近年来,随着网络应用的日益广泛,人们之间的交流方式也在发生改变。从面对面地交谈、打电话,到网络聊天、互发电子邮件,人们越来越趋向于在虚拟网络世界中进行交流。人脸是人类相互交流的重要渠道,是人类喜、怒、哀、乐等复杂表情和语言的载体。随着计算机图形学在建模、渲染和实时动画等方面的发展,人脸建模和动画在电影虚拟角色、远程会议、犯罪学、医学、信息帮助、人机交互、娱乐、虚拟现实、人脸识别和表情理解等方面取得了广泛的应用。传统的人脸模型多是通过昂贵的计算机断面成像(CT)、核磁共振、三维激光扫描等设备建立起来的,模型复杂,精确度高。而对于人们在虚拟世界中进行交流这个应用来说,更希望以小的代价来建立相对不是那么精确的人脸模型。因此,可以利用人的正面和侧面的照片合成具有一定逼真度的三维人脸模型,并在这一模型上实现眨眼、抽鼻子、微笑、蹙眉、短语句的发音等简单动画。
人们研究虚拟人脸已经有近20年的时间了,它们主要在实验室中,用来模拟真实人脸的运动和行为。直到最近,虚拟人脸开始应用于娱乐和商业领域,比如电影、游戏和虚拟播音员和节目主持人等。在新一代分布式信息系统中,融识别、合成、动画技术的多模态的人机接口是其基本特点。
人脸建模动画研究可以分为两个方面:以几何处理为基础的和以图像处理为基础(见图7-8)的。每个领域又包含更深层次的分类。几何处理包括关键帧和几何插值、参数化、有限元方法、基于物理学的肌肉模型、可视的伪肌肉模型、样条模型和自由形式变形。图像处理包括在照片图形图像、纹理处理、图像混合及血管表示之间的图像变形。在预处理阶段,对于特定人的独立模型可以通过人体测量学、离散数据插值,或将目标和源网格投影到球形和柱形坐标中的方法来构建。这种模型的构建通常是通过特征跟踪或基于性能的动画来完成的。
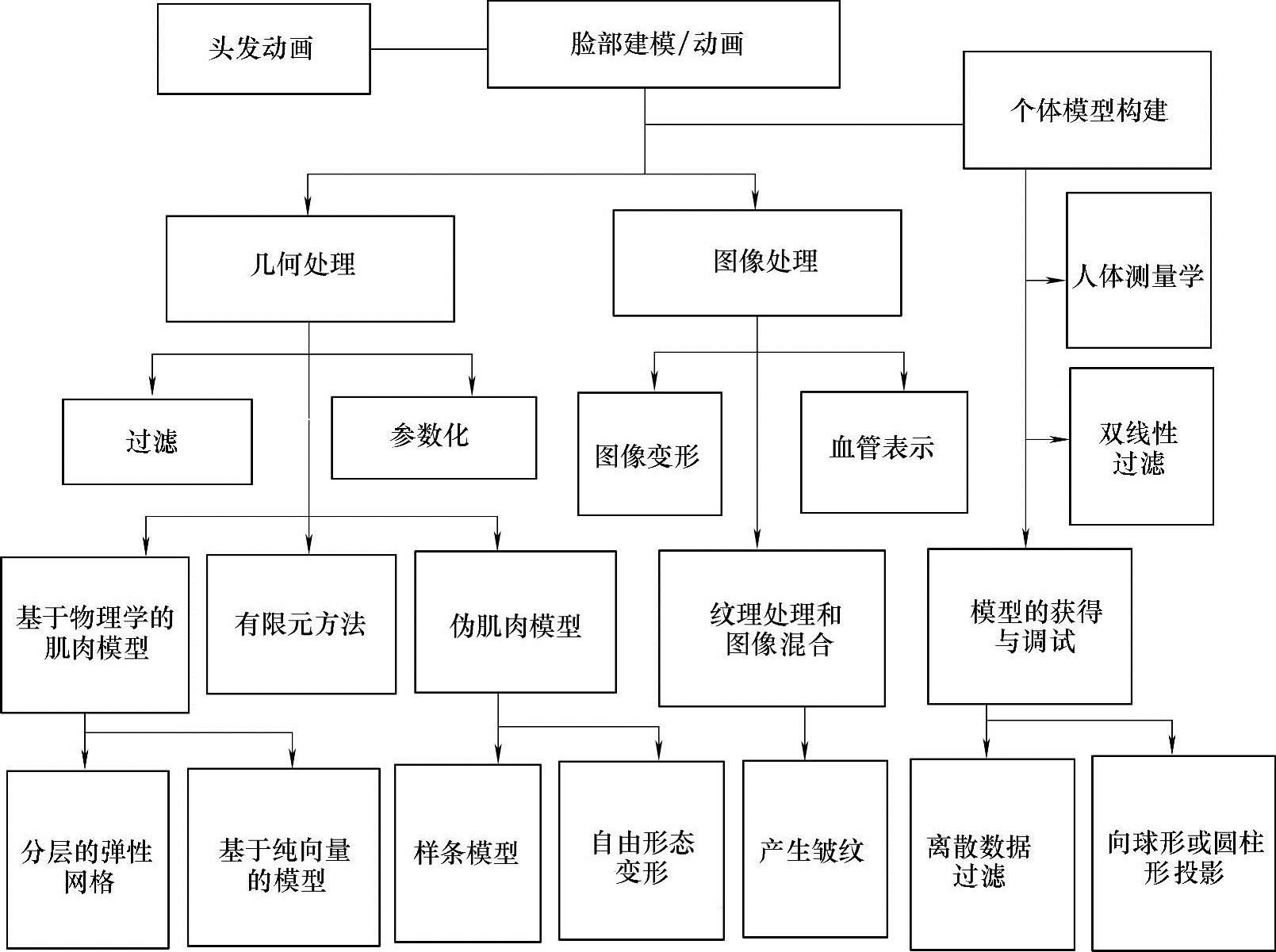
图7-8 人脸动画分类
人脸作为人的最重要外部特征,在人与人的通信交流过程中起着非常重要的作用。它能够通过传递许多非语言的信息来加强理解或表达情感。真实感的计算机人脸动画是计算机图形学领域最基本的问题之一。同时,由于人脸生理结构十分复杂及人们对人脸的细节变化十分敏感,它也成为最困难和最具挑战性的问题之一。但是,计算机人脸动画有着广泛的应用领域,它既可以用来制作虚拟现实环境中的各种虚拟人物;又可以用来制作和传输网络媒体,如虚拟播音员、可视电话、远程网络会议等。另外,它在电影制作、游戏娱乐、医学美容等方面都有着很好的应用前景。正是由于计算机人脸动画有广泛的应用领域,所以它引起了研究者们极大的兴趣。自从Parke在1972年开创这个研究领域以来,30多年中,研究者们在该领域做了大量的研究工作,并取得了很大的进展。近些年来,随着计算能力的飞速提高和网络应用的蓬勃发展,这一领域再次成为研究的热点。
(1)计算机人脸建模 计算机人脸建模工作包括两个过程:构造人脸模型和纹理的处理(生成真实感的人脸)。而构造人脸模型过程又包括脸部数据的获取和脸部模型的表示等两项工作。纹理处理的目的是为了增强模型的真实感。它包括纹理的生成、光照的处理和脸部细节的处理等工作。人脸建模同时要表现出与人脸部有联系的组织和器官的特征、形状、变形和运动,人脸形状的复杂性和人们对于人脸细节的敏感性使人脸建模成为一项困难而又费时的工作。因此,在进行人脸建模时,应根据具体的应用要求,选择合适的建模方法。
