【摘要】:基于对多个国内典型风电场数据的处理经验及参考国外相关文献可以看出,目前风电原始数据主要存在数据重复、失真及缺失这三个问题。表2-1 浙江省某风场风速数据缺失情况以及数据完整率针对数据重复、失真和缺失这三大问题的判断依据及处理原则可参考表2-2表2-2 判断依据及处理原则其中,判断数据失真的判据,仅考虑了数据的采样时间间隔大于等于1min的情况,判断原则为超出边界条件或连续多个数据相同且不为零。
基于对多个国内典型风电场数据的处理经验及参考国外相关文献可以看出,目前风电原始数据主要存在数据重复、失真及缺失这三个问题。
进行数据预处理的第一步,首先依据GB/T 18710—2002中计算原始数据的完整率的方法评价原始数据样本的完整率,计算公式如下:

式中,应测数目为测量期间小时数;缺失数目为没有记录到的小时平均数;无效数据数目为确认为不合理的小时平均值数目。
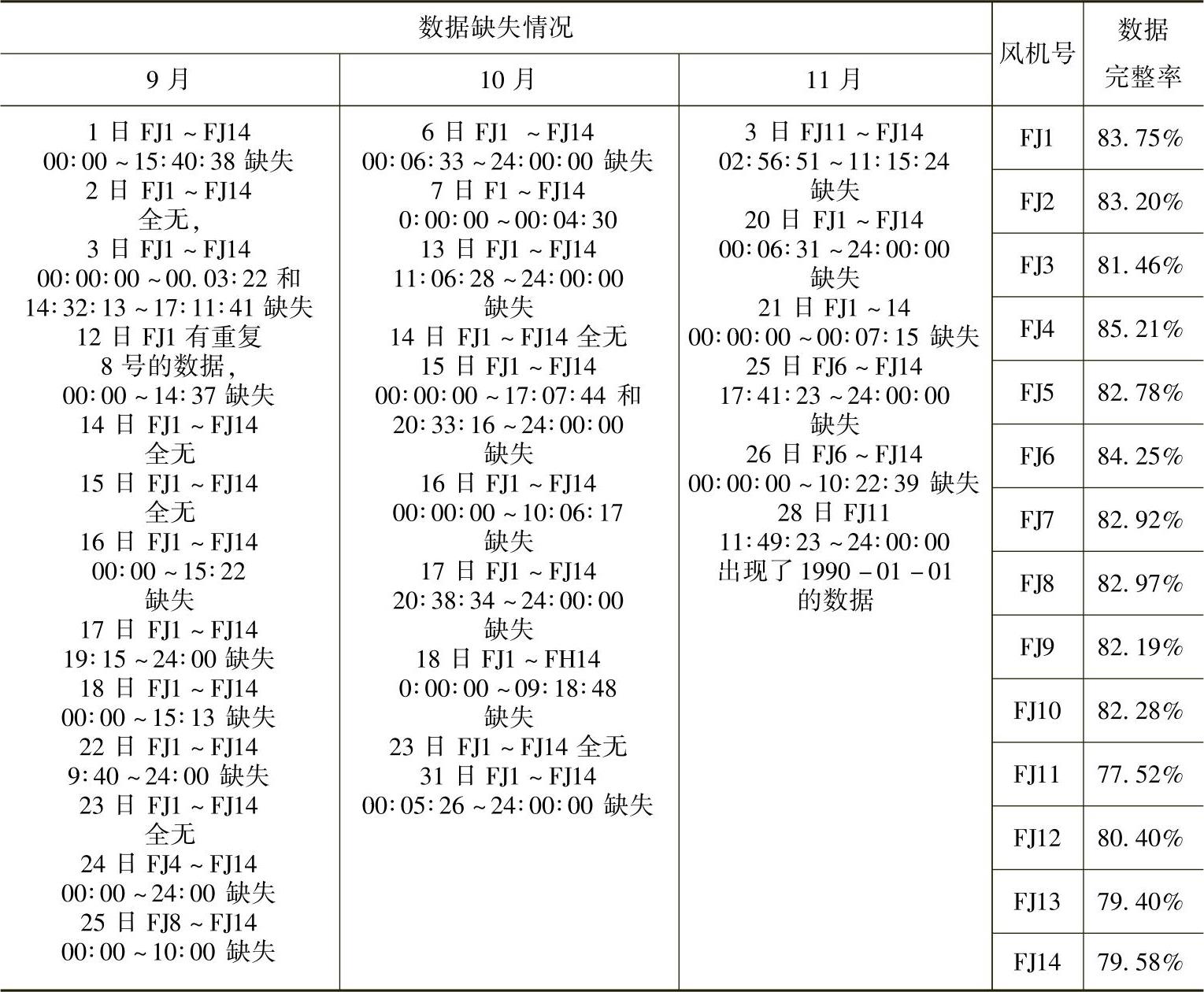
以浙江省某风场风速数据样本为例,该数据样本含2009年9~11月期间风机FJ1~FJ14的风速数据。每两个风速数据的采样时间间隔为30s,其中存在缺失数据情况,参照GB/T 18710—2002,缺失数据统计结果见表2-1。
