在GPU程序中,每个计算数据都需要输入和输出两次地址空间的计算,每次地址空间的计算需要4次浮点数计算。优化程序的关键就在于如何提高访存带宽的利用率。
本节将会以并行矩阵转置算法为例,以Naïve Transpose为起点,逐步地探求并行矩阵转置算法的优化策略,以追求Copy-Data Kernel的高性能。
1.global memory合并访问
从5.3.2小节可知,Naïve Transpose相较于Copy-Data Kernel,其主要不同之处在于线程把数据写入转置矩阵(结果矩阵)位置的不同,Naïve Transpose以行顺序读取原矩阵的元素,再以列顺序写入转置矩阵,而Copy-DataKernel以行顺序读取原矩阵的元素,再以行顺序写入转置矩阵。两个过程的操作对象均为global memory。从分析可知,线程对global memory的读写访问方式极大地影响着对global memory存储带宽的有效利用。
Naïve Transpose算法效率较差的很大原因在于写入数据时是写入转置矩阵中的一列,因为数据的局部性,保证连续线程对访问连续的global memory地址十分重要。从图5-4和图5-5的线程执行过程可知,Naïve Transpose和Copy-Data Kernel在对global memory的读操作均符合合并访问条件。而Naïve Transpose在global memory空间的写操作中,是按列进行写入的,不符合合并访问条件。
为了避免对global memory的非合并访问,可利用shared memory作为中转,通过计算数据索引的映射关系,实现对global memory读出写入操作的合并访问,从而提升算法性能。按以上分析,提出Coalesced Transpose并行矩阵转置算法,其转置过程如图5-7所示。
Coalesced Transpose并行矩阵转置算法为了能够完成对global memory的合并读写,需要线程将原矩阵元素加载至shared memory,此处使用了大小为32×32的block,每一个block负责的32×32大小的数据块转置,block内的线程将原矩阵的数据读入到shared memory当中,此过程对global memory为合并读入操作,如图5-7所示。shared memory为片上内存,其读写速度高于global memory的读写速度,shared memory不需担心出现如global memory般的非合并访问问题。因此shared memory作为中间内存完成对目标转置矩阵的合并写入,能够有效地避免对global memory非合并访问带来的性能下降。在Coalesced Transpose转置过程中,每一个block的线程利用所属的ID对转置后的元素位置索引进行映射计算,从而实现合并写操作。
