OpenCL的执行模型可以分为两部分:运行于Host端的主程序和运行于计算设备的内核程序(Kernel)。主程序通过定义和管理上下文(context)来控制内核程序的执行,内核程序则在OpenCL设备上执行具体的计算任务。
主程序执行内核程序之前必须为其设置一个标识索引的工作空间(NDRange),内核程序会在该工作空间的每一个节点(work-item)上执行kernel实例,每一个work-item在工作空间中拥有唯一识别的global_id。work-item还可粗粒度地被组织为工作组(work-group),每一个work-item在work-group内具有唯一可标识的local_id,而每一个work-group均拥有唯一标识的group_id。
NDRange是为内核程序定义的一个N维空间,其中N为1、2或3,分别对应于一维、二维或三维空间。Global_id、local_id和group_id的维数由启动kernel参数时定义,均为N,坐标范围为0~N-1。如图4-4所示。
在AMD的GPU中,wavefront为调度和执行的基本单位,每个wavefront包含64个线程,此由硬件实现所决定,它提供了比工作组更细粒度的并行。每一个wavefront中的64个work-items执行相同的指令序列。一个CU可同时调度执行多个work-group,但一个work-group只能映射至单个CU,而kernel执行时会将work-group划分为一个或多个的wavefront。每个CU只有16个处理单元,因此一条指令至少需要4个周期才能执行完成。当CU中调度多个wavefront时,任何一个wavefront因访存而阻塞,可快速切换到下一个就绪的wavefront,从而隐藏访存的延迟。(https://www.daowen.com)
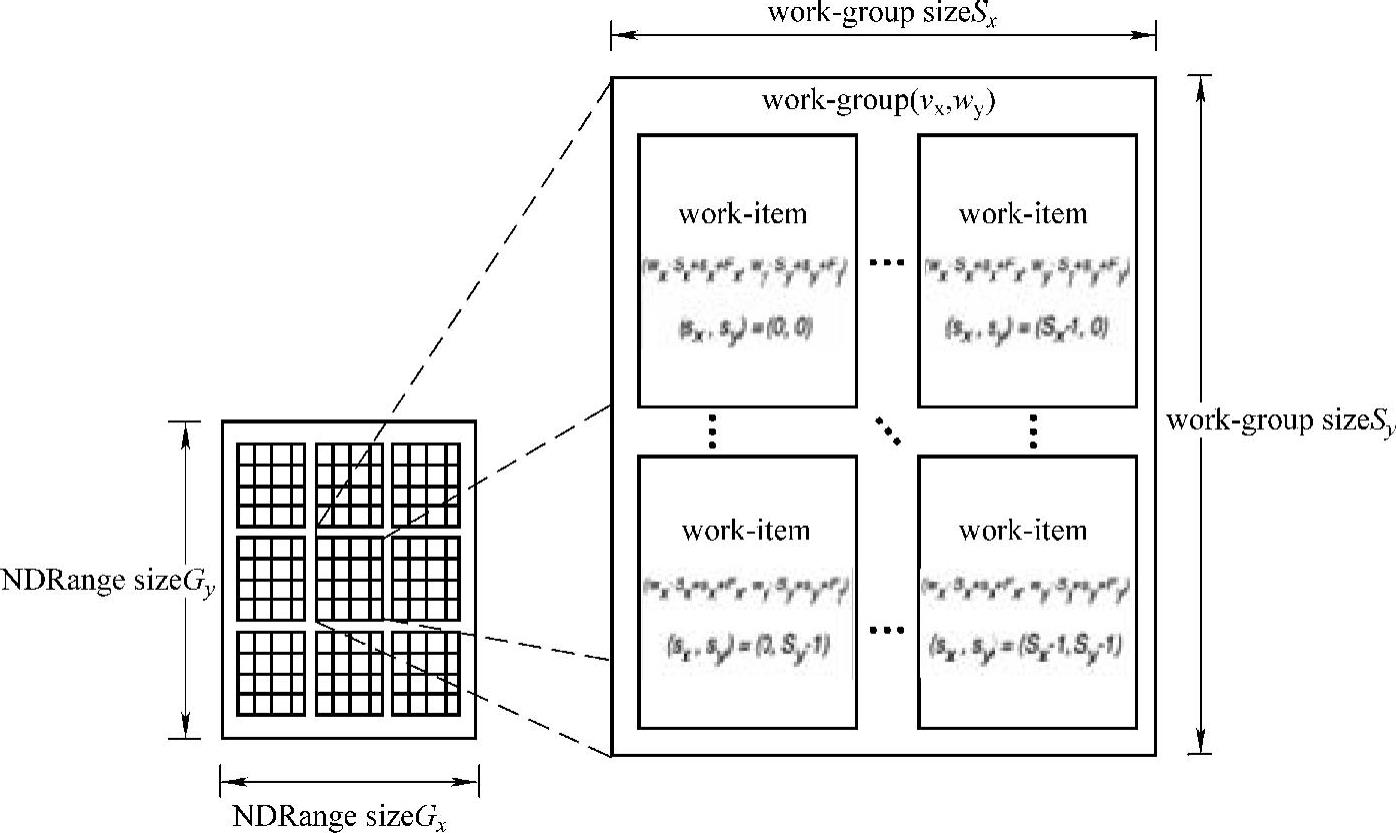
图4-4 NDRange实例
在NVIDIA的GPU中线程是以warp为单位执行的,每个warp由32个线程组成,此处的warp对应于AMD的GPU中的wavefront,而NVIDIA的GPU中block对应于AMD的GPU中的work-group。以TeslaC2050为例,一个warp有32个线程,SM中有16个核心,因此每发射一条指令,需要两个周期才能执行完成。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






