本节实验运行的GPU为NVIDIA Tegra K1,处理时钟852MHz,CUDA Core192个,warp大小为32。
从下面的性能图中我们可以得出,经过GPU的优化后,矩阵转置程序的性能得到了较为明显的提升,其中除了512个×512个的数据规模以外,消除bank冲突对算法性能提升最大。
从图5-12中我们发现数据规模为2048个×2048个时,出现了优化后反而效率降低的现象。原因是share memory中共有32个bank,block的线程组织为16×16,所以并没有很好地消除bank冲突。线程块大小,为32×8的性能图如图5-13(见彩插)所示。
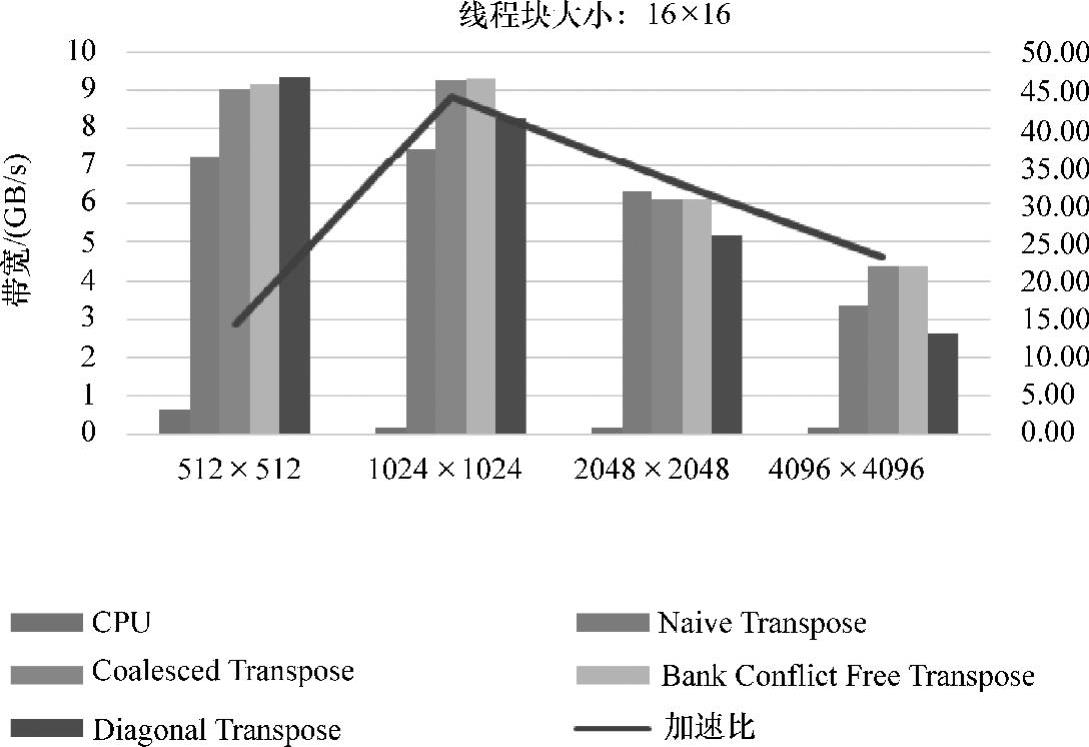
图5-12 线程块大小为16×16的性能图
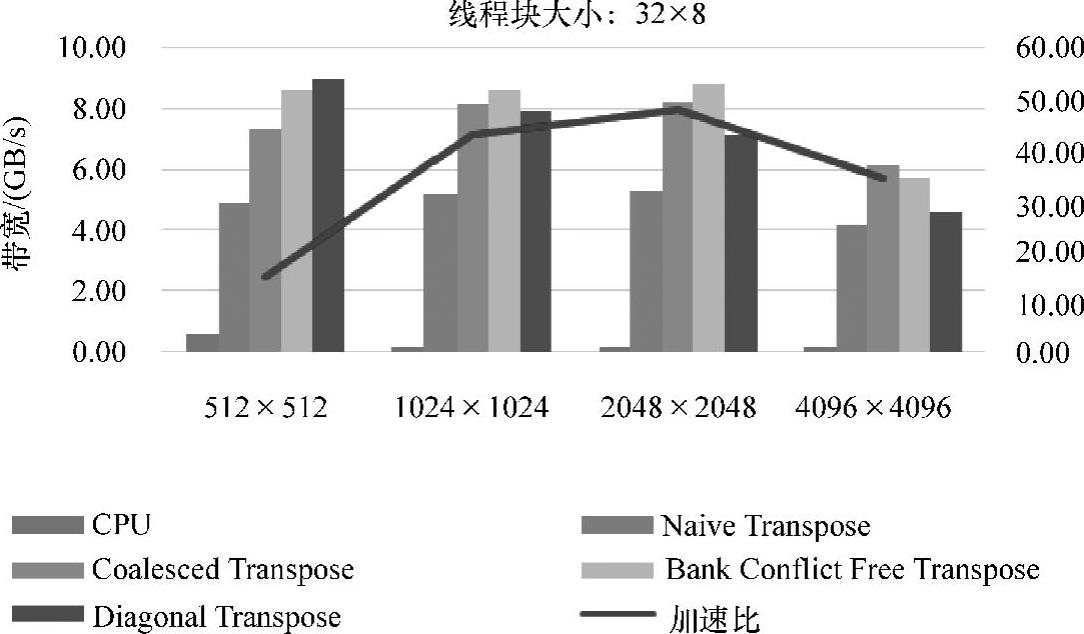
图5-13 线程块大小为32×8的性能图
当block为16×16时,对于global memory的合并访问的优化是比较明显的。但是,对shared memory的bank冲突的优化并不理想,甚至性能还有所降低。在Greg Ruetsch等人编写的《Optimizing Matrix Transposein CUDA》中,在针对K20X(Kepler)shared memory的bank冲突的优化的时候性能同样有所降低,具体如图5-14(见彩插)所示(数据规格2048×2048,block为32×32)。