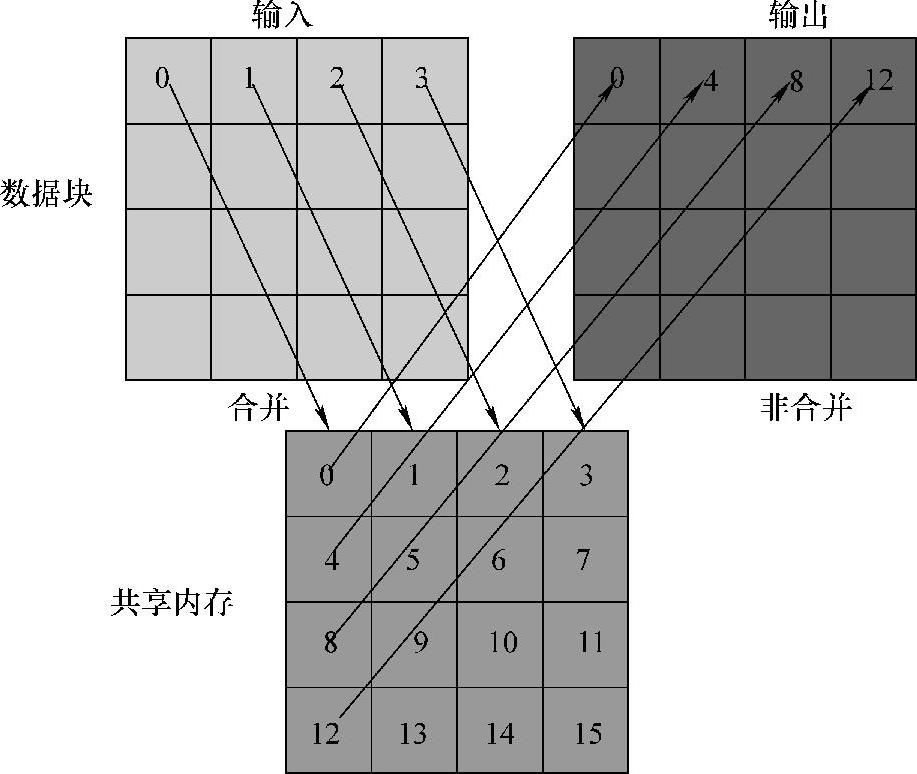
图5-7 Coalesced Transpose合并访问global memory
2.Shared Memory Bank-Conflict-Free
Coalesced Transpose算法虽然相较于Naïve Transpose性能得到提升,然而距Copy-Data Kernel的性能仍有不少距离。上部分分析了global memory的合并访问优化能够带来性能的提升,本部分将对本地内存(shared memory)的访存方式进行分析,以进一步提升算法性能。
如果在一个block中有多个线程同时访问同一个bank,访问操作将被按序列号即串行执行,这种情况称为存储体冲突(bank conflict),如图所示。bank coflict的产生意味着访问操作的串行化,严重影响对sharedmemory的有效利用。
可以发现,Coalesced Transpose算法对shared memory的操作如图5-8所示,若开启线程数目为4×4,共享内存有4个bank,相邻线程读取共享内存数据的内存跨度为4个bank,这样就会产生4路bank冲突,限制了共享内存的访存性能。由于bank的数量受硬件的限制,所以有时没法增加,为了解决矩阵转置过程中shared memory的bank conflict,有一个简单直接的方法:在申请shared memory内存时添加一列(padding),以对内存地址进行错开,即列数N与4互质。通过增加padding后,访问情况将从图5-8的方式变成图5-9的方式,注意,图5-9的访问方式中,连续4个线程访问连续的bank,因此不存在bank conflict。
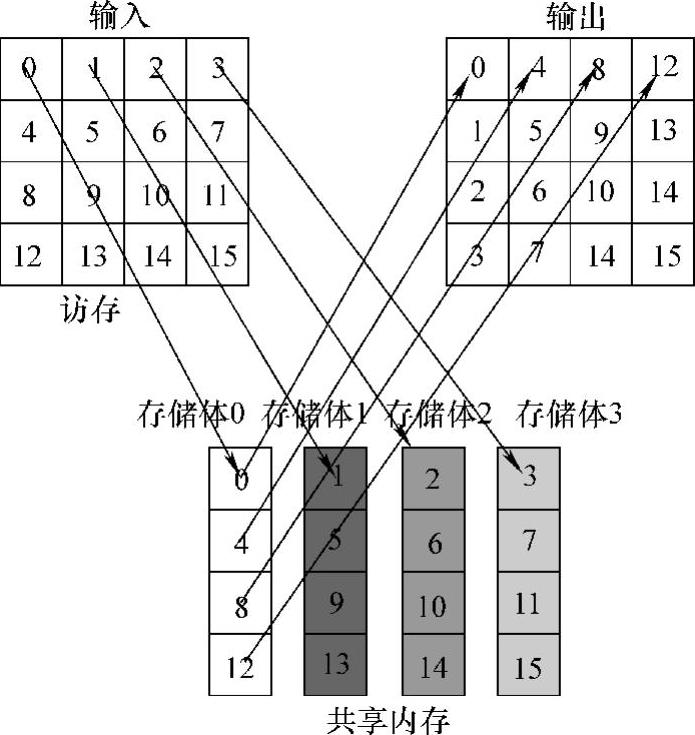
图5-8 bank conflict(https://www.daowen.com)

图5-9 使用padding解决bank conflict
根据图5-9的访问方式,提出Bank Conflict Free Transpose算法,该算法通过使用padding而避免了bank conflict。通过申请shared memory空间时增加padding,即可完成对连续bank的并行访问操作,从图5-9可知,解决bank conflict。
3.channel conflict优化
