CUDA是NVIDIA公司于2007年推出,将GPU作为数据并行计算设备的软硬件体系,其硬件体系主要为支持CUDA的GPU。其软件体系包括一组运行时API,一组设备驱动API和一个库文件。
CUDA编程模型如图4-1所示。CUDA编程模型将CPU作为主机端,GPU作为设备端,一个计算系统可由一个主机和多个设备组成。在模型定义中,CPU和GPU各司其职,协同运行:CPU负责逻辑性较强的事务处理和串行计算,而GPU负责高度并行化的数据计算任务。GPU并不能独立运行程序,程序的执行由CPU端控制。CPU启动程序运行,并将适用于大规模并行的计算任务交给GPU执行(kernel函数),GPU在执行完毕后,计算结构返回CPU。
CUDA将计算任务映射为大量相互独立且可并行执行的线程,并由硬件调度运行。CUDA将这些线程以网格(Grid)的形式进行组织和管理,网格又进一步划分成线程块(block),线程块由若干线程组成。在网格中,每个线程都有自己的线程号(thread Id)和线程块号(block Id)。线程块间的执行是相互独立的,可并行执行。这样,在kernel函数中就存在着两层并行性:Grid中的block间的并行和block中的thread并行。两层并行编程模型是CUDA编程模型最重要的创新之一。