性能下降有很大部分的原因在于NVIDIA公司已经对TK1的shared memory的cache优化足够好,以至于bank冲突的延迟并不明显,而bank冲突的优化加入增加一部分的计算量,最终导致性能略微下降。(www.daowen.com)
相对而言,block为32×32时shared memory的bank冲突的优化是比较明显的。优化后的最高带宽为7.11GB/s。
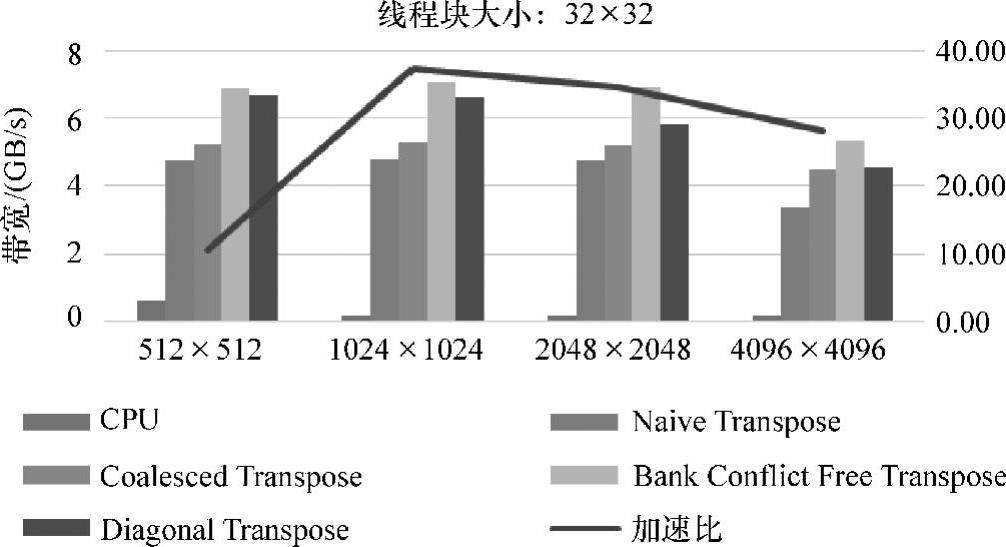
图5-14 线程块大小为32×32的性能图
为了看出不同情况下,矩阵转置并行算法的优化效果。用平均数据算出相对于CPU的加速比,如图5-12~图5-14(见彩插)所示。
从这三幅图可以看出,block大小为16×16的最优加速效果高于block大小为32×32的加速效果。最高加速比达到44倍。这时的数据规模也是1024×1024,block大小为16×16。总体来讲,数据规模为1024×1024,block大小为16×16时,在该平台上的加速最优。
从图中也可以发现,解决channel conflict的问题并没有对算法的提升带来明显的优化,甚至会由于索引坐标的计算而导致计算数据量增大从而降低了效率。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







