GPU拥有大量的计算单元,具有强大的计算能力。充分考虑GPU架构特点和调度策略,以有效地利用这些计算单元,避免计算单元的闲置,是提高GPU程序性能的主要途径。
GPU并行计算架构常被称为众核架构(Many-core Architecture)。与传统的CPU计算架构相比,GPU并行计算架构在硬件结构、计算方式、成本能耗等诸多方面有显著不同。在硬件结构方面,CPU硬件上有很大一部分晶体管用于复杂的控制单元和缓存,而GPU硬件的绝大多数晶体管都用于执行单元。在计算方式方面,CPU擅长复杂的指令调度、循环、分支、逻辑判断等计算任务,其并行优势是程序执行层面的,程序逻辑的复杂度限定了程序执行的指令并行性。GPU擅长高度并行的数值计算,可以容纳上千个没有逻辑关系的数值计算线程,其优势是无逻辑关系数据的并行计算。在成本能耗方面,当今的多核CPU的能耗越来越高,计算成本大大增长,而GPU的能耗相对较低,性价比高,更加符合当前绿色计算的理念。图1-4(见彩插)所示为CPU与GPU芯片逻辑架构对比。由图1-4可以清晰看出,GPU相较于CPU拥有更强大的计算能力。
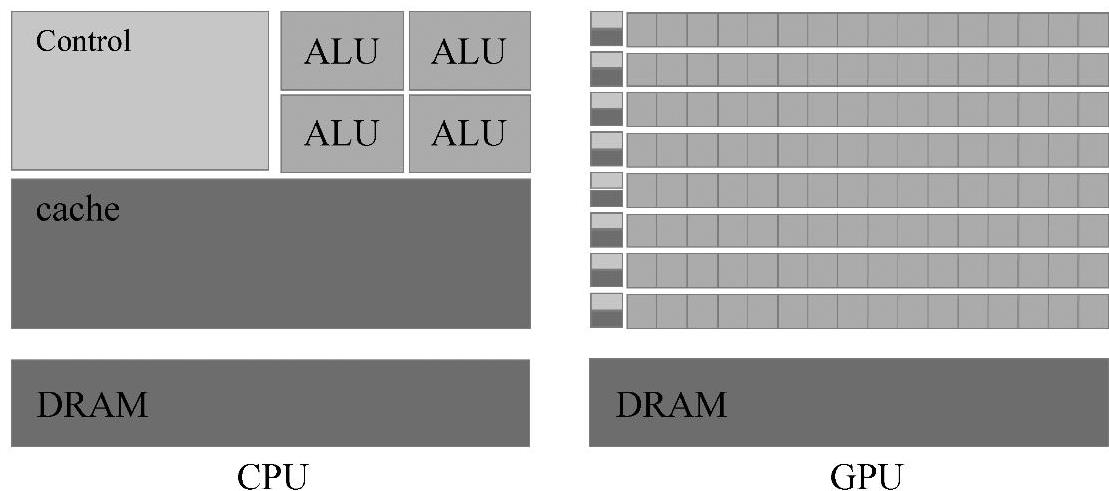
图1-4 CPU与GPU逻辑架构对比
虽然GPU的时钟频率不及CPU高,但GPU的性能与芯片面积之比,性能与能耗之比要比CPU高,尤其在执行并行计算任务时,其计算性能远超CPU。
对于AMD和NVIDIA的两个GPU平台,它们在硬件设计上最大的不同是基本执行单元的设计。在AMD GPU平台中,SC采用了向量化的设计方式,每个SC是一个5路VLIW处理器。在VLIM体系中,通过将多个短指令合并成一条长VLIW指令的方式来提高计算资源的利用率。因此,向量化是提高AMDCPU计算资源利用率的有效方法。而对于NVIDIA GPU平台,由于SP是完全标量化的设计,编译器将向量化操作转化成相互独立的标量操作,因此,向量化操作对NVIDIA GPU平台影响不大。(https://www.daowen.com)
虽然两个GPU平台在硬件设计上存在很大的差异,但在整体架构设计和线程调度上有很多相似性,因此有许多通用的提高计算资源有效利用率的优化方法:
 调整线程组织结构,使work-group的大小为wave-front或者warp的整数倍。
调整线程组织结构,使work-group的大小为wave-front或者warp的整数倍。
 每个CU上同时并发运行足够数目的wave-front或者warp,以隐藏访存延迟。
每个CU上同时并发运行足够数目的wave-front或者warp,以隐藏访存延迟。
 消除分支对性能的影响。
消除分支对性能的影响。
 充分利用共享内存、常量内存、cache等片上资源减少访问global memory的次数。
充分利用共享内存、常量内存、cache等片上资源减少访问global memory的次数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