1)脸部数据的获取 一般来说,人脸建模有两种数据来源:2D输入和3D输入。3D数字化扫描仪是最直接和常用的3D输入设备。用这种方法,数十万个深度和反射样本数据能够在几秒钟内得到。Waters和Terzopoulos使用此方法来构造脸部模型。这种方法的缺点是设备过于昂贵,且得到的纹理图像的分辨率不是很高。另一种3D输入方法是使用3D跟踪仪。使用这种方法,网格或特征点被直接置在真人的脸上,然后通过使用3D数字化扫描仪得到网格点或特征点的3D坐标。这个过程不是自动的,通常需要手工的介入,因此相当费时。对于2D输入来说,最常用的方法是通过对立体图像进行摄影测绘来确定人脸模型:先从不同角度得到对象主体的两张脸部图像,然后在两张图像间确定点对点的对应关系,并得到点的3D坐标,最终结合两张图像得到人脸模型。另一种方法是基于一张人脸的正面图像,利用人体测量学研究成果,得到人的脸部模型。在数据来源方面,本节采用的是2D数据的输入。
2)脸部模型的表示方法 人脸不同生理层之间的相互作用,使模拟人脸变形成为一项非常复杂和困难的工作。同时,对于人脸变形的模拟也依赖于脸部模型的表示方法。因此,将脸部模型的表示和变形方法分开是很困难的。通常,人脸模型是几何表示和变形方法的结合体。因此,在选择脸部模型的表示方法时,应考虑应用的要求和变形方法。脸部模型的表示方法大致可以分为多边形表示法和曲面表示法两类。多边形表示法通常采用矩形网格和三角形网格来表示模型。与多边形表示方法相联系的脸部变形方法有关键帧插值、参数法、基于物理的肌肉变形方法、伪肌肉变形法等。尽管多边形表示法在各种脸部模型中被广泛使用,但它们却常常不能很好地表现人脸部的平滑性和弹性。曲面表示法为此提供了一个很好的解决办法。曲面表示法包括样条模型和有限元素模型等。与曲面表示法相联系的变形方法有参数法、基于物理的肌肉变形法、伪肌肉变形法等。在人脸模型的表示方法方面,本节采用的是多边形表示法中的参数法。
(2)真实感人脸的生成 在计算机人脸动画中,脸部表情细节的微小变化,如光照的变化、脸部皮肤颜色的瞬间变化、皱纹等,能够极大地增强人脸模型的真实感,同时能够传递更多的非语言信息。通常,脸部图像一般是由纹理或阴影(Shading)方法来得到颜色。Shading方法根据表面属性和光照模型来计算每个像素的颜色值。由于人对皮肤颜色变化的敏感性,简单的光照模型一般不能产生足够的真实感。纹理能够在每个像素实现表面属性的复杂变化,因此它能够在缺乏表面几何信息的情况下表现出细节。
1)纹理的获取 获取人脸纹理信息最直接的方式是使用3D数字激光扫描仪,但是得到的纹理图像的分辨率不是很高。另一种方法是从人脸的照片中获取关于人脸的纹理图像。这种方法首先得到一套关于主体对象脸部的照片,然后从中恢复出视点参数,最后依据已构造的脸部模型计算出脸部模型上每个顶点在纹理图像中的颜色信息。Pighin等人将一幅脸部表情纹理图像表示为已有关键脸部表情纹理图像的凸结合,通过分别分配不同的权系数融合这些图像产生新的纹理图像。在纹理获取方面,本节采用的方法是从人脸的照片中获取关于人脸的纹理图像。