通道冲突(channel conflict)与shared memory的bank conflict类似,当warp中多个线程同时访问一个bank,将会产生bankconflict,其产生原因为warp的内部线程不合理操作,而channel conflict是针对活跃block而言的,即活跃block不均衡分配到channel,导致只有少量channel在工作。
以global memory被分为8个channel的GPU为例,每个channel是256B宽,当所有活跃的block能够均匀地分配到global memory的channel时,能对global memo-ry实现并行访问。然而当所有block只分配到少量的channel而导致其他channel的空闲,那么对活跃work-group对少量channel的同时访问将会导致串行化,降低global memory的访存效率。
为了更高效地使用全局内存,让所有活跃的block均匀地分配到所有channel,以实现并行访问。由于channel conflict的产生与活跃的block的调度有关,因此如何有效地利用blockid索引是有效减少channel conflict的重要方式,线程可以通过block的坐标,以进行适当的block索引映射,以解决channel conflict。
进一步分析,当global memory含有8个channel,每个channel的宽度为256B,因此,相差2048B的访存动作将会映射到相同的channel,导致操作的串行化。以float元素矩阵为例,当列数为512倍数时,同一列的访存将映射到同一个channel当中。以block所负责处理的shared memory矩阵大小为32×32(即128B×128B)为例,相邻的两个block的访存操作将会映射到同一个channel当中,以此类推,详情如图5-10所示。
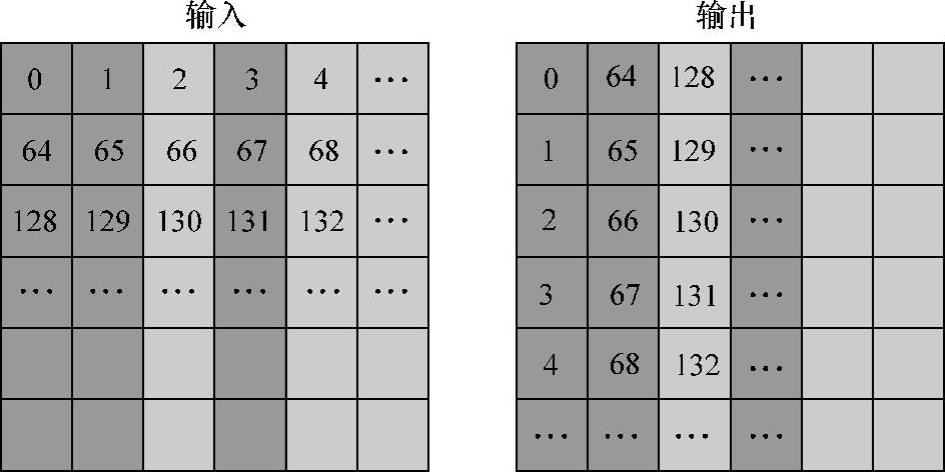
图5-10 channel conflict
使用共享内存只能够解决block内部的非连续访存问题,但是仍不能解决并行执行的warp发起的访存请求所造成的全局内存通道冲突。理论上可以通过bank conflict free的方法来解决此问题,然而需要大量的空间写入,无疑增加了算法的复杂性。因此,通过使用Diagonal坐标转换,对每个grid处理的数据块进行重新排序,使相邻的数据块在计算时不相邻,如图5-11所示。
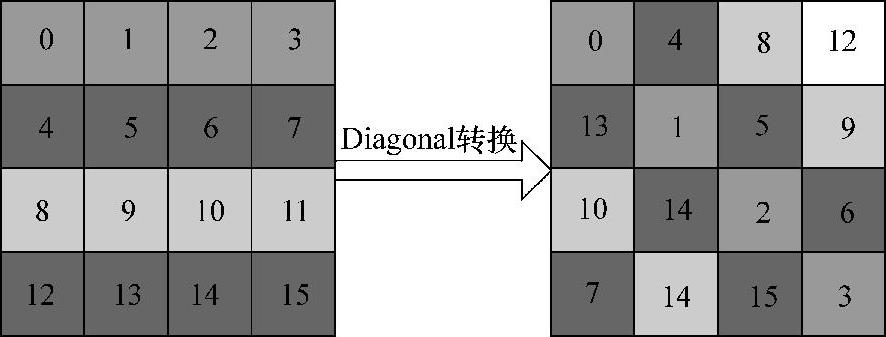
图5-11 对角坐标映射
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





