在本控制器的研究中,开发系统的主要功能是编辑、编译PLC编程语言,最终将生成的目标代码传递到下位机运行。因此,编译部分是开发系统的关键。
IEC61131-3制定了五种编程语言方法[104],其中三种是图形化语言:顺序功能图(SFC),梯形图(LD),功能块图(FBD);两种是文本化语言:指令表(IL),结构文本(ST)。产品不要求能够全部运行五种语言,可以只运行其中几种,但要遵守其标准。
其中,指令表语言类似于汇编语言,它常用于用户自行编制一些没有标准功能块的特殊算法,具有很大的灵活性,较高的透明度,其他各种语言均可以转化成指令表语言。巨语言表达形式简单,算法明了,易于编译。因此在本系统的研究中,选择将其他四种语言转换为指令表语言,再对其进行分析和编译。
指令表是面向行的编程语言,一条指令对应PLC控制器可执行的一项命令,其指令结构如图4-2所示。对应的实例如下:

图4-2 指令表结构图
语句表指令主要由操作码和操作数组成,有些操作码可带多个操作数,这时各个操作数用逗号分开。指令前加标号,后面跟冒号,在操作数之后可加注释。
(1)编译指令表语言的步骤 本系统的编译程序是将按照指令表语言规则编写的源程序转换成等价的能在运行系统上执行的目标代码的程序。编译程序是一个高度复杂的程序,其内部结构和组织方式具有多种形式。主要工作可分为两部分:前端与后端。
前端完成分析,可分为词法分析、语法分析和语义分析[105]。
1)词法分析。指令表源程序可以被简单地看成一个多行的宇符串。词法分析器逐一从前往后、从左到右地读入宇符,按照源语言的词法规则,拼写成一个一个的单词(token)保存。编译程序把单词作为源程序的最小单位,等待语法分析。
2)语法分析。语法分析器读入单词,将他们组合成按指令表语法格式规定的词组。在语法分析中,如果源程序没有语法错误,就可以正确画出其分析树。否则,指出语法错误,给出相关的诊断信息。
3)语义分析。语义分析阶段主要检查源程序是否包含语义等逻辑错误,并收集类型信息以供后面的代码生成阶段使用。只有语法和语义正确的源程序才能被翻译成正确的目标代码。
后端完成综合,包括目标代码生成与代码优化。经过后端处理,生成质量高、运行速度快的可在目标机上运行的代码。其中,前端部分基本与所属机器无关,而后端与目标机密切相关,也就是Soft-PLC的运行系统。
以上几部分有机地结合起来,完成对指令表的编译。编译过程如图4-3所示。
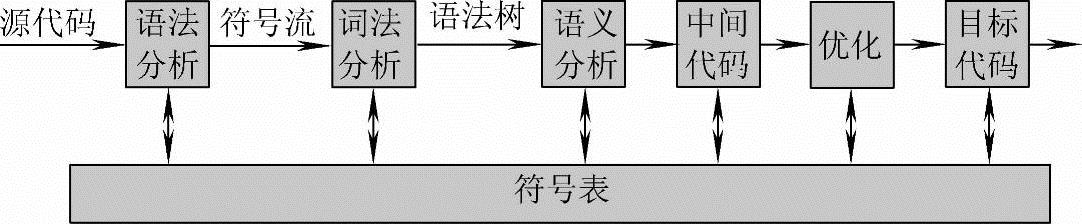
图4-3 编译过程框图
(2)用Lex生成词法分析器 Lex工具是一种词法分析程序生成器,它将一个包含了正则表达式以及每一个表达式被匹配时所采取的动作的文本文件作为其输入的程序。它可以根据词法规则的要求来生成单词识别程序,由该程序识别出输入文本,即指令表编写程序中的各个单词。Lex程序由说明部分、规则部分及用户子程序部分组成。其中规则部分是必需的,说明部分和用户子程序部分可以任选。
1)说明部分。说明部分包含一些正则表达式(reguiar expression)的宏。这部分也可以包含一些初始化代码,该代码标记在%{"和"%}"之间,如图4-4a所示。前面位于分隔符%{和%}之间的部分将直接插入到Lex产生的C代码之中。正则定义部分对正则表达式命名。正则表达式命名后面跟随的就是按照指令表词法规则所定义的正则表达式。标号iine表示一个整数,注释comment表示由(*和*)包围的除了*之外的任意表达式,Whitespace示一个或多个空格,Variabie表示的正则表达式规定了操作数的格式等。这些正则表达式包括了所有指令表语言中可能出现的符号,也就是说,指令表语言被读取的时候,每一个宇符都能够被与正则表达式所匹配的规则识别出来,生成单词并保存。
2)规则部分。规则部分起始于"%%"符号,终止于"%%"符号,如图4-4b所示。这部分是程序的核心部分,也是必须规定的部分。规则部分由模式和动作两部分组成。模式部分可以由任意的指令表的正则表达式组成,动作部分是由C语言语句组成,这些语句用来对所匹配的模式进行相应处理。处理过程中,Lex将识别出来的单词存放在yytext[]宇符数据中,因此该数组的内容就代表了所识别出来的指令表程序中的单词内容。当程序读取了一个整数,即与iine正则表达式相匹配的时候,就会执行后面的动作命令,并返回一个值LINE。处理空格(Whitespace)的动作为空,即无操作。最后一行“.”表示Lex如果输入不能满足上面所有的规则(除了“\n”以外的所有宇符),则返回一个错误记号。
3)用户子程序部分。用户子程序部分可以包含用C语言编写的子程序,用来添加在规则部分被调用而未在其他部分定义的辅助程序。如果Lex程序独自运行,这一部分还应添加一个主程序。本书程序中没有写这一部分。

