基于计算机视觉的行人检测由于其在车辆辅助驾驶系统中的重要应用价值成为当前计算机视觉和智能车辆领域最为活跃的研究课题之一。其核心是利用安装在运动车辆上的摄像机检测行人,从而估计出潜在的危险以便采取策略保护行人。基于视觉的行人检测系统一般包括两个模块:感兴趣区分割和目标识别。
行人检测除了具有一般人体检测具有的服饰变化、姿态变化等难点外,由于其特定的应用领域还具有以下难点:摄像机是运动的,这样广泛应用于智能监控领域中检测动态目标的方法便不能直接使用;行人检测面临的是一个开放的环境,要考虑不同的路况、天气和光线变化,对算法的鲁棒性提出了很高的要求;实时性是系统必须满足的要求,这就要求采用的图像处理算法不能太复杂。
根据分割所用的信息,可将感兴趣区域选择(ROIs)分割的方法分为基于运动、基于距离、基于图像特征和基于摄像机参数四种方法。基于运动的方法通过检测场景中的运动区域来得到ROIs。基于距离的方法通过测量目标到汽车的距离来得到ROIs,可以用来测距的传感器主要包括雷达和立体视觉。基于图像特征的方法指通过检测与行人相关的图像特征从而得到ROIs。对于可见光图像来说,常用的特征包括竖直边缘、局部区域的熵和纹理等。对于红外图像来说,主要根据人体尤其是人脸的温度比周围环境温度较高这一特征,通过检测一些“热点”(Hot spot)来得到ROIs。摄像机的安装位置和摄像机参数也是一个很重要的考虑因素,它对行人在图像上出现的位置和每个位置上目标的大小给出了很多限制,合理利用这些限制可以大大地缩小搜索空间。
1.DPM目标检测算法
DPM算法由Felzenszwalb于2008年提出,是一种基于部件的检测方法,对目标的形变具有很强的鲁棒性。目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被视觉目标分类(VOC)授予“终身成就奖”。
DPM算法采用了改进后的HOG特征,支持向量机(SVM)分类器和滑动窗口(Sliding Windows)检测思想,针对目标的多视角问题,采用了多组件(Compo-nent)的策略,针对目标本身的形变问题,采用了基于图结构(Pictorial Structure)的部件模型策略。