CUDA是NVIDIA公司2007年提出的支持其GPU进行通用计算的编程模型和开发环境。在该平台下,软件开发者可以直接使用高级语言(扩展的C语言)编写在GPU上运行的程序,而不必使用Direct X或者Open GL这些图形API,既大大降低了利用GPU进行通用计算的难度,也提高了程序的性能。
CUDA平台为程序开发者提供了所有必要的组件,包括编译器(nvcc)、库函数、运行时环境、显卡驱动等。支持多种操作系统,包括Windows、Linux以及MacOS。此外,为了方便用户的开发工作,还提供了包含很多程序实例的SDK(Software Development Kit)、调试器、性能分析器等工具。图1-2清晰地呈现了CUDA软件栈的层次结构以及应用程序调用关系。同时此图也说明了CUDA平台是非常灵活的,给用户提供了更多选择的机会。应用程序既可以调用上层API(CU-DA Library和CUDA Runtime),也可以直接调用底层API(CUDA Driver)。后者显然要更快一些,但难度也会大一些。
一个完整的CUDA程序分为两部分:主机代码和设备代码。其中前者在主机(通常指CPU)上运行,后者在设备(GPU或其他类似的协处理器)上运行(前提是系统中存在支持CUDA的GPU)。此外,对于没有支持CUDA的GPU的用户,可以选择模拟模式来运行CUDA程序,此时系统将会用主机来模拟设备的运行,但速度很慢。
除了方便性和灵活性之外,CUDA还具有高度的抽象性和可扩展性。抽象性体现在三个方面:线程层次结构、共享存储器和同步路障。这种机制既提供了细粒度(fine-grained)的数据级并行和线程级并行,也提供了粗粒度(coarse-grained)的任务级并行。一个可执行的CUDA程序可以在具有任何数量处理器核的设备上运行,这样用户在进行任务划分时就不必关心底层硬件平台实际所拥有的物理处理器的数量。而且当底层的硬件更新升级后,原有的程序无须做任何改变就可以获得好的性能收益。这就体现了CUDA良好的可扩展性。
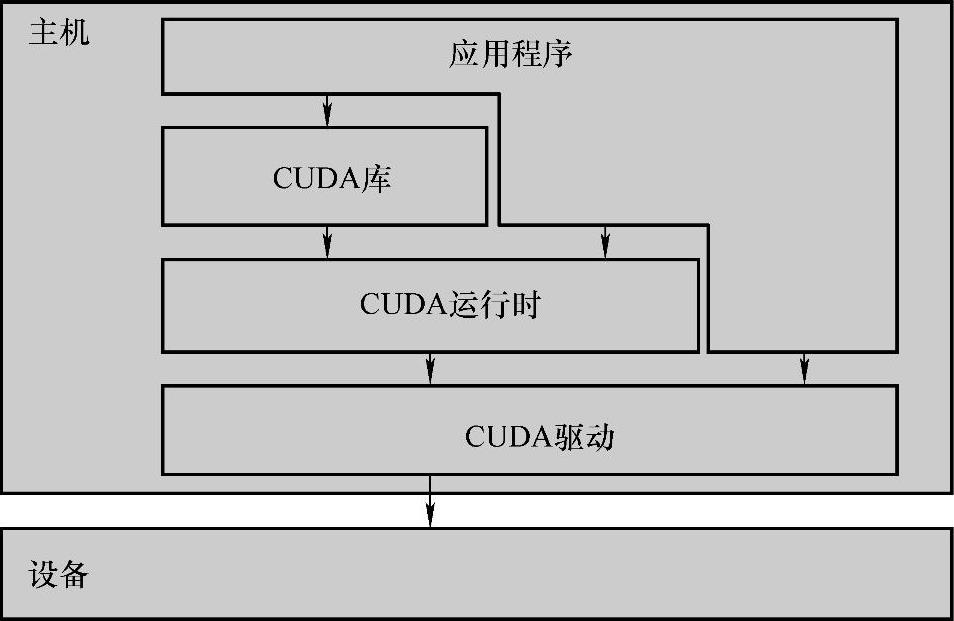
图1-2 CUDA软件栈
