本小节实验运行的GPU为Nvidia Tesla K20M,处理时钟706MHz,CUDA core2496个,warp大小为32。
5.5.2小节的CPU端的最近邻插值resize算法与GPU端的最近邻插值resize算法在channel=1和channel=3进行性能对比,其实验结果如图5-28所示,resize算法相对于串行resize算法在channel=1和channel=3加速比分别为34.60和35.26。
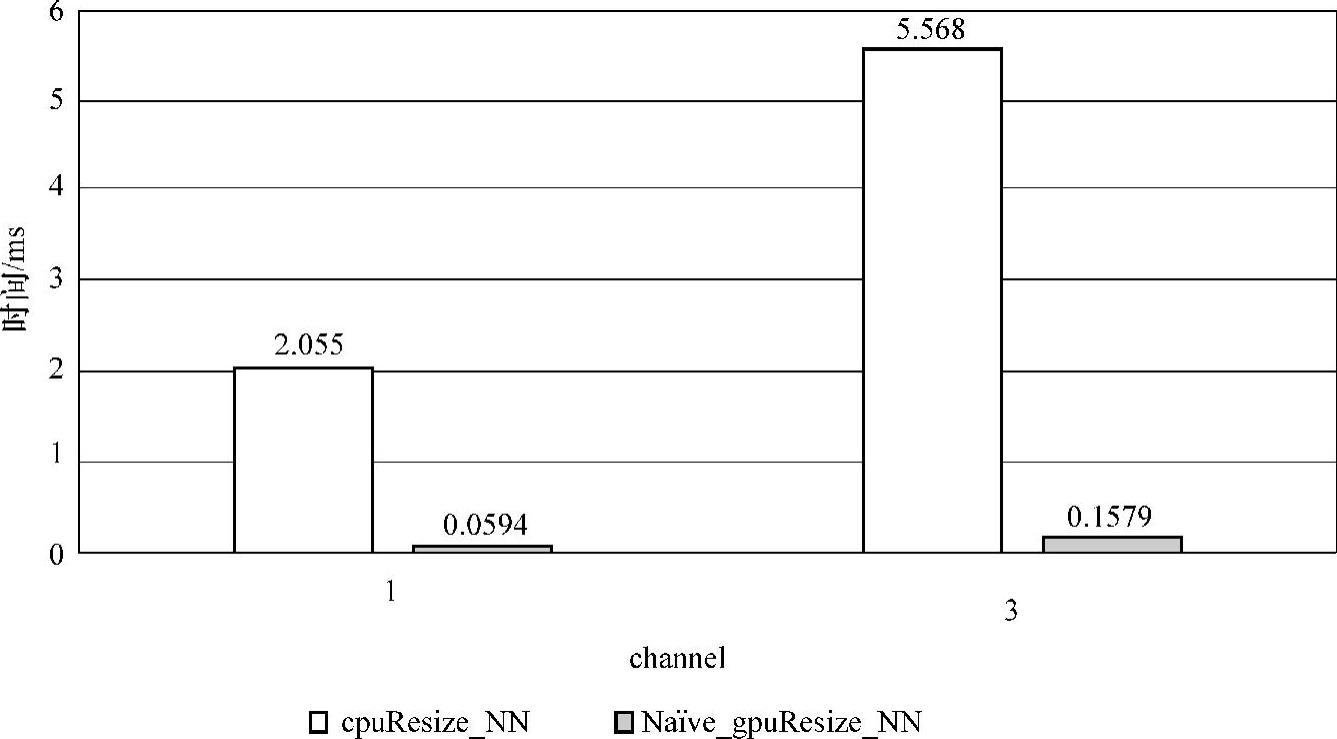
图5-28 最近邻插值resize算法对比
5.5.2小节的CPU端的双线性插值resize算法与GPU端的双线性resize算法在channel=1和channel=3进行性能对比,其实验结果如图5-29所示,resize算法相对于串行resize算法在channel=1和channel=3加速比分别为36.25和31.35。
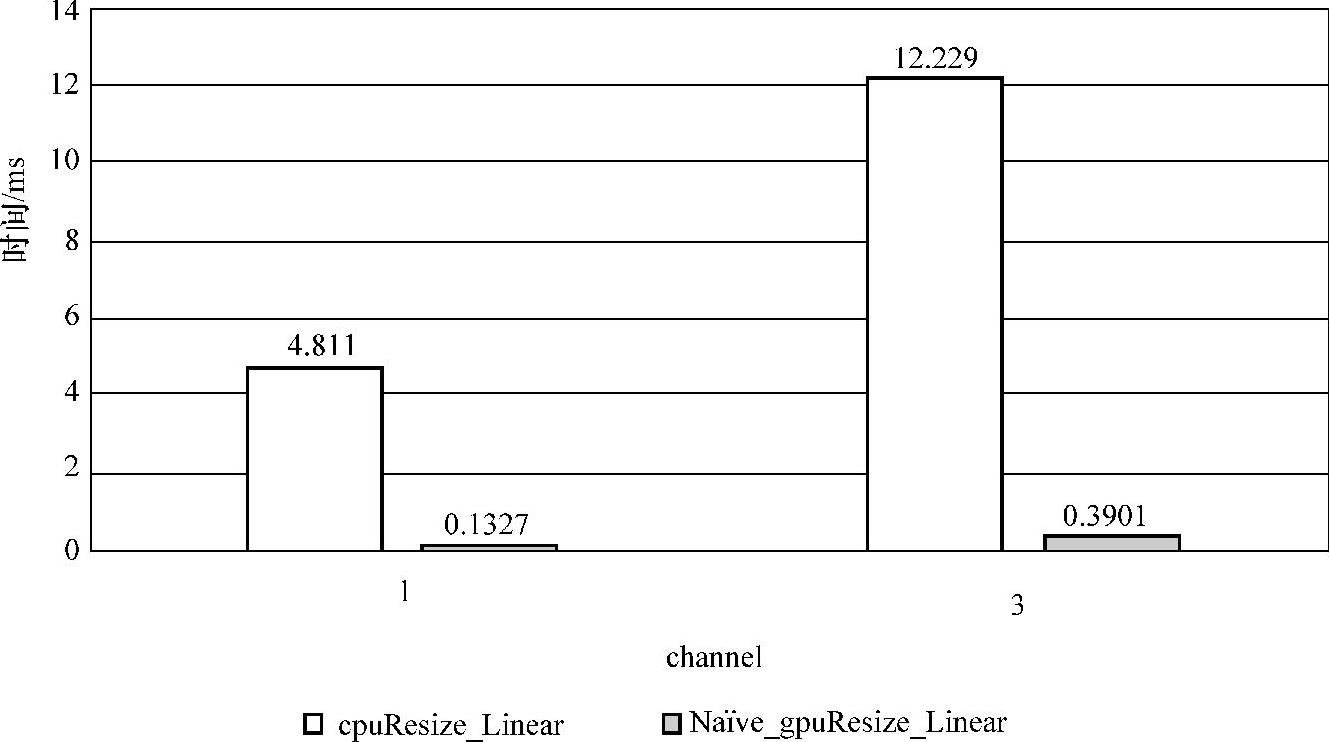
图5-29 双线性插值resize算法对比
通过对512×512的源图像进行各种resize算法,通过把目标图像放大为(512×times)×(512×times)的规模,其中times=1、2、4。
通道1的情况各resize算法效果如图5-30(见彩插)所示。可以看出在不同的数据规模下,Vectorize_gpuResize_Linear版本均有良好的效果,而CoalescedWrite_gpuResize_Linear版本和CoalescedRead_gpuResize_Linear版本均不及Vectorize_gpuResize_Linear。