由6.4.1节可以看出,在Canny算法中,数据与数据间不存在依赖关系。即该算法具有很高的可并行性,通过开启大量线程,尽量发挥硬件的计算能力,以减少延迟或提高吞吐量。
1.灰度化算法
GPU并行过程中,以CV_8UC3类型M×N大小的图像为例,需要开启M×N个线程,每一个线程处理源图像每个像素点的3个通道的B、G、R,即3个数据,计算出该点的灰度值,并存入目标图像(CV_8UC1)。该初始版本,访存有效带宽仅4.0901GB/s。这种基本实现算法的优点在于易理解,易实现。但是这种算法的性能十分不理想,主要原因在于global memory访存效率不高。
2.滤波与计算梯度及极大值抑制
计算梯度值算法的本质也是一种滤波算法,与blur函数一样是将图像与3×3的内核进行卷积操作,只不过计算梯度值算法还需要将两次卷积进行加运算。非极大值抑制与滤波算法访存类似,读取9个数据进行处理。即三者的访存类型是完全一样的。所以,在这里我们把计算梯度值、blur函数和非极大值抑制的并行移植与实现放在一起解析。
由上文的阐述可知,处理M×N大小的图像需要开启M×N个线程,每一个线程计算一个像素点,同时根据给定的边界类型处理图像的边界。
对于这两类算法也存在global memory访存效率低的问题。同时,计算相邻两个点时会重复读取6个数据(事实上极大值抑制算法数据重用度并不高),极大地增加了对global memory的访存次数与开销。但非极大值抑制算法,由于边界处理或判断,产生大量的分支,分支将会导致执行路径串行执行,条件语句的执行总时间等于各个分支执行时间的总和。同时,极大值抑制算法几乎没有计算,全为判断分支,这为优化增加了很大的难度。
3.递归确定边缘(https://www.daowen.com)
NVIDIA TK1搭载的Kepler架构的GPU是不支持递归算法的。因此,需要改写算法,改写为一个适用于GPU的算法。改写后的算法流程图及部分代码如图6-5所示。
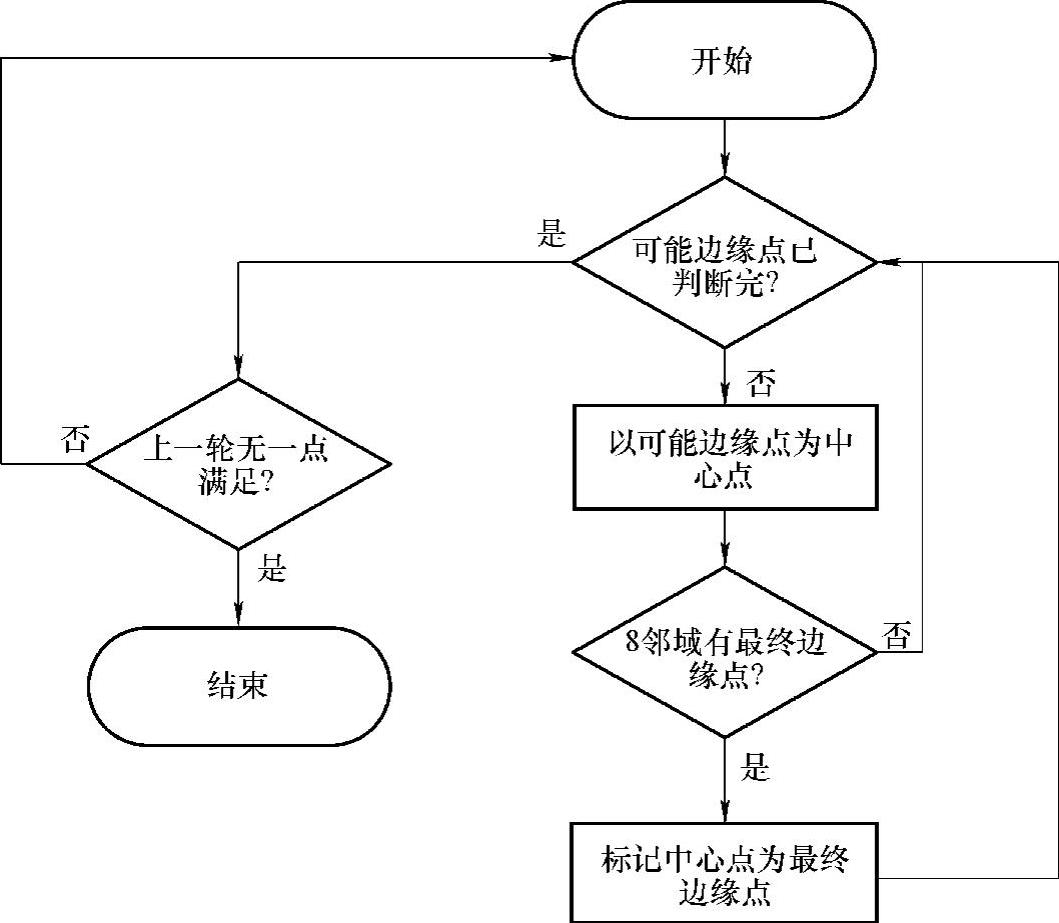
图6-5 递归确定边缘改写后流程图
部分代码:

由代码可知,通过循环每次判断全部图像的kernel实现原来递归算法的功能。从开启的线程来讲,依旧是一个线程处理一个像素点,判断相邻两个点时会重复读取6个数据,极大地增加了对global memory的访存次数与开销。同时,该算法每次的循环中,大量的分支导致不同的像素点可能会有不同的任务,极大地增加了算法的执行时间。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






