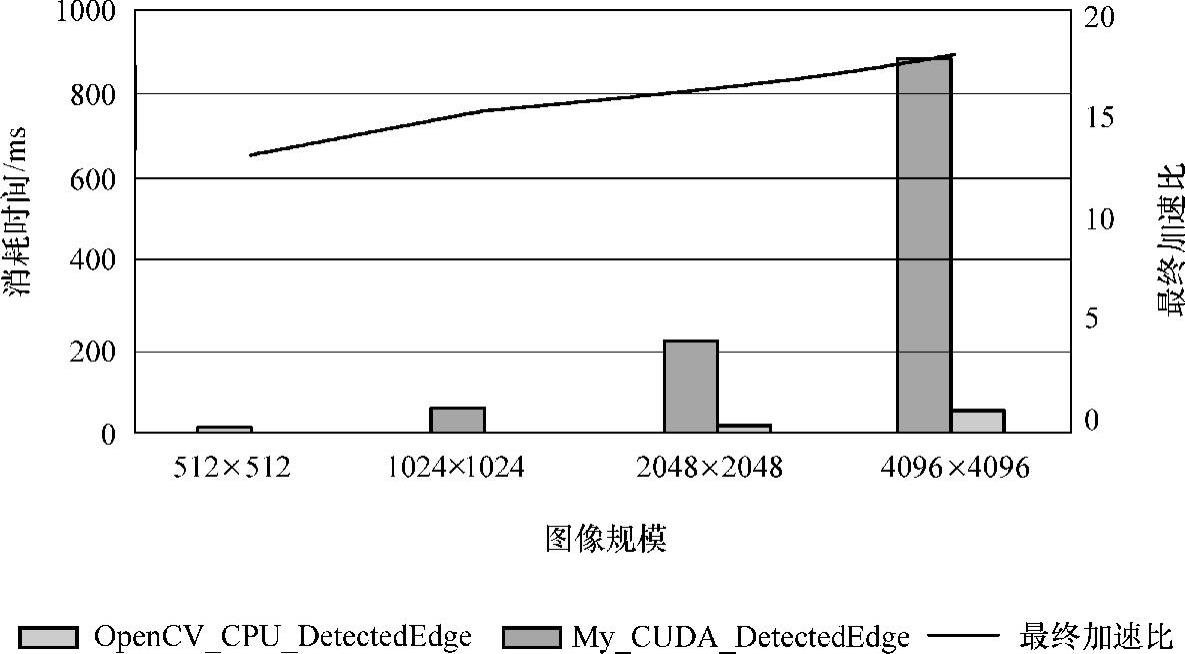
图6-13 CPU与GPU版本Canny边缘检测性能对比图(https://www.daowen.com)
通过在NVIDIA Tegra K1异构计算平台上的移植与精细调优,相对于OpenCV_CPU_Canny实现了13.2~17.8倍的性能加速比,最终实现了高性能的Canny边缘检测算法。512×125数据规模图像的边缘检测效果如图6-14(见彩插)所示。
从整个边缘检测算法的异构计算平台移植与精细调优可以看出,随着图像数据规模增大,性能普遍都有所增加。这符合GPU并行计算的特点。因此,GPU适合大规模数据的并行处理。

图6-14 高性能Canny边缘检测效果图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。


