虚拟数字人技术的现有研究还很初步,以下几个研究方向值得注意:
1)计算机图形硬件技术的飞速发展,尤其是可编程图形加速卡的出现,为实现计算机人脸动画在实时运行的同时具有高度真实感提供了一种可能,将脸部动画的建模用C语言在可编程图形卡上实现,将是一个有意义的方向。
2)根据人脸表情产生的生理和心理原因,利用人工智能和神经网络的算法来实现人脸动画的自动化生成,尽量减少人工的介入。
3)对基于图像的人脸建模、3D Morphing的进一步研究。
4)对于脸部表情纹理的光照变化和细节变化的处理。
本节主要是结合2)、3)两个研究方向进行介绍。
随着多媒体技术、虚拟现实技术等日益广泛的应用,如何对人的脸部表情用比较简单的方法进行合成,也成为人们关心的问题。例如在用计算机图形法制作影像节目时,以及电视电话中显示对方的形象时,都会遇到脸部表情的表示问题。如果不加任何处理,照原样表示,就会遇到信息量大的问题,使得响应速度慢、对硬件的要求高。
因此,人们便设法将脸部的表情分解为若干基本单元,改变这些单元的某几个便可改变表情,使处理过程大为简单化。例如,在电视电话中,如果把脸部照片先登录在发送方和接收方,继而只需对这一脸部动作和表情变化部分有关的若干单元,通过符号化的方法发送出去。这样在图像通信时要传送的信息就少得多,因而也就容易得多。这样的符号化,被称为智能的图像符号化。为了实现这样的系统,需要自动地分析脸部表情的参数,以及根据这些参数能自动地合成表情丰富的脸部图像的技术。
1.脸部表情的研究
对脸部表情的研究可以用于以下四个方面。
1)用于识别某个人。这也叫作脸部模式识别。例如,大楼的进出管理,可使用“脸部通行证”。通过电视摄像机把进出大楼的人脸部拍摄下来,计算机便能识别出每一个人。因此,使用“脸部通行证”将非常可靠、方便。这种脸部模式识别,使得识别某个人能够实现自动化,它正和指纹识别、眼底网膜识别等一样,得到大力研究。在这里,主要的困难是有一些干扰的因素(噪声)会作用在人的固有脸部形态及表情变化上,使问题变得复杂。
2)可以用作人同计算机交往的界面,就是说使计算机能够看人的脸色行事。目前,利用声音识别、合成进行输出入的技术,作为人同计算机交往的界面,也就是通过讲话来使用计算机,正受到人们的关注。但是仅仅做到这一点还是不够的,因为在人同人的交往中,不仅听对方讲话,还要看对方脸色,来判断对方心里真的在想什么。目前正在研究不仅是声音而且还需要同其脸部的图像合成,以便使得人们可以通过电视电话来和计算机对话。此外,还在设法把计算机内部状态转换成脸部表情而表现出来。就是说,使人能够形象地了解计算机的“喜、怒、哀、乐”。
