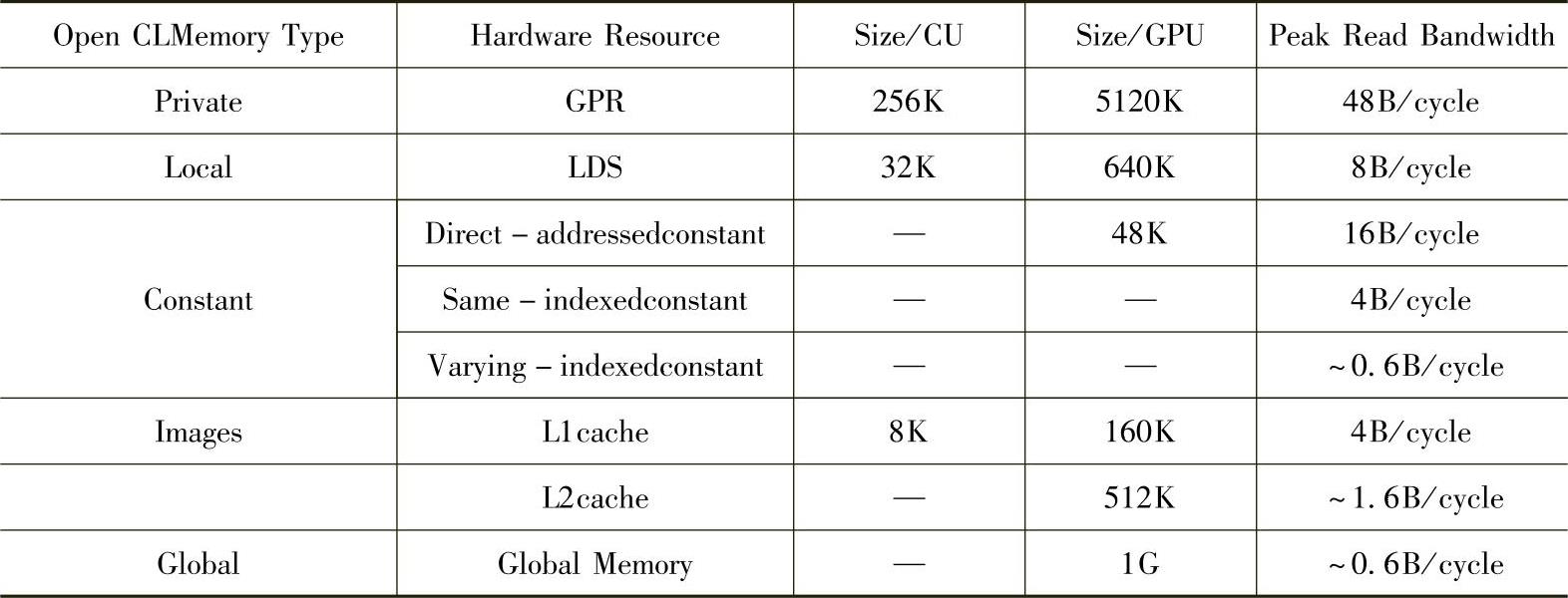
【摘要】:OpenCL定义了层次化的内存模型,共定义了全局内存、常量内存、本地内存和私有内存四块不同的存储区域。常量内存是位于全局内存中的一块内存区域,其内存在kernel的执行期间不能修改。由此可见,OpenCL的内存模型和GPU的内存架构具有很好的映射关系。OpenCL定义了宽松的内存一致性模型,本地内存只在本地同步点保证同一个work-group内的所有work-item的内存一致性。以RadeonHD5870为例,OpenCL内存模型映射到GPU硬件内存的对应关系见表4-1。
OpenCL定义了层次化的内存模型,共定义了全局内存、常量内存、本地内存和私有内存四块不同的存储区域。全局内存可被NDRange中的所有work-item访问,一般具有较大的容量,但一般位于片外,具有相对较低的访存带宽和较高的访存延迟,并由主机端进行动态分配。常量内存是位于全局内存中的一块内存区域,其内存在kernel的执行期间不能修改。本地内存是一个隶属于work-group的内存区域,可实现在同一个work-group内的所有work-item的数据共享和通信。本地内存位于片上,一般容量有限,但具有较高的访存带宽和较低的访存延迟,并由kernel进行静态分配。私有内存是work-item的私有存储区域,对其他work-item不可见,同样由kernel进行静态分配。由此可见,OpenCL的内存模型和GPU的内存架构具有很好的映射关系。
OpenCL定义了宽松的内存一致性模型,本地内存只在本地同步点保证同一个work-group内的所有work-item的内存一致性。全局内存的一致性只在全局同步点保证。
此外,各级存储类型在容量和速度上都有很大差别。以RadeonHD5870为例,OpenCL内存模型映射到GPU硬件内存的对应关系见表4-1。其中全局内存容量最大但是速度最慢,私有内存容量较小但速度最快。各存储层次带宽由高到低依次为:私有内存>常量缓存>局部存储>L1cache>L2cache>全局存储。(https://www.daowen.com)
表4-1 OpenCL内存模型与GPU硬件资源映射关系
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





