CPU与GPU之间的数据传输是GPU程序的主要性能瓶颈,即使在TegraX1平台上,虽然device和host内存共享,但是device端与host端之间的数据传输也是整个算法性能主要瓶颈之一。内存分为pageable memory和pinned memory。如图5-1所示,当将数据从host传到device时,需要先将pageable memory传到pinned mem-ory,所以pinned memory无论是device与host还是device与device之间传输速率都远大于pageable memory的传输速率。
以NVIDIA Tegra X1为例,传输32MB的数据,在pinned memory上host传输到device的传输速率的带宽为9892.3MB/s,device传输到host的传输速率的带宽为10076.1MB/s。而在pageable memory上,host传输到device的传输的实际带宽为2236.1MB/s,device传输到host的传输的实际带宽为1958.4MB/s,而device之间传输的实际带宽达到17919.4MB/s。因此,选择合适的内存可以实现数据传输的优化。
实际上,CUDA提供一种允许GPU线程直接访问host端的pinned memory的机制,称为zero copy。通过线程与底层硬件的直接映射,即可以减少数据传输的消耗。值得一提的是,若在NVIDIA Tegra X1和NVIDIA Tegra K1中无法标识已分配内存为pinnedmemory,只能重新分配一块pinned memory。(www.daowen.com)
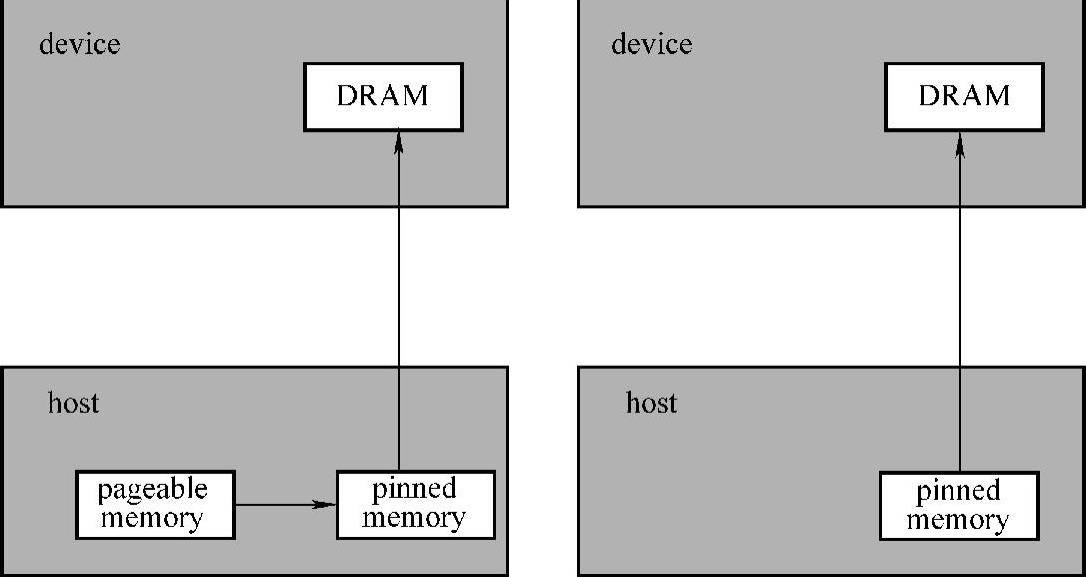
图5-1 数据传输
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