此外,将样本所属的模型类别、部件模型的位置等作为潜变量(Latent Variable),采用多示例学习(Multiple-instance Learning)来自动确定。
2.DPM的特征
DPM采用了HOG特征,并对HOG特征进行了一些改进。如图2-34所示,DPM改进后的HOG特征取消了原HOG中的块(block),只保留了单元(Cell),但归一化时,是直接将当前单元与其周围的4个单元(Cell)所组成的一个区域归一化,所以效果和原HOG特征非常类似。计算梯度方向时可以计算有符号(0°~360°)或无符号(0°~180°)的梯度方向,有些目标适合使用有符号的梯度方向,而有些目标适合使用无符号的梯度,作为一种通用的目标检测方法,DPM与原HOG不同,采用了有符号梯度和无符号梯度相结合的策略。如此,如果直接将特征向量化,那么单单一个8×8的单元,其特征维数就高达4×(9+18)=108,维数过高。Felzenszwalb提取了大量单元的无符号梯度,每个单元共4×9=36维特征,并进行了主成分分析(Principal Component Analysis,PCA),发现使用前11个特征向量基本上可以包含所有的信息,不过为了快速计算,作者由主成分可视化的结果得到了一种近似的PCA降维效果。具体来说,将36维向量看成4×9=36的矩阵,对每一行、每一列求和得到13维特征,基本上能达到HOG特征36维的检测效果。为了提高那些适合使用有符号梯度目标的检测精度,作者再对18个有符号梯度方向求和得到18维向量,并入其中,最后得到图2-34中的13+18=31维特征向量。
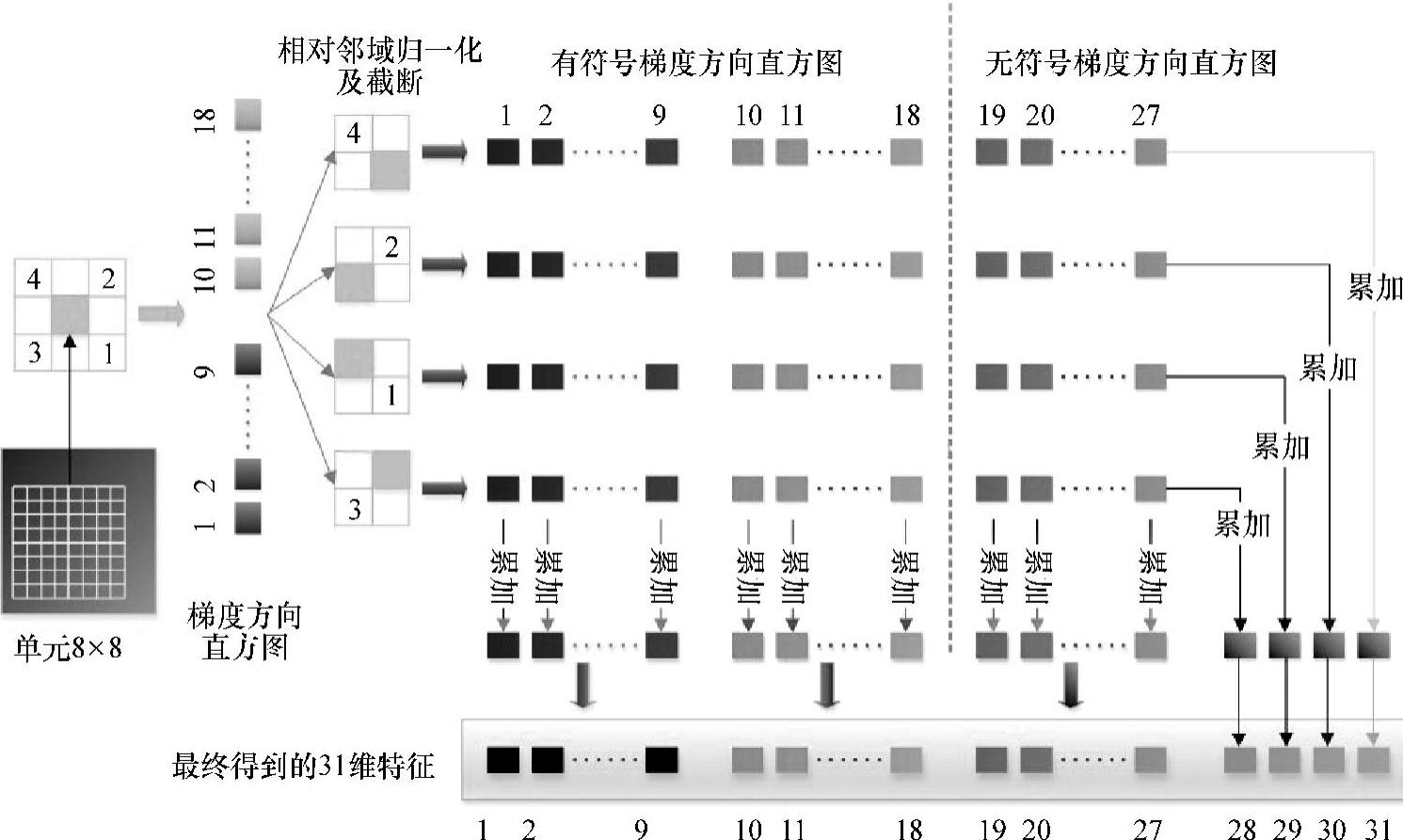
图2-34 DPM改进后的HOG特征
3.DPM的检测模型
DPM V3版本的目标检测模型由两个组件构成,每一个组件由一个根模型和若干部件模型组成。图2-35a和图2-35b是其中一个组件的根模型和 部件模型的可视化的效果,每个单元内都是SVM分类模型系数对梯度方向加权叠加,梯度方向越亮的方向可以解释为行人具有此方向梯度的可能性越大。如图2-35a所示,根模型比较粗糙,大致呈现了一个直立的正面/背面行人。