从上一节分析可以看出,数据本地化与向量化对算法的访存优化有很大提升。在blur算法优化中,也采用数据本地化与向量化进行优化。上一节已经做了详尽的阐述,这里不再累赘。
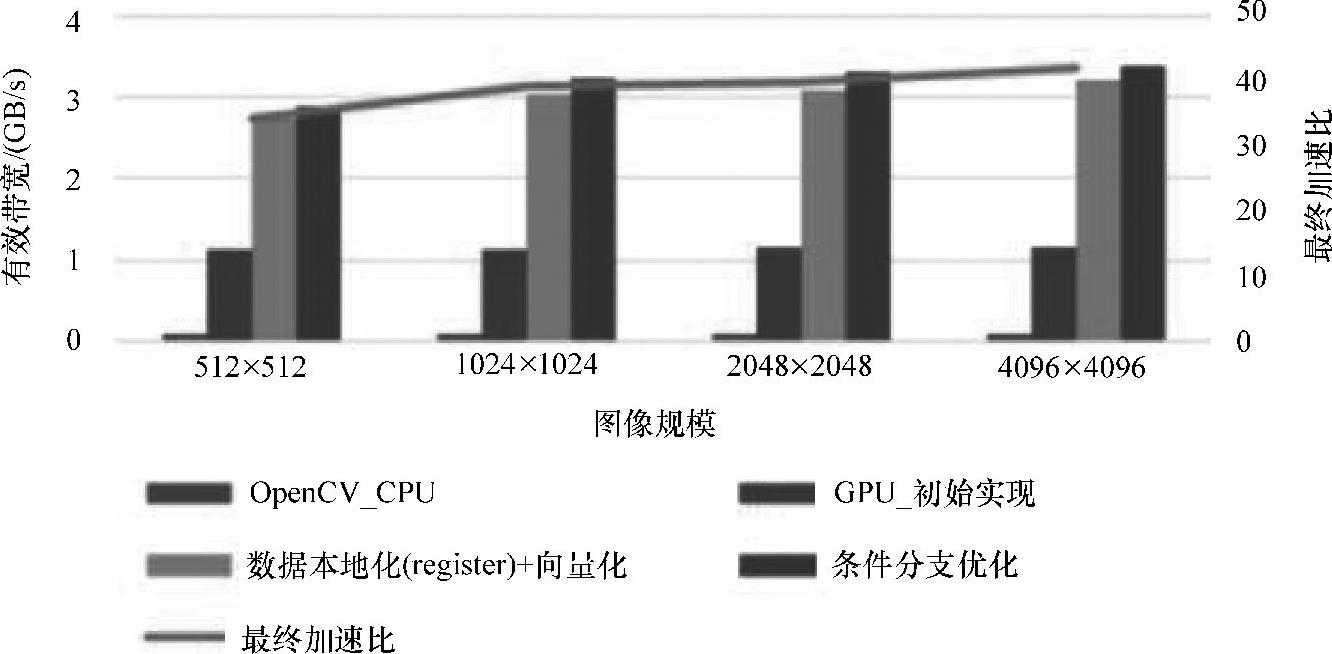
如图6-8(见彩插)所示,在使用向量化后有效带宽为3.1964GB/s。但有效带宽并没有像灰度化算法一样大幅度提升。主要原因有三点:
 在滤波算法中,由于计算某点时需要读取相邻点的值,这导致一个warp访存的数据大小不是cache line的整数倍。
在滤波算法中,由于计算某点时需要读取相邻点的值,这导致一个warp访存的数据大小不是cache line的整数倍。
 由于图像边界的处理,出现条件分支,导致不同的执行路径的指令会被串行化,从而导致性能下降。
由于图像边界的处理,出现条件分支,导致不同的执行路径的指令会被串行化,从而导致性能下降。
 由于除数而产生了精度差,为了和OpenCV的blur()函数的结果完全一致,添加浮点运算以提高精度,同时产生大量浮点运算,从而使性能有所下降,实测下降大约1.1GB/s。
由于除数而产生了精度差,为了和OpenCV的blur()函数的结果完全一致,添加浮点运算以提高精度,同时产生大量浮点运算,从而使性能有所下降,实测下降大约1.1GB/s。
如6.4.3小节所述,可以通过指令?:对条件分支进行替换,可以实现条件分支优化。最终,有效带宽最高达3.3917GB/s,相对于CPU实现了42.0285倍的性能加速比。