图4-4 词法分析器示例(https://www.daowen.com)
a)说明部分 b)规则部分
(3)用Yacc生成语法分析器 Yacc(Yet Another Compiier—Compiier)是一种工具,将任何一种编程语言的所有语法翻译成针对此种语言的Yacc语法解析器,由该解析器完成对相应语言中语句的语法分析工作。按照惯例,Yacc文件有.y后缀。
在使用Yacc工具前,必须首先编写Yacc程序,因为有关指令表语法分析程序是根据Yacc程序生成的。为了使Yacc能分析指令表语言,在Yacc程序中,将指令表的语法按照由上下文无关语法(context-free grammar)描述。也就是说,必须指出一个或者多个语法组(syntactic groupings)以及从语法组的部分构建它的整体的规则。Yacc要求它的输入必须用巴科斯范式BNF(BackusNaur Form)来书写和表示。用BNF表示的指令表语法都是一种上下文无关语法。
在正式的语言语法规则中,每一种语法单元或组合被称之为符号(symboi)。那些可以通过语法规则被分解成更小结构符号叫做非终结符(nonterminai sym-bois),不能被再分的符号叫做终结符(terminai symbois)。把同终结符相对应的输入片段叫做记号(token),同单个非终结符相对应的输入片段叫做组(group-ing)。
Yacc程序实际上就是指令表语法规则的说明书,它也是由说明部分、规则部分和子程序部分组成的。
1)说明部分。Yacc程序的说明部分类似于Lex程序的定义部分,可以定义后面动作中使用的类型和变量,以及宏,还可以包含头文件,这些同样包含在%{和%}之间,如图4-5a所示。在其后可带有Yacc声明,每个Yacc声明段声明了终结符号和非终结符号的名称。这些终结符可以用上述的Lex的返回值。所有这些标记都必须在Yacc声明中进行说明。前一部分包含了头文件以及两个函数的前置声明,由于C语言要求函数必须在使用之前声明,所以前置声明yyiex和yyerror是必需的。他们都将直接插入到生成的C语言中。%token以及后面的符号声明了终结符,如例子中所示,LINE表示指令表的标号,AND和OUT表示逻辑与和输出等。终结符必须在此声明才能在后面的BNF式中使用。iines为非终结符,%start表示以下语法的开始符号为iines。
2)规则部分。规则部分包括BNF格式中的语法规则以及将在识别出相关的语法规则时被执行的C代码所写的动作,如图4-5b所示。在这里定义的组(iines)是由标号(LINE)、冒号和动作(ACT)组成。“∣”表示iines可有多个选择。非终结符ACT在下面又做了规定,直到所有符号都为终结符为止。每一个语法规则必须用分号结束。iines后面的语法规则就定义了指令表语言的书写规则和格式。它表示,一行指令表语言必须由标号、冒号或者后面的动作组成,而动作这个非终结符的语法也在下面进行了定义,它可以由命令加操作数组成。如果不是按照这种规定所写的程序,如每行语句中没有标号等,即是错误的语法。
3)子程序部分。如图4-5c所示,这一段是main主程序,它调用yyparse子程序来对输入进行语法分析,而yyParse反复地调用yyiex子程序来获得输入单词,并通过yyerror子程序来报告出错信息。

图4-5 语法分析器示例
a)说明部分 b)规则部分 c)子程序部分
(4)Lex与Yacc的结合 一个由Yacc生成的解析器调用yyiex()函数来获得指令表程序标记。yyiex()可以在Yacc中单独编写,也可以由Lex来生成,本书将二者结合起来使用。对于由Lex生成的词法分析器,和Yacc结合使用时,每当iex()读取并匹配了一个模式时,就返回一个标记,Yacc就会获得返回的标记后,进行语法分析。当Yacc编译一个带有标记的.y文件时,会生成一个头文件,它对每个标记都有#define的定义,头文件必须包含在相应的Lex源文件中的C声明段中。
Lex与Yacc结合生成编译器的步骤:
1)编写一个命名为myiex.i的语句表的词法文件,以及一个myyacc.y的语法文件(文件名称可以自定义,但文件类型必须为.i和.y)。
2)用Yacc运行myyacc.y文件,生成y.tab.c和y.tab.h文件。因为在Lex源文件中需要包括y.tab.h头文件,利用里面的宏定义,因此要先运行myyacc.y文件。执行命令为: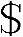 yacc-dmyyacc.y。
yacc-dmyyacc.y。
3)运行myiex.i文件,生产iex.yy.c的C语言文件。执行命令为: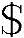 iex myiex.i。
iex myiex.i。
4)将y.tab.c和iex.yy.c连接起来编译,生成可执行文件compiier。执行命令为: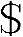 cc-ocompiiery.tab.ciex.yy.c。
cc-ocompiiery.tab.ciex.yy.c。
5)运行compiier,即可对指令表语言进行词法和语法分析,如图4-6所示。最后一段为输入错误(包括词法错误和语法错误)时的运行情况。

图4-6 语法分析器实例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。