如图2-35b所示,部件模型为矩形框内的部分,共有6个部件,分辨率是根模型的两倍,这样能获得更好的效果。从中,我们可以明显地看到头、手臂等部位。为了降低模型的复杂度,根模型和部件模型都是轴对称的。图2-35c为部件模型的偏离损失,越亮的区域表示偏离损失代价越大,部件模型的理想位置的偏离损失为0。

图2-35 DPM行人模型
4.DPM的检测流程
DPM采用了传统的滑动窗口检测方式,通过构建尺度金字塔在各个尺度搜索。图2-36(见彩插)为某一尺度下的行人检测流程,即行人模型的匹配过程。某一位置(x,y)与根模型/部件模型的响应得分,为该模型与以该位置为锚点(即左上角坐标)的子窗口区域内的特征的内积。也可以将模型看作一个滤波算子,响应得分为特征与待匹配模型的相似程度,越相似则得分越高。左侧为根模型的检测流程,滤波后的图中,越亮的区域代表响应得分越高。右侧为各部件模型的检测过程。首先,将特征图像与模型进行匹配得到滤波后的图像。然后,进行响应变换:以锚点为参考位置,综合部件模型与特征的匹配程度和部件模型相对理想位置的偏离损失,得到最优的部件模型位置和响应得分。
