1.Cypress架构
AMD Cypress架构沿用了传统GPU的单指令数据流(Single Instruction Multiple Data,SIMD)架构,可以视为由若干个SIMD处理单元组成的多处理器。不同型号的处理器拥有的SIMD处理单元的数目是不同的。比如AMD HD5850 GPU有18个SIMD处理单元,而AMD HD5870有20个SIMD处理单元。AMD Cypress GPU的架构特征如图3-10所示。
如图3-11所示,同NVIDIA Fermi架构一样,AMD Cypress架构依然采用了层次式的架构设计。其最基本的指令执行单元为SC(Stream Core,流处理核心)。与CUDA核心不同,SC采用了向量化架构,由5个相互独立的处理部件组成,形成了一个5路VLIW(Very Long Instruction Word,超长指令字)处理器。这样SC在一个时钟周期内可最多同时处理5条相互独立的指令,这就为开发指令级并行提供了硬件条件。两个处理部件的组合可执行一条双精度浮点数运算,执行速度相对较慢。此外,SC内部还有一个特殊函数处理单元(T-PE),用以处理sin、log等复杂函数。16个SC组成了SIMD处理单元,并共享一个程序计数器,因此,它们的执行完全是同步的。除此之外,SIMD单元拥有有限数量的寄存器以及程序员可以控制的本地内存(共享内存,NVIDA GPU),本地内存可被运行在SIMD单元的所有线程共享,并可实现位于同一线程块内的所有线程的通信。SIMD计算单元阵列构成了GPU,并通过极线程调度处理器(Ultra-thread dispatch processor)维护若干独立的命令队列,以此来调度大量线程独立计算数据流中不同的数据元素。
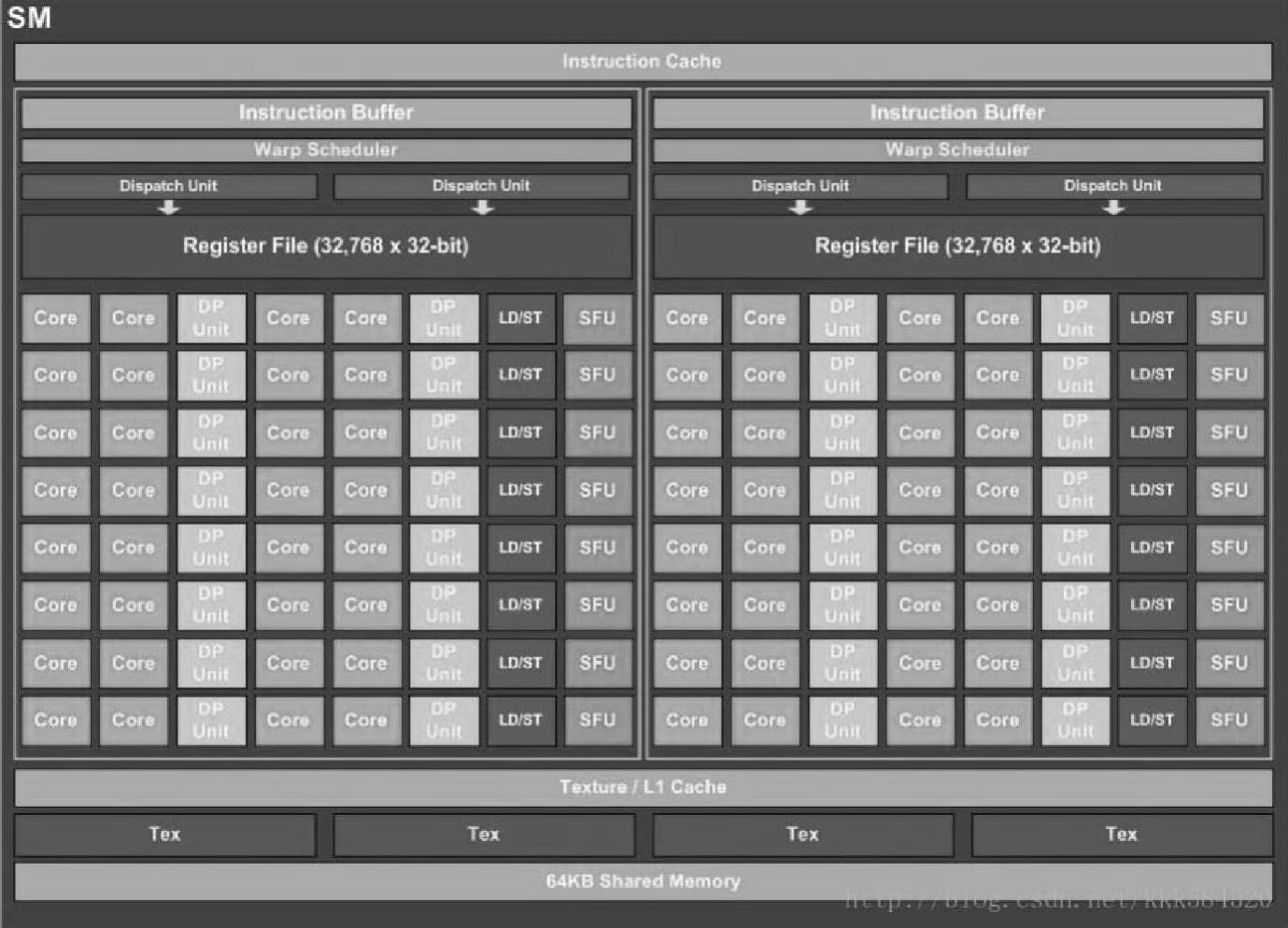
图3-9 Pascal SM架构
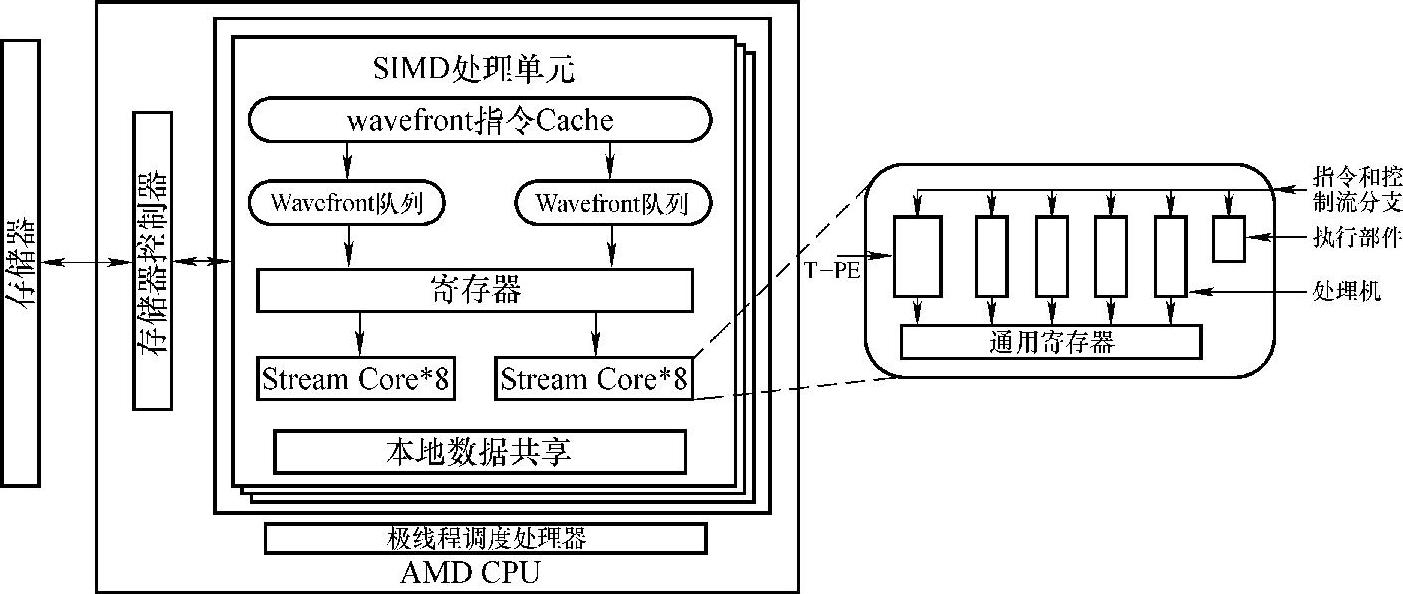
图3-10 AMD Cypress架构
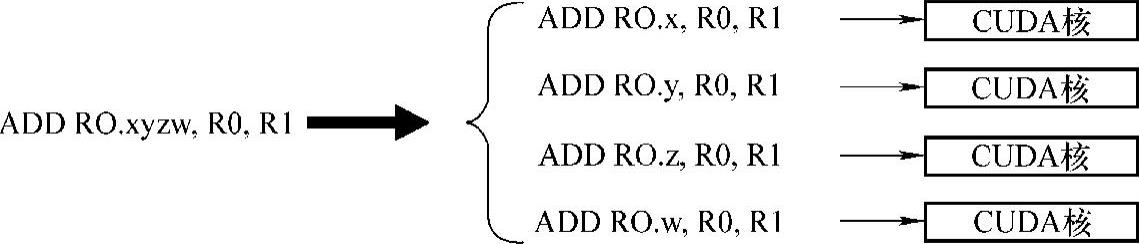
图3-11 矢量加法在NVIDIA GPU上的运行