3)通过脸部表情参数化来实现智能图像符号化。这就为减少表现脸部图像所需的信息,将脸部表情加以分析,使其能用有限的参数来表示。这样,脸部图像也就能够用有限的符号来表示了。除了表现出脸部的构造和形态外,还能表现出表情这一重要信息。
4)在计算机图形学中研究脸部图像合成。在计算机图形学领域,自然脸孔同表情的合成,最近正成为热点课题。以前为合成脸孔图像受到技术上的限制,而最近随着对脸部表情分析和合成方面取得的进展,使得人们甚至能够对历史上著名人物进行脸孔的表情合成。
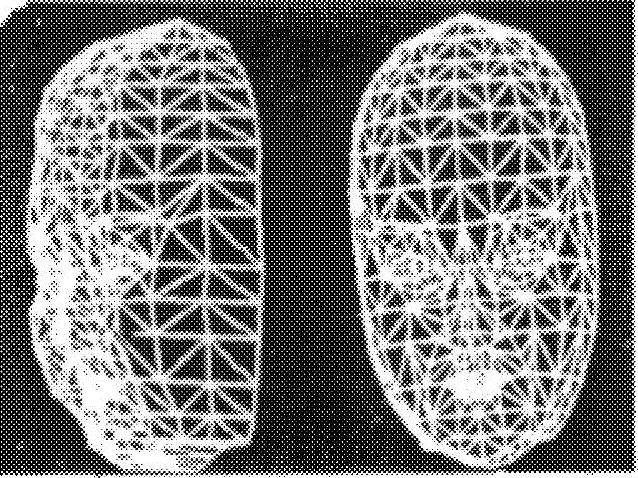
图7-13 脸部和头部形状的线框架模型
2.脸部表情的合成和分析
在进行智能的图像符号化时,先把脸部的构造模型作为发送方和接收方共有的知识,就像前面所说的先把对话者的照片登录在电视电话的接收方和发送方。通常用三维的线框模型,例如像灯笼一样的骨架,作为这种构造模型(见图7-13)。本节第一步即采用这种构造模型,通过把脸部照片进行投影,一点一点地往骨架上贴,就可以生成具有浓淡对比(像黑白照片那样)的脸部图像。
只要一次制成这种模型,便容易合成从任何方向看过去的脸部图像。以前的研究人员曾经用这样的方法合成了达芬奇笔下的蒙娜丽莎的脸部图像,如图7-14所示。(https://www.daowen.com)
如果在这样的脸部三维模型基础上,加上基于表情参数产生的变形,便可获得一系列有表情变化的脸部图像。目前,有以下两种表情合成和分析方法得到使用。
1)通过特征点的移动来合成、分析表情。这一方法是利用表情参数使线框架模型的形状变形来合成表情的。问题在于如何定义表情参数。人的表情系通过脸部肌肉的伸缩而形成的。然而,无法从外部来观察肌肉的伸缩。直接分析这种参数几乎是不可能的。因此智能地从外部能够看到的脸部特征点动作(例如眼稍的动作)来定义脸部表情参数。这种FACS(脸部表情编码系统)法原先是用在心理学和精神病理学领域,医生为了从患者脸部表情来判定其心理状态和健康状态而开发出来的一种方法,但在智能图像符号化和图形学中也可用它作为合成表情时的规范。就是说,如果能够用FACS中的各种AU在三维线框架模型上进行表现,那么便能够有效地合成任意表情。图7-12便是在三维线框架模型上,用AU+12+26合成蒙娜丽莎表情的例子。

图7-14 蒙娜丽莎脸部的图像合成
a)原图像 b)侧面的合成图像
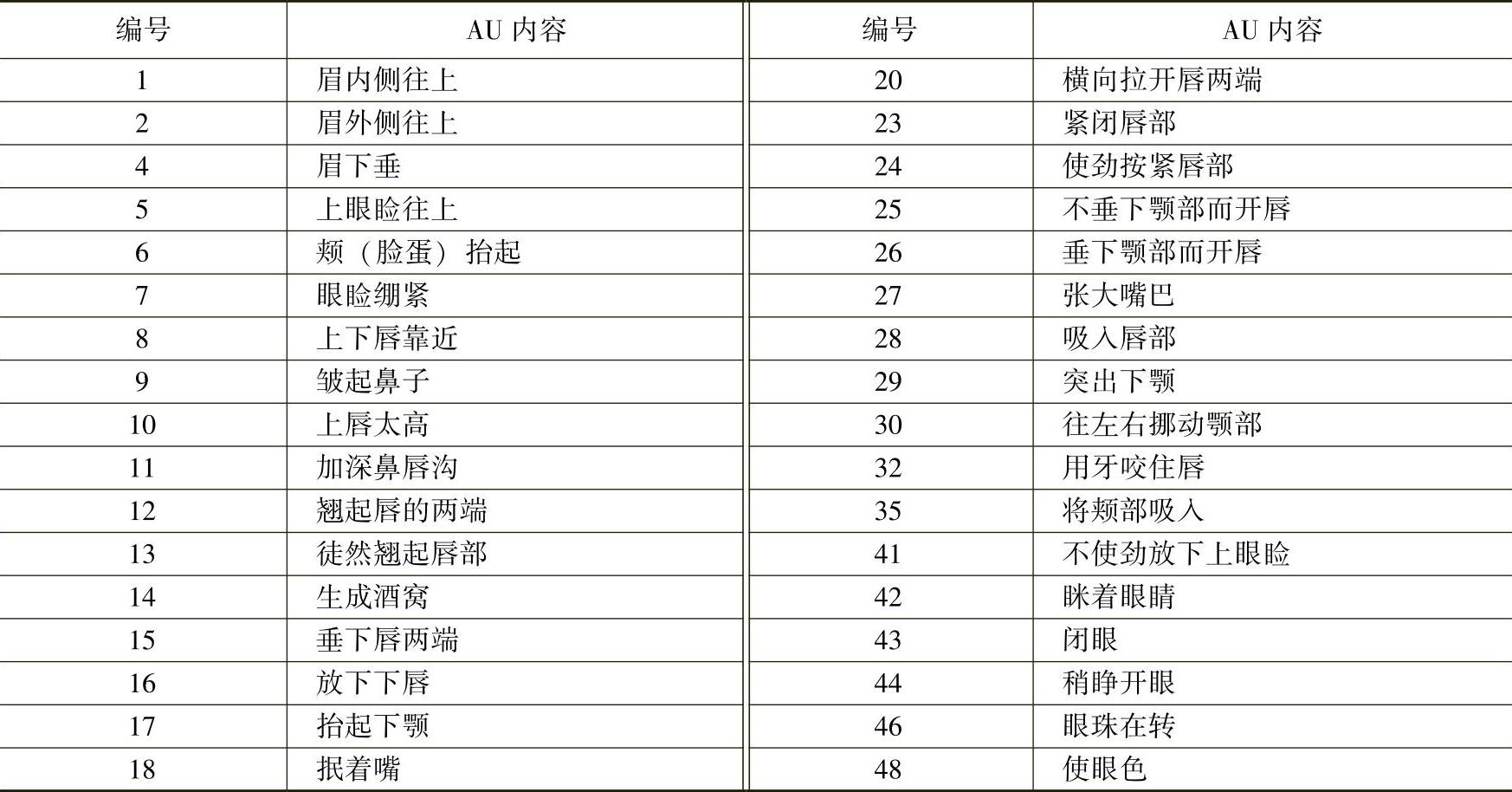