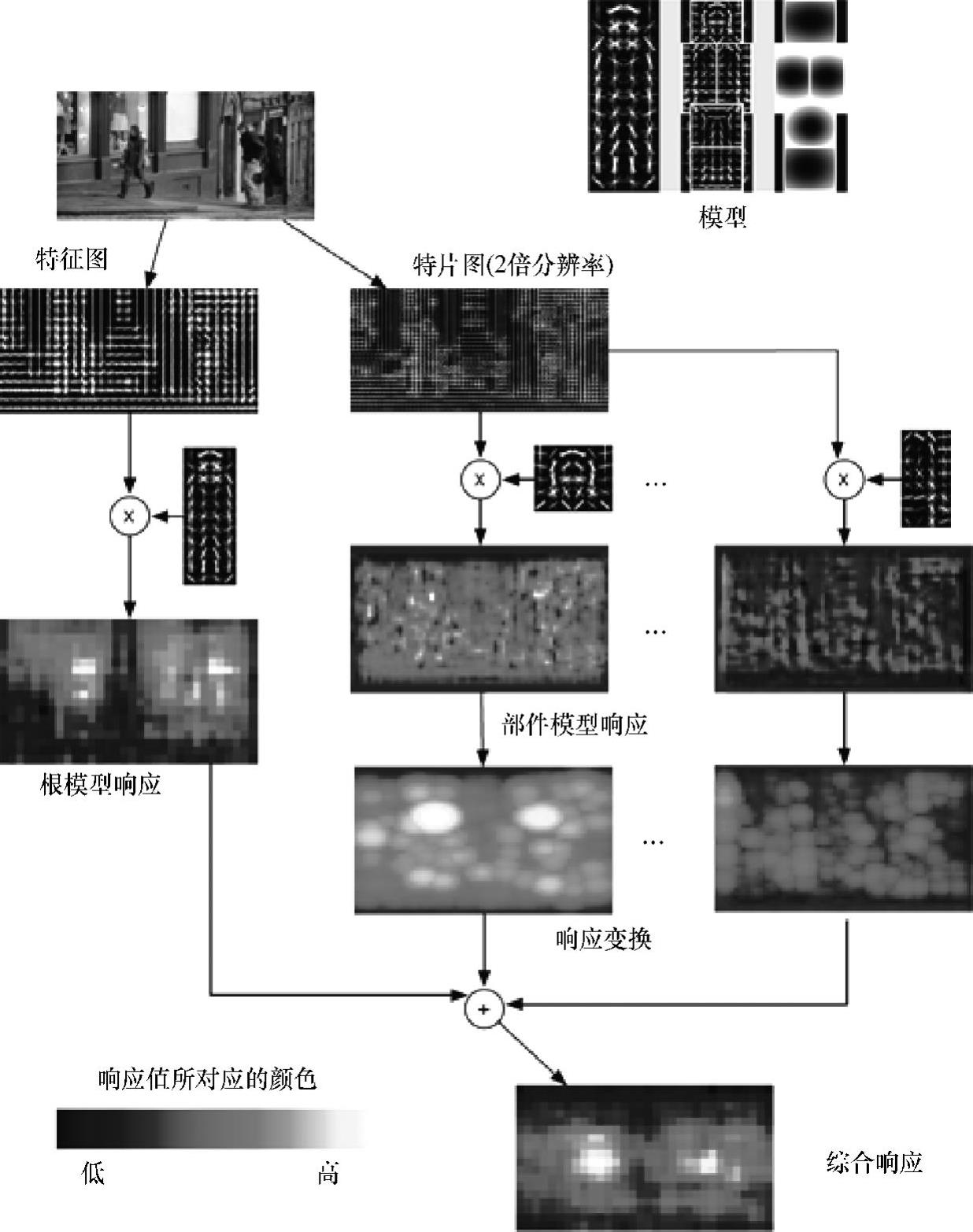
图2-36 DPM算法的检测流程
5.运行结果及分析
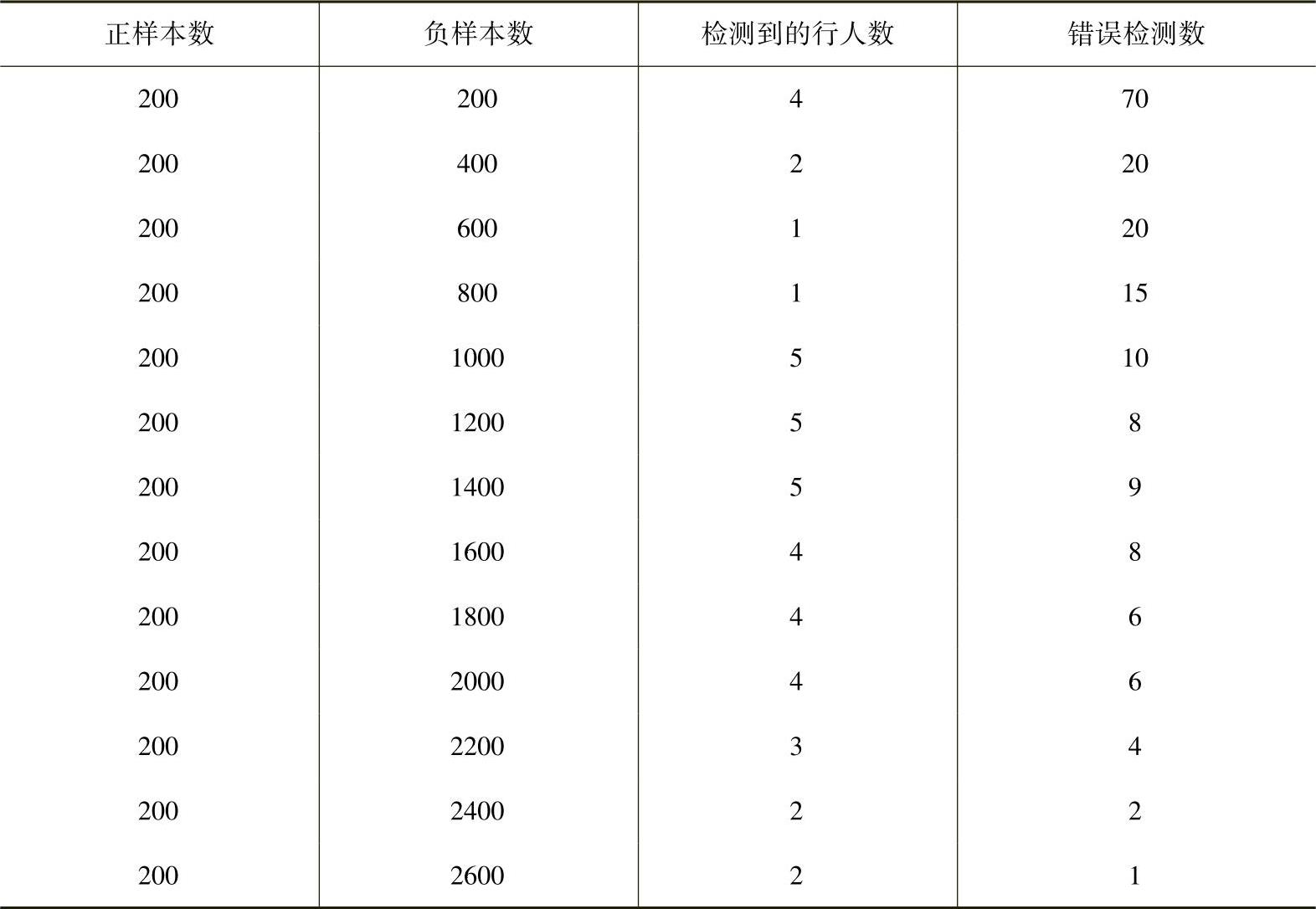
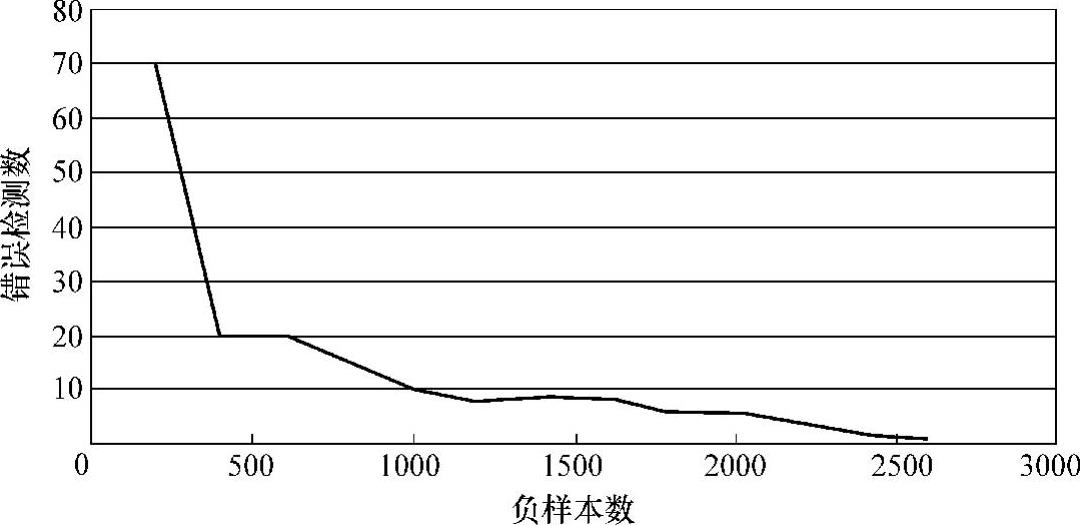
首先将正样本固定为200张,依次增加负样本的数量,来观察检测的正确率,见表2-1。200正样本错误检测数随负样本变化图如图2-37所示。200正样本检测到的行人数随负样本变化图如图2-38所示。
表2-1 正样本为200时检测到的行人数和错误检测数变化表
 (https://www.daowen.com)
(https://www.daowen.com)
图2-37 正样本为200时错误检测数随负样本增加的变化图
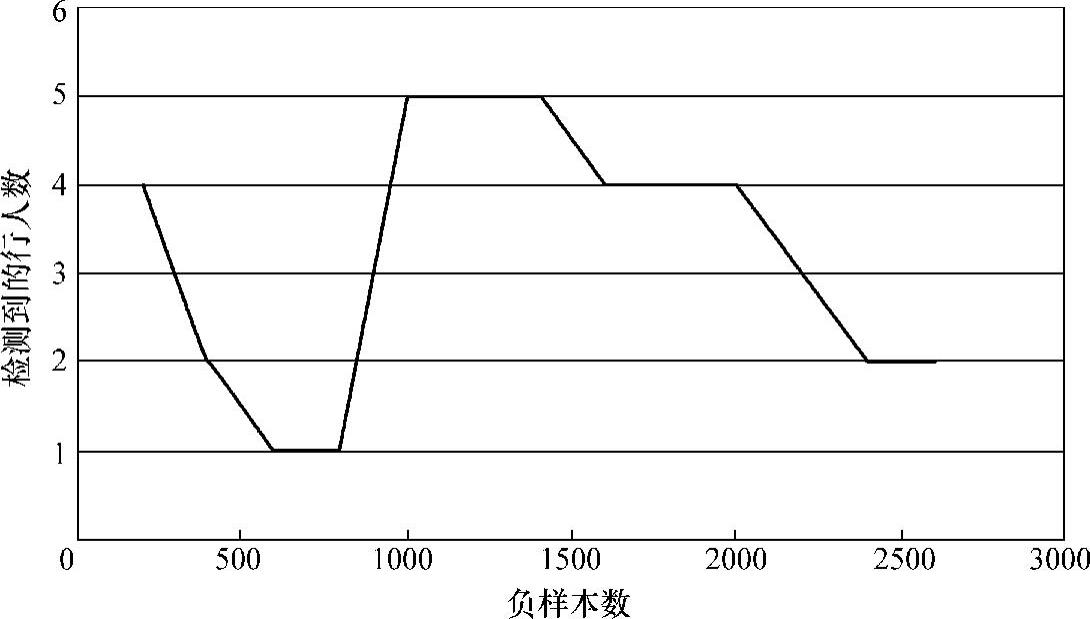
图2-38 正样本为200时检测到的行人数随负样本增加的变化图