CUDA架构的存储器类型包括全局内存、共享内存、本地内存、常量内存、纹理内存和寄存器等。其中全局内存采用通用的访问机制,空间大,所有线程都可对其进行读写操作;共享内存是片上内存,被同一个流多处理器上的线程所共享,访问其上的数据只需要4个时钟周期,避免了线程频繁访问全局内存造成的时间损失;常量内存和纹理内存均采用了cache来提高访问速度。(https://www.daowen.com)
OpenCL(Open Computing Language,开放计算语言)是一个为异构平台编写程序的框架,此异构平台可由CPU、GPU或其他类型的处理器组成。OpenCL由用于编写kernel(在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。
OpenCL是由苹果公司于2008年提出的一个适用于异构计算平台的统一的并行编程模型,也是一种工业标准和规范。一经提出就得到了众多大公司的支持,发展非常迅速。
众所周知,目前的计算平台种类繁多,既有通用的多核CPU,又有专用的拥有强大计算能力的众核GPU,如IBM Cell和基于ARM架构的数字信号处理器(DSP)芯片。由于这些硬件平台的特性和架构差别很大,要想编写一个能在所有平台上高效运行的程序几乎是不可能的。因此,程序员不得不针对特定的硬件平台编写一个新的版本的程序,这无疑加重了他们的负担。OpenCL的出现将会很好地解决这种因底层硬件平台的差异性所带来的软件可移植性的问题。今后,只要程序员编写的程序遵循OpenCL标准,就可以不加修改地在那些支持该标准的硬件平台上高效运行。
OpenCL是一个在异构平台进行并行程序开发的开放工业标准,它将CPU、GPU以及其他各类计算设备组织成一个统一的计算平台,开发者以统一而有效的方式使用这些计算资源。OpenCL框架可划分为OpenCL平台API、OpenCL运行时API和OpenCL编程语言。支持的应用非常广泛,从嵌入式应用、消费软件到高性能计算解决方案都能使用它进行开发。OpenCL的设计初衷是为帮助程序员开发出可移植的、能够高效利用异构系统中所有的硬件资源的程序。基于CPU-GPU的异构模式只是众多异构结构中的一种,也是目前被广泛使用的一种。图1-3形象地说明了OpenCL是专为异构计算而服务的。
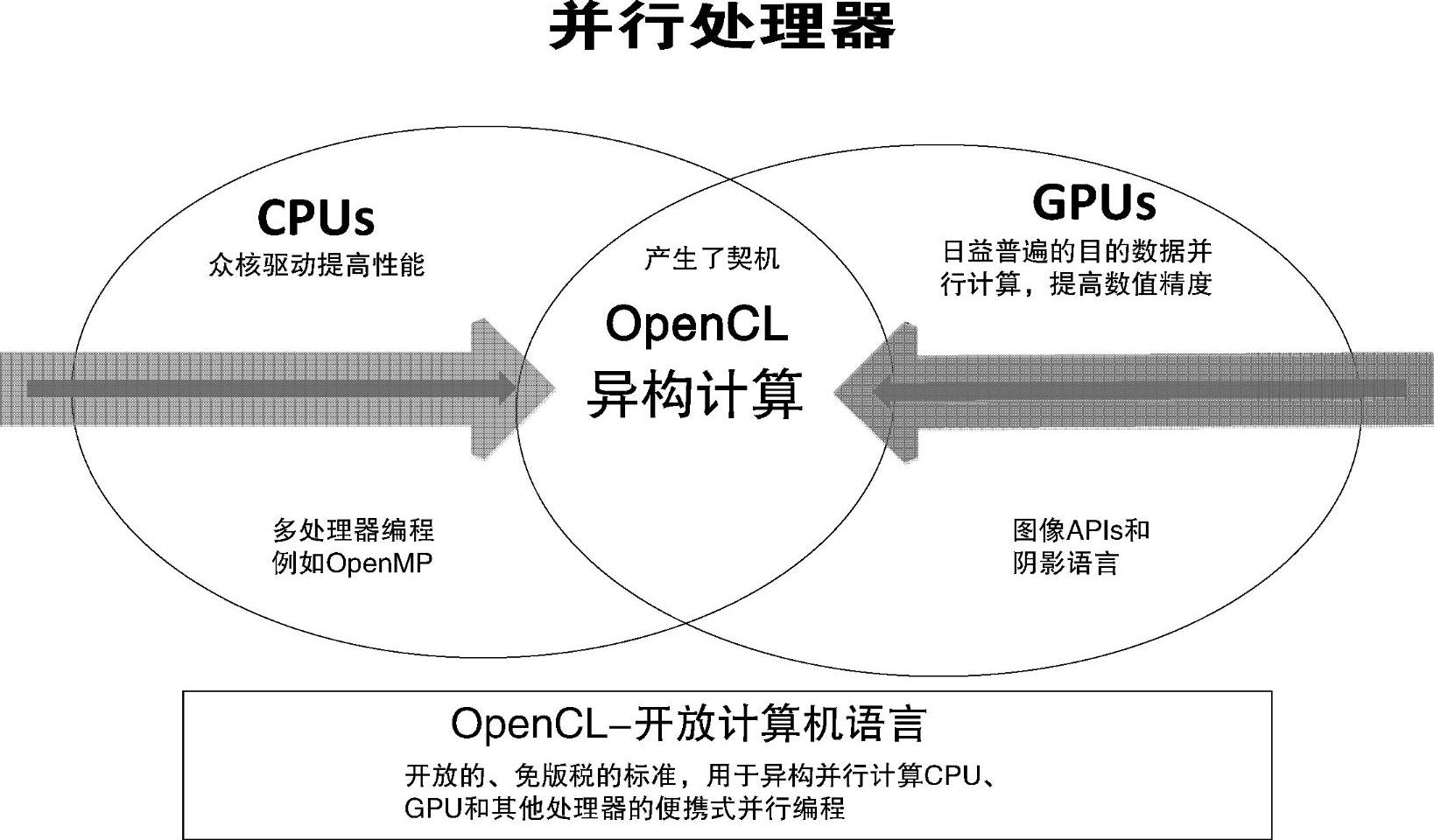
图1-3 OpenCL适用于异构平台
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