下面给出分析的原因,对于CoalescedWrite_gpuResize_Linear而言,在通道1下单元数据只有1个,对global memory的操作为合并写入操作,但对Vectorize_gpuResize_Linear而言同样是合并写入,只有当单元数据大于1时,连续线程访问的数据才产生跳跃,因此在通道1的情况下,CoalescedWrite_gpuRe-size_Linear版本存在多余的对share memory的操作,因此性能下降。对于Coa-lescedRead_gpuResize_Linear而言,由于单元数据为1,因此对share memory的利用率不高,虽然其性能相比于基础实现已经能有较大提升,但相对于Vectorize_gpuResize_Linear版本而言,其对share memory操作所带来的延迟可能更严重。(https://www.daowen.com)
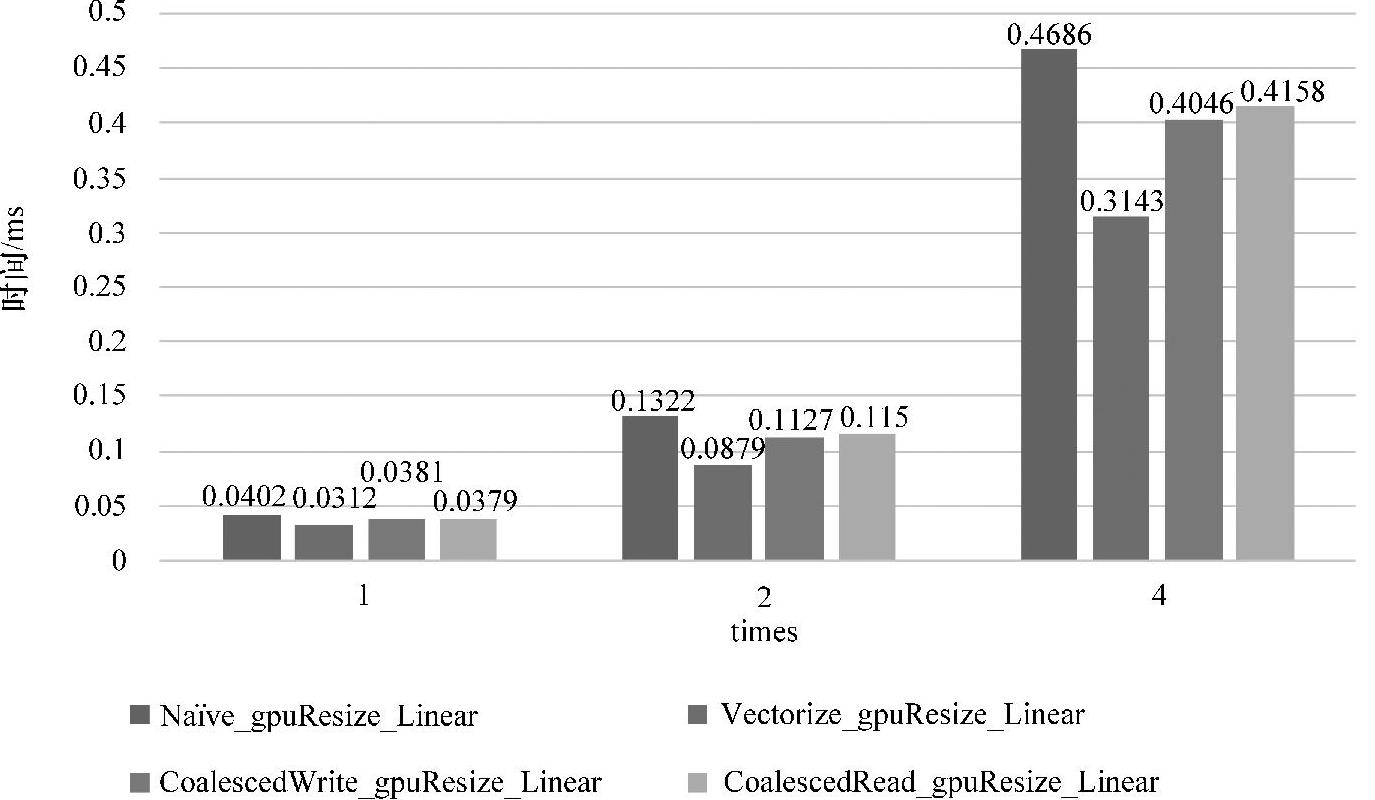
图5-30 通道1下resize算法性能对比
像素点的通道数为3的实验结果如图5-31(见彩插)所示,可以清晰看出,CoalescedRead_gpuResize_Linear版本在单元数据大于1情况下,其访存方式的优势开始显现,由于一个像素存在3个单元数据,其他版本实现导致相邻线程需要跨址对global