CUDA内存模型如图4-2所示,在GPU上CUDA线程可以访问到的存储资源有很多,每个CUDA线程拥有独立的本地内存(Local Memory),每一个线程块(block)都有其独立的共享内存(Shared Memory),共享内存对于线程块中的每个线程都是可见的,它与线程块具有相同的生存周期,而全局内存(Global Memory)对所有的CUDA线程都是可访问的。
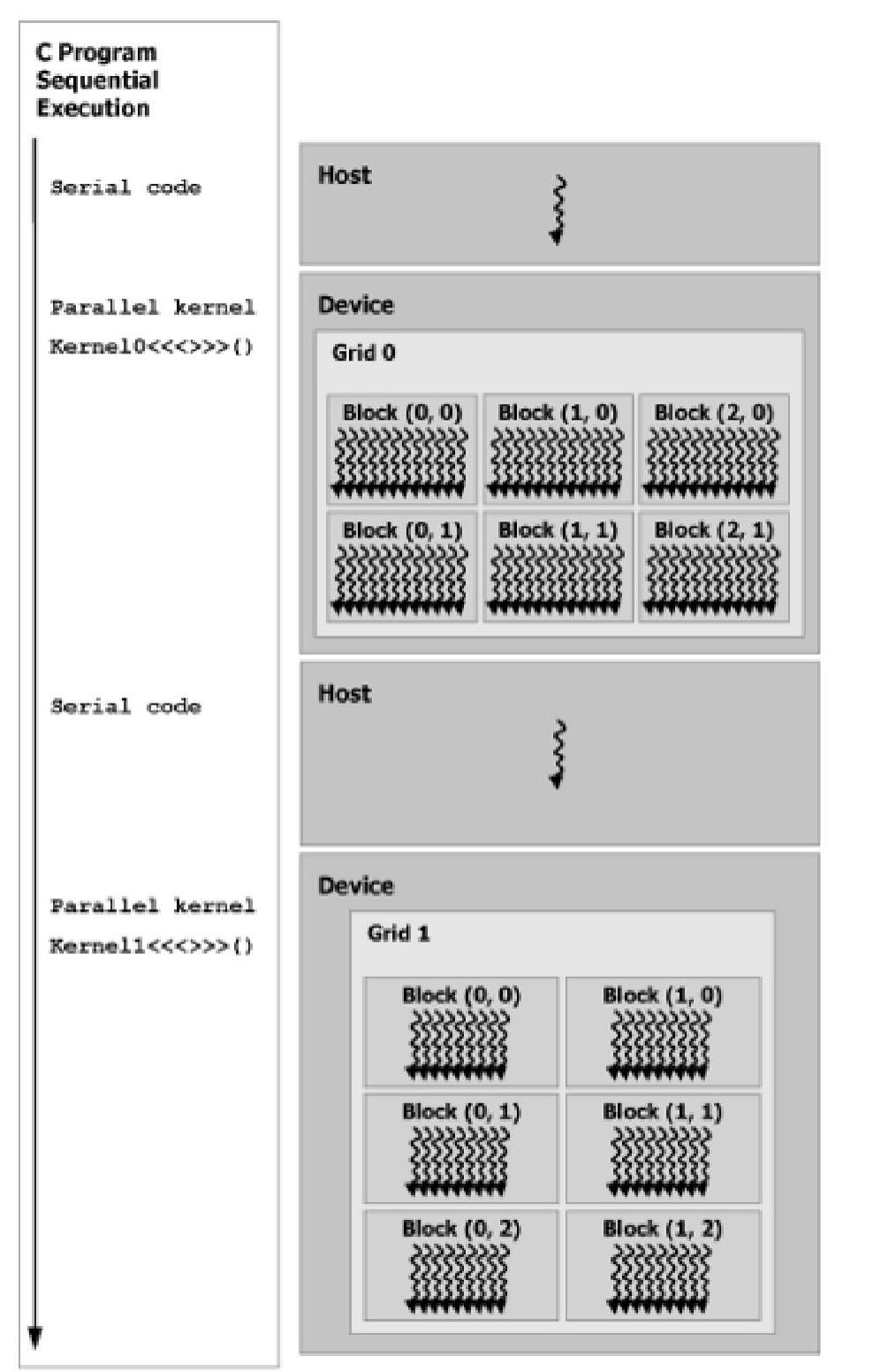
图4-1 CUDA编程模型(https://www.daowen.com)
除了上述三种存储资源以外,CUDA还提供了两种只读内存空间:常量内存(Constant Memory)和纹理内存(Texture Memory)。同全局内存类似,所有的CU-DA线程都可以访问它们。对于一些特殊格式的数据,纹理内存提供多种寻址模式以及数据过滤方法来操作内存。这两类存储资源主要用于一些特殊的内存使用场合。
一个程序启动内核函数以后,全局内存、常量内存以及纹理内存将会一直存在直到该程序结束。CUDA C是C语言的一个扩展子集,它允许程序员定义一种被称为内核函数的C函数,内核函数运行在GPU上,一旦启动,CUDA中的每一个线程都将会同时并行地执行内核函数中的代码。内核函数使用关键字-global-来声明,运行该函数的CUDA线程数则通过<<<...>>>执行配置语法来设置。
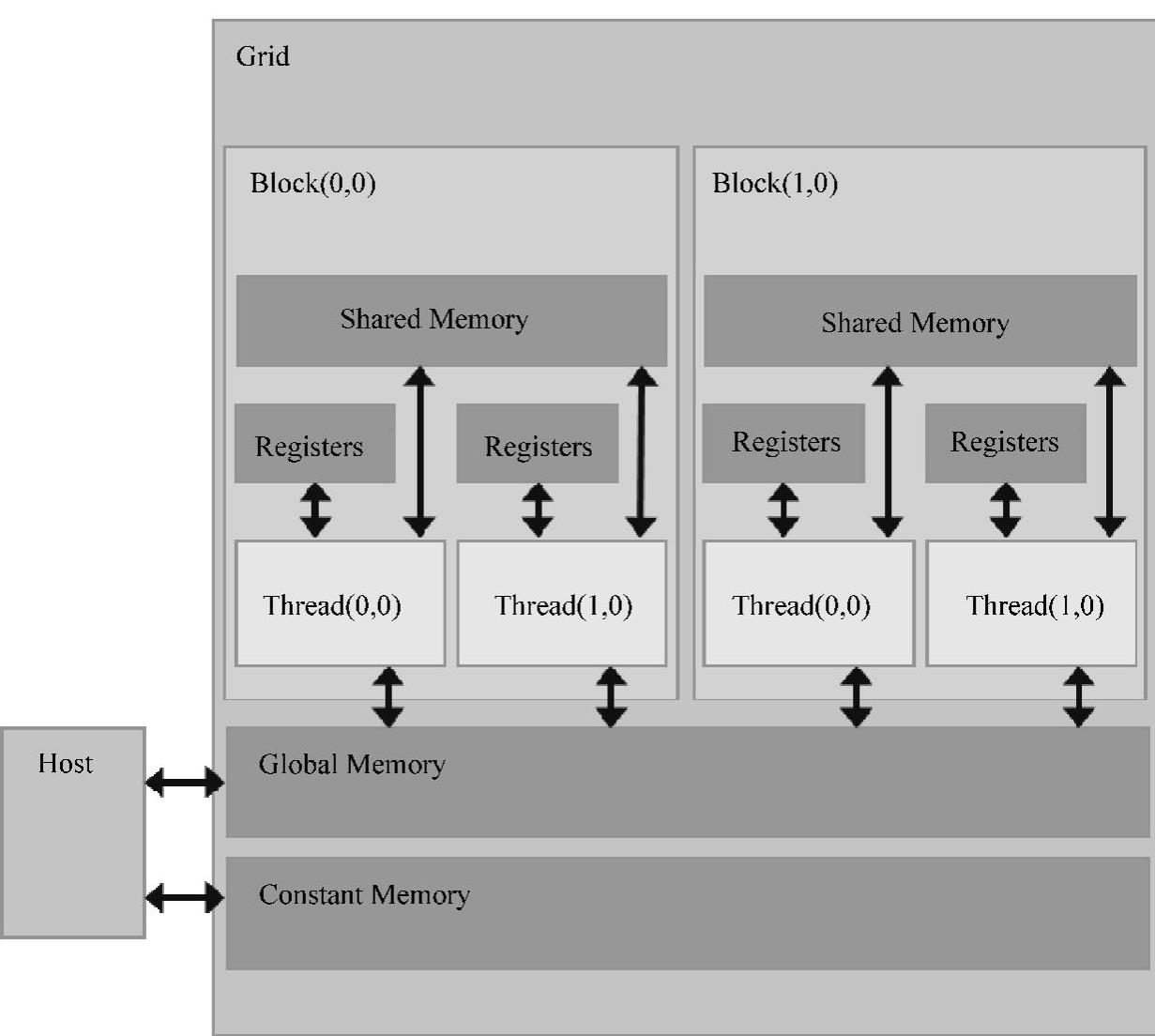
图4-2 CUDA内存模型
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