表2-1 浙江省某风场风速数据缺失情况以及数据完整率
 (https://www.daowen.com)
(https://www.daowen.com)
针对数据重复、失真和缺失这三大问题的判断依据及处理原则可参考表2-2
表2-2 判断依据及处理原则
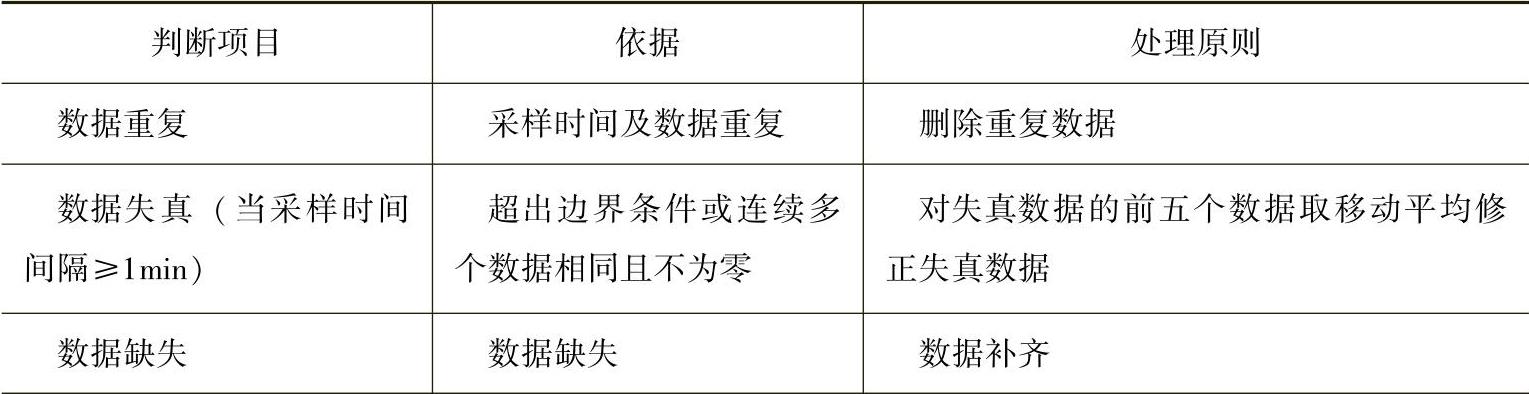
其中,判断数据失真的判据,仅考虑了数据的采样时间间隔大于等于1min的情况,判断原则为超出边界条件或连续多个数据相同且不为零。风电出力数据的边界条件为[0,装机容量],风速数据的边界条件为[0,40](参考GB/T18710—2002《风电场风能资源评估方法》)。考虑到风速和风力发电机出力的间歇波动性,数据采样时间间隔不小于1min时,正常情况下,不会出现连续多个相同且不为零的数据,可通过对失真数据前面的连续五个数据取移动平均修正该失真数据。
在数据预处理过程中,针对缺失数据的处理较繁琐而且重要,在下一节中将重点介绍。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