然后将正样本的数量提升到600张,再依次增加负样本的数量,观察检测的正确率,见表2-2。600正样本错误检测数随负样本数变化图如图2-39所示。600正样本检测到的行人数随负样本数变化图如图2-40所示。
表2-2正样本为600时检测到的行人数和错误检测数变化表
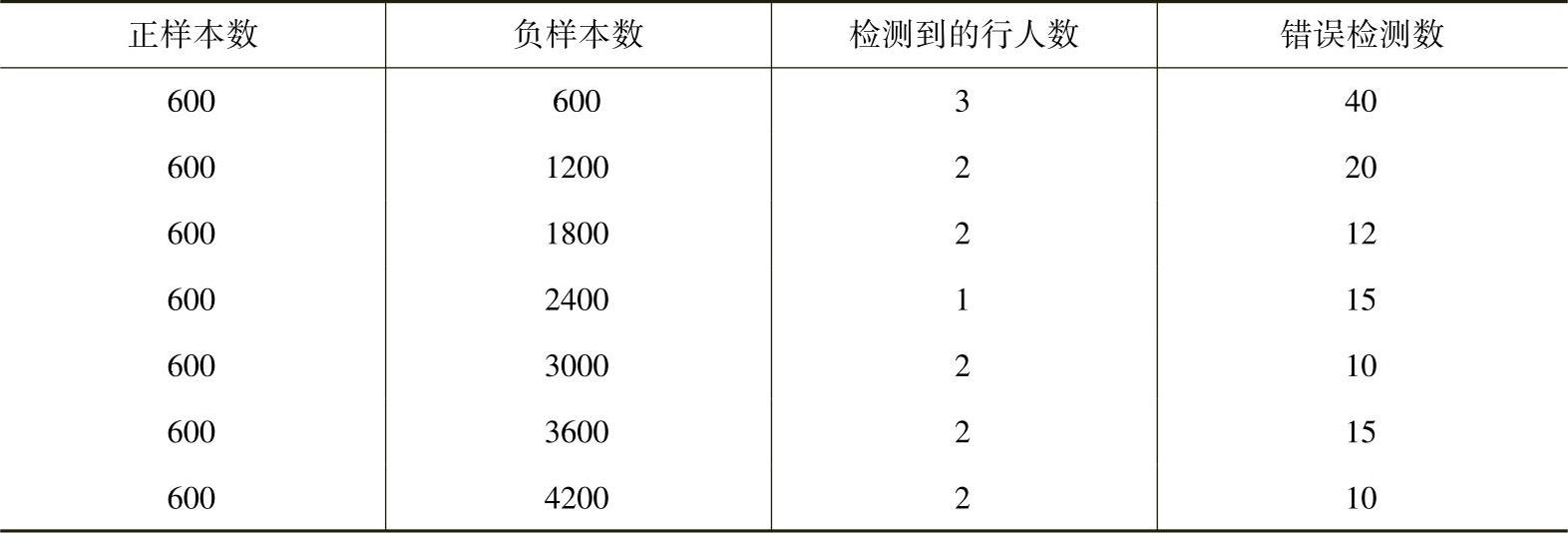
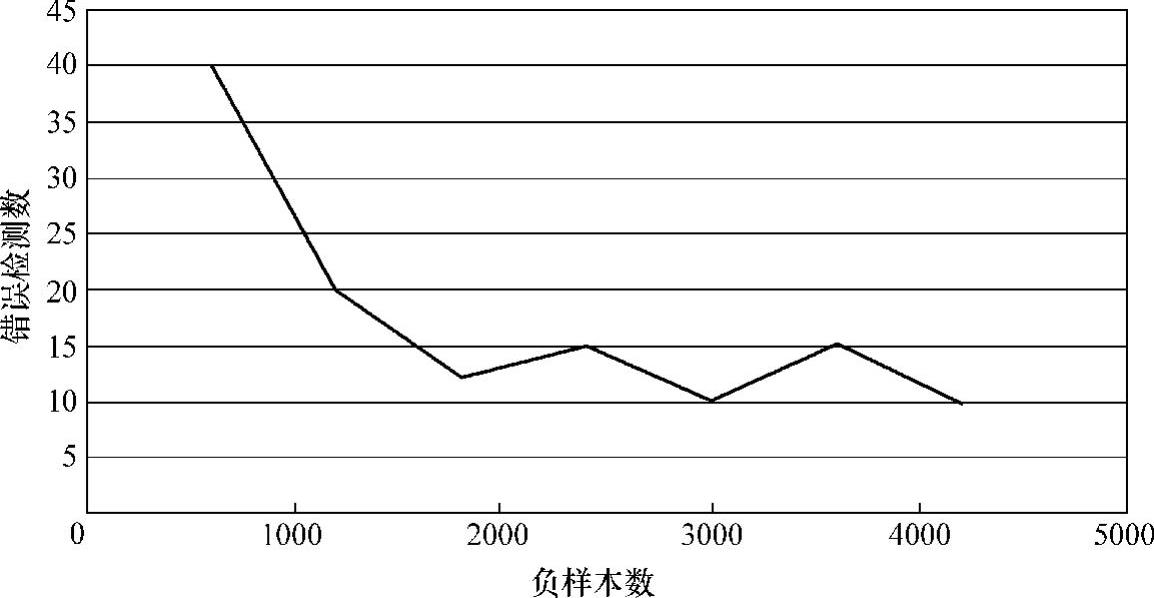
图2-39 正样本为600时错误检测数随负样本增加的变化图
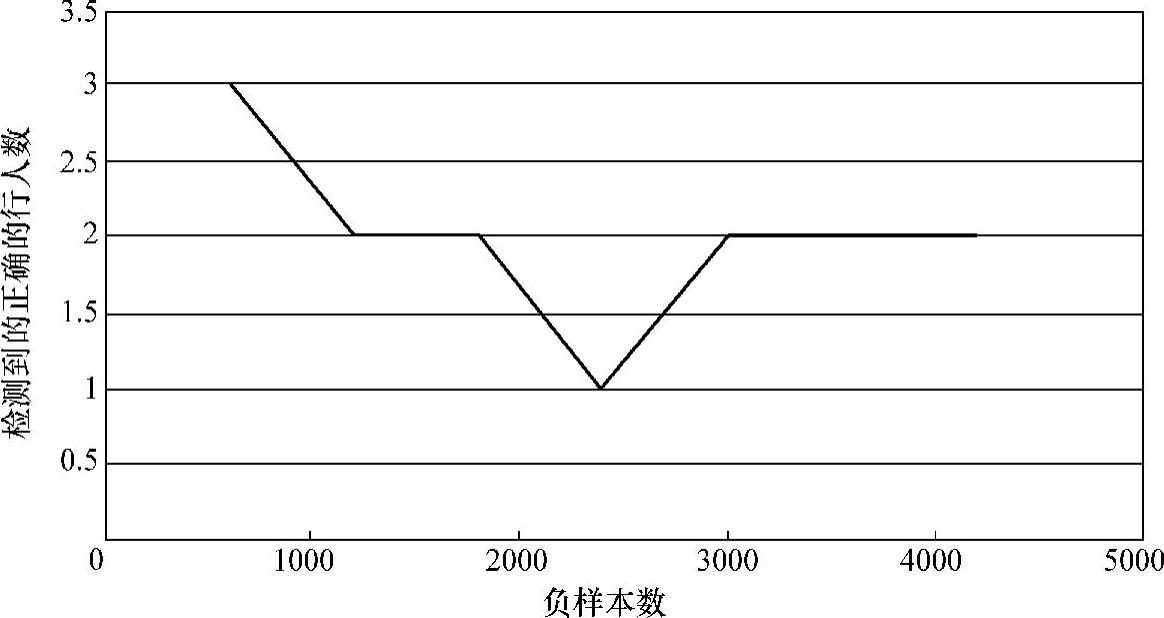
图2-40 正样本为600时检测到的行人数随负样本增加的变化图
正负样本数比分别为1∶1和1∶5时的效果图分别如图2-41和图2-42所示。

图2-41 正负样本数比为1∶1时效果图
分析:从这两组数据可以看出当正样本数固定时,随着负样本数的增加,错误检测数会明显减少,由于可能会出现物体之间的重叠遮挡等问题,会出现在一定阶段随着负样本数的增加错误检测数会有小幅度的增加。也可以看出随着负样本数的增加,检测到的正确的行人数也会减少。但在正负样本数达到一定比例时会出现能检测到所有或者大多数的行人,而错误检测数又相对比较少的情况,这个比例是我们所要找的比例,以我们的实验的样本来说这个比例大约是在正样本数比负样本为1∶5左右。

图2-42 正负样本数比为1∶5时效果图
从以上两组数据可以得出:
 在正样本固定的情况下,随着负样本的增多,错误率会减少,但漏检率会增加。
在正样本固定的情况下,随着负样本的增多,错误率会减少,但漏检率会增加。
 正样本的增加会使错误率增加,但会使漏检率减少。
正样本的增加会使错误率增加,但会使漏检率减少。
 并不是说正样本越大检测效果就越好,而是,检测效果在正负样本成一定比例时最好,比例为1∶5时就有比较好的效果。
并不是说正样本越大检测效果就越好,而是,检测效果在正负样本成一定比例时最好,比例为1∶5时就有比较好的效果。
由于样本有限,这些结论只是在有限的样本中总结出来的,所以并不一定正确,因此还需更多的后续努力才行。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