同NVIDIA GPU一样,AMD GPU同样采用了多线程调度机制。其执行和调度的最小单位是由64个线程组成的wavefront。wavefront间的执行是相互独立的,并且每个wavefront只能在一个SIMD计算单元上调度执行。由于每个SIMD计算单元内部只有16个SC。因此,一个wavefront指令的完成需要4个时钟周期。同NVDIA GPU一样,AMD GPU可在SM上部署大量的wavefront,这些wavefront将以时间片的方式轮转执行,当一个wavefront因访存而造成阻塞时,线程调度器会立即调度其他wavefront来执行。以此来隐藏访存延迟,减少计算资源的浪费。这也是GPU程序优化的通用法则:在GPU上部署足够多的线程,以隐藏访存延迟。
AMDGPU的每个SIMD计算单元同样拥有通用计算器和本地内存等有限的片上资源。如Cypress架构每个SIMD计算单元拥有32KB的本地内存和16KB的128位的向量寄存器。这些硬件资源的限制,同样会导致GPU程序优化空间的不连续性。
2.GCN架构
相比于Cypress架构,GCN架构在硬件架构上做出了巨大的改进,更适合通用计算。(https://www.daowen.com)
(1)处理器层次结构
GPU厂商通常采用模块化设计,通过增加或减少模块的数目来满足不同层次的需求。为了与OpenCL抽象一致,AMD将其GCNGPU模块化为3个层次:设备、CU和ALU。AMD第一代基于GCN架构的GPU:RadeonHD7970,具有32个CU,每个CU具有64个流核心,故总共有2048个核心。每个CU具有独立的本地内存、一级缓存和常量缓存。所有的32个核心共享统一的二级缓存,二级缓存通过交叉总线(CrossBar)连接到显存控制器。
(2)CU
GCN架构中的CU除了4组向量核心外,还有一个标量核心。每组向量核心包含16个标量ALU,每组向量核心每次执行一条wavefront指令。CU中的标量核心用于计算分支、常量缓存访问和其他以wavefront为单位的操作。GCN中每个CU具有64KB局部存储器,但是每个工作组只可使用32KB。GCN架构中没有单独用于特殊函数计算的单元。
CU中计算单元主要是4个向量核心,每个核心可同时处理16个32位浮点乘加运算,这意味着CU每周期的计算能力为16×4×2=128个操作。