 (https://www.daowen.com)
(https://www.daowen.com)
图6-8 blur算法性能图
在6.3节中,提到在Canny算子中,计算梯度幅值算法的本质也是一种滤波算法,即Sobel滤波器,只不过在经过x方向和y方向上的求导(两次滤波)之后做相加运算。那么计算梯度值算法的优化策略与blur算法优化策略一样。优化后,如图6-9所示,有效带宽达到了6.6863GB/s,相对于GPU初始实现了2.0279倍的性能加速比。同样,这里的有效带宽无论是优化前还是优化后都明显高于前面的blur算法。其主要原因有两点:
 相对而言,计算梯度值算法的计算量远大于blur算法,这充分利用了GPU适合计算密集型任务的特点。
相对而言,计算梯度值算法的计算量远大于blur算法,这充分利用了GPU适合计算密集型任务的特点。
 访存密度同样大于blur算法,向量化与数据本地化对于性能的提升十分明显。因此,可以实现更好的性能。
访存密度同样大于blur算法,向量化与数据本地化对于性能的提升十分明显。因此,可以实现更好的性能。
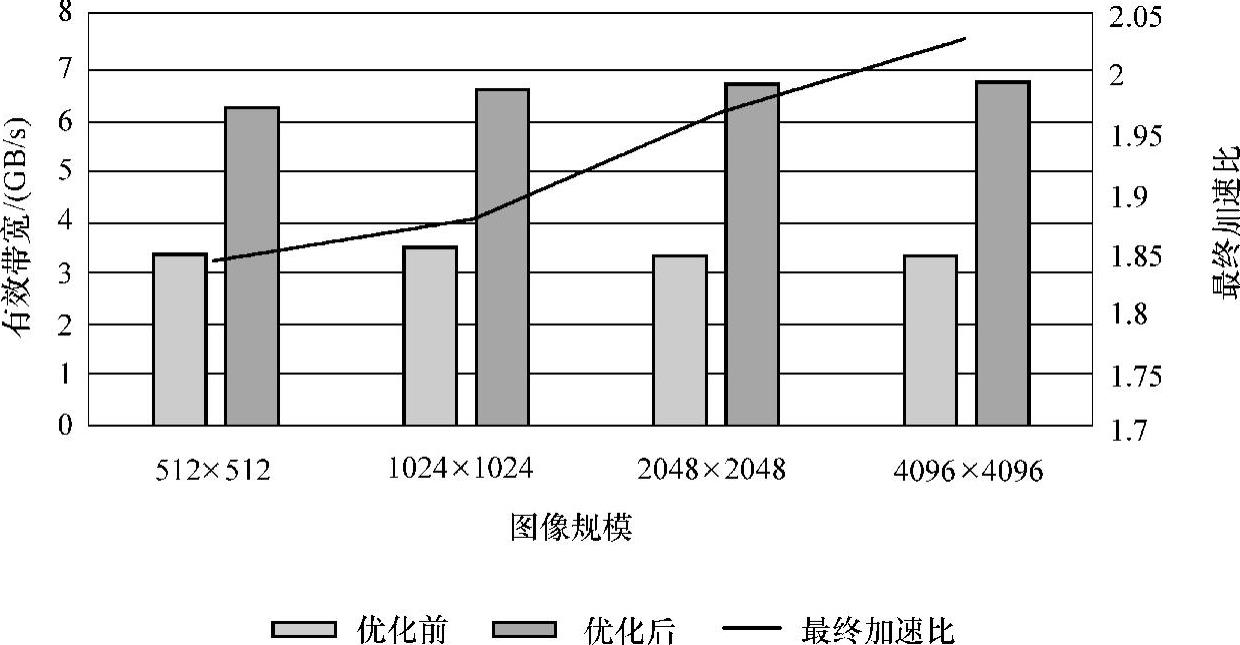
图6-9 计算梯度算法性能图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