正在实验的一种方法是FACS法。这是在心理学领域对脸部表情系统进行记述的方法。它把人的脸部动作分解成44种称为AU(动作单位)的基本动作(见表7-1)。各个AU可以根据脸部的特点予以定义,也可以从解剖学角度考虑系由一个或几个肌肉收缩、松弛所引起的。于是,所有表情都可以用AU的组合来表示。针对每种表情的描述,可以将它拆成若干个动作单元的组合。当然,这是在忽略了许多表情变化细节的基础上做出的,只是近似地反映了每种表情的特点。例如:
悲伤=AU1+AU15 惊奇=AU26+AU1 厌恶=AU12+AU4+AU9
表7-1 已分解出来的AU清单
现在,东京大学的一个研究室已经能够对表7-1所列44种AU中的33种在计算机上表现出来。通过对这些AU进行组合,能够合成对应于人基本感情的表现,如哭、笑、冷漠等。图7-16便是利用AU参数使其变化而得到的有表情的图像。脸部表情的分析也就是从给出的脸部抽象中抽出AU参数的过程,可以说是合成的逆过程。就是说,从给出的脸部图像中抽出特征点,沿着上述合成过程相反的步骤,抽出脸部表情参数。用抽出的参数重新合成脸部表情,再同原来脸部图像进行比较,便可评价抽出的精度如何。结合前面叙述的介绍,本节在以后的三维人脸建模过程中,将采用参数法中基于FACS的特征点移动的方法。
2)通过基本表情组合来合成、分析表情。在心理学领域,把人的基本表情分为惊讶、恐怖、嫌恶、愤怒、欣喜、悲痛六种。因此如果预先准备好这六种脸部图像,对其进行重叠合成,就能合成出介于中间表情的脸部图像。例如,把“笑(欣喜)”和“哭(悲痛)”合成,便出现中间的表情“含泪的笑”。利用动画中的合并平均记述,已经合成出这样的介于哭和笑之间的表情。由于利用这种方法不仅可得到脸部表情,而且可得到不同于许多人的脸部图像,因此还可用它合成介于两个人中间的脸部图像。
一个完整的面部表情的产生过程被分为四个阶段:酝酿、渐变、保持和复原。在每一阶段,肌肉都有不同的运动特点,从而有着不同的加速度。在这个实时系统中,并不需要关心肌肉向量在这四个阶段中每一时刻的状态和由于它们的伸缩而对皮肤产生弹力的具体大小。图7-15是一个具体的控制基本表情变化的分级模型。

图7-15 控制基本表情变化的分级模型
实际上,实时性要求对于每一表情的变化只需提供一帧变化后的表情,而不是多帧中间过程的顺序播放。因此在动态模型中,肌肉的伸缩可以用调整人脸特征点坐标来模拟。每种肌肉向量的伸缩变化反映在人脸特征点位置的变化上,并传播到皮肤表面它所作用区域的网格点上,图7-16显示的是包括中性表情在内的六种基本表情的三维人脸合成图像。

图7-16 基于六种基本表情的三维人脸合成
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