(3)存储器层次
GCNGPU的存储器和处理器一样也呈现出层次结构,这种结构通常表现出缓存的关系,比如本地内存和L2 cache会缓存全局存储器的数据,L1 cache会缓存L2 cache中的数据。
全局内存就是显存,能够被整个索引空间内任何一个工作项读写,并且可在多个内核间调用(除非显式释放)。但其延迟非常大,常用来存储主机端的大容量数据,以避免多次传输。目前常用的显存采用GDDR5技术,容量从2GB到12GB不等。在满足合并访问条件下,能够获得更大的带宽。
CU对全局内存的访问都会通过二级缓存,二级缓存由索引空间内的所有工作项共享,HD7970具有768KB二级缓存。对于GPU来说,二级缓存存在的主要目的是减少访存不对齐的影响,增大带宽,而不是减少延迟,因此其大小远小于对应的x86 CPU。
常量内存(统一)是只读的,索引空间内所有工作项都可以读取,并且可在多个内核间调用。常量内存具有高性能、独立的缓存,为了更好地利用缓存,GCN架构限制软件开发人员声明的常量大小为16KB。由于现代的GPU都具有cache,因此常量内存已经不再那么重要,但是在某些情况下还是能够显著提升程序性能。
本地内存只能被同一个工作组的工作项读写,且只在工作项的生存期间有效,一旦工作组执行完成即不可再用,使用时需要注意并行访问时的竞写问题。本地内存类似于用户可控制的cache,软件开发人员必须显式地使用。GCN架构上每个CU具有64KB本地内存,但是运行在CU上的每个工作组最多只能使用32KB。GCN架构的本地内存划分为32个存储器(bank),每个bank宽度为4B。本地内存常用于通用并行计算时的共享数据和工作组内工作项的通信,但是由于采用的是片上内存,其速度极快,因此也被用于优化程序性能。
GCN架构上每个CU具有16KB一级缓存,它们被用于缓存对全局存储器的访问。GCN架构具有标量和向量寄存器,向量寄存器大小为256KB,每个寄存器大小为32位,故总共有64K个寄存器。如果数据大小是64位,则会使用相邻的两个寄存器。GCN架构限制每个工作项最多可使用的向量寄存器数目为255个。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