memory进行访问,因此导致性能下降,而CoalescedRead_gpuResize_Linear版本通过把多次对global memory的非合并访存转化为对share memory的访问,而在share memory上是不要求对访问进行合并的,从而降低了访存延迟,提升了算法性能。
依据5.3.1小节分析,Vectorize_gpuResize_Linear通过适当地改变线程-数据的映射关系,增加线程的运算量,以提升开启线程的利用率,由图5-30及图5-31可知,适当的向量化强度能够提升resize算法的效率,尤其在通道1的情况下,因为通道1只含有1个单元数据,在适当数据规模下,虽然存在对globalmem-ory的非合并读入操作,但其带来的性能影响可能与CoalescedWrite_gpuResize_Linear版本中对增加的share memory的操作产生抵消作用,此外,对global memory的写入操作,由于不需要跨址操作,符合合并访问,因此性能得到提升。
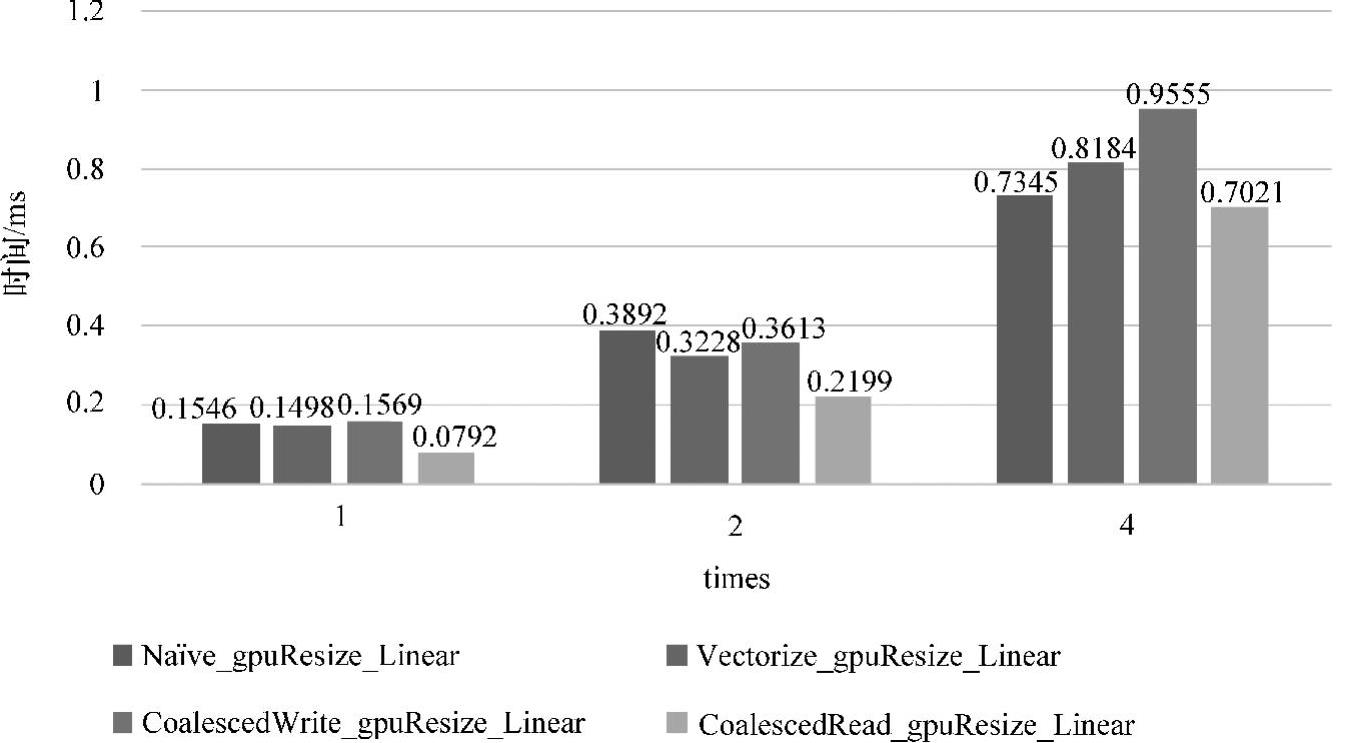
图5-31 通道3下resize算法性能对比
依据5.5.3小节分析,CoalescedWrite_gpuResize_Linear版本通过引入share memory以消除算法最后对global memory的非合并写入方式,但性能却没有得到预想中的提升。如图5-30及图5-31所示。部分原因如前面分析所示,即使在通道3的情况下,相邻线程对global memory的写入需要跨越3个单元数据进行访问,但因为三个操作代码是连续写入,极有可能编译器进行了合并写入优化,这是不可预知的。另一个原因在于由于跨址长度只为3个单元数据宽度,而不是更长,而算法版本中增加了对share memory的写入和读取操作,可能一定程度上带来了性能的下降,但CoalescedWrite_gpuResize_Linear版本仍然优于基础实现。
依据5.5.3小节和图5-31可知,在数据规模大、通道数为3的情况下,基于Vectorize_gpuResize_Linear基础上进行优化的CoalescedRead_gpuResize_Linear版本拥有相较于其他resize版本更好的优势。对于每个像素点含有数据单元为3的图像,每一次进行reszie算法运算时,只需要进行一次的运算过程就可以确立三个数据单元的位置,其效率无疑高于通道1的情况,而且由于block所需源图像的信息已经拷贝至share memory,数据量越多,则对share memory的利用率越高,更有效地降低了Vectorize_gpuResize_Linear中对global memory的不规则访问所带来的性能下降。依据图5-29和图5-31,在源图像为512×512,目标图像为1024×1024的数据规模下,CoalescedRead_gpuResize_LinearResize算法版本的运行时间为0.2199ms,相较于串行resize算法12.299ms的运行时间,其加速比达55.61。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