2)光照变化的实现 利用纹理图像对脸部模型进行渲染能大大增强模型的真实感,但是纹理图像仅仅反映人脸被拍摄时的光照条件,这通常会引入不真实的效果。因此,对人脸在不同光照条件下脸部反射效果变化的处理,对于加强真实感具有很大的作用。基于熵图像技术,Marschner等人首先计算在新的和老的光照条件下得到的图像的颜色比率,然后用此比率对在老的光照条件下得到的另一张照片进行纹理处理,得到后者在新光照条件下的图像。
(3)计算机人脸动画 计算机人脸动画的目的是通过提供一个完整、简练的脸部动画过程控制模型,控制脸部模型之间的变形,模拟真实的人脸运动和表情转换。计算机人脸动画控制方法主要有以下几种:关键帧插值法、参数法、表演驱动法、基于物理的方法和基于肌肉的物理方法等。这些方法各自有自己的优缺点,并没有一个最优的方法。下面将分别介绍这些方法。
1)关键帧插值法 关键帧插值法是最简单也是最常用的脸部动画控制方法。它首先通过使用3D数字化扫描仪、立体图像摄影测绘法或使用光学扫描仪等三种方法之一得到一个离散的脸部形态集合。这些脸部数据具有相同的拓扑结构,能够在每个脸部形态上相应点之间建立一一对应的映射关系。两个脸部形态之间的中间形态可通过插值得到,如图7-9所示。线性插值方法由于其简单和直观的特性而被广泛使用。但是由于关键帧插值局限于所能得到的脸部形态,从而无法实现大量丰富的脸部表情合成表情,同时还不能实现脸部表情的直接控制,这促使了参数法的提出。

图7-9 应用线性插值后得到的人脸图像
2)参数法 为了克服关键帧插值法的缺点和局限性,Parke提出了参数法。在人脸参数模型中,考虑了两种参数:模型构造参数和人脸表情控制参数。通过确定关键参数集和插值其他的参数可以产生任意的脸部表情,并实现脸部表情之间的变形。参数的确定不仅影响模型的结构和大小,而且也影响表情的产生。表情参数和模型构造参数的分离使表情的产生独立于脸部特征。与关键帧插值法相比,参数法允许对脸部表情的直接控制,而且它可以实现大的数据压缩比,在低带宽的情况下,实现实时脸部动画。参数法的缺点是,在一个脸部表情向另一个脸部表情转化时,它不能一致、协调地处理在融合影响相同的顶点的表情时产生的参数冲突。
3)基于肌肉的物理方法 为了合成真实的人脸动画,基于肌肉的方法是根据人脸的生理结构,从生理的角度对人脸面部行为进行模拟的。根据解剖学的理论,人脸具有复杂的、层次性的生理结构,由头骨、肌肉层、覆盖的肌膜组织和外部皮肤层组成。头骨的形状决定了整个人脸的形状。头骨由14块主要的骨头组成,其中下颚骨是惟一的关节,牙齿是惟一可能看见的骨结构。人脸部表情的产生和皮肤的变形主要是由脸部肌肉运动所引起的。使人脸具有特定表情所涉及的主要肌肉有口轮匝肌、鼻肌、颧肌、眼轮匝肌、皱眉肌等。基于肌肉的方法根据对肌肉本身的生理构成和特性,以及肌肉运动与产生的脸部表情和皮肤变形关系的分析,通过动力学模型模拟肌肉的运动来生成真实的人脸动画。(www.daowen.com)
4)质点-弹簧系统法 基于目标对象的物理性质,质点-弹簧系统已被广泛地用于模拟可变形物体。它用由质点集组成的网格系统来模拟对象,并通过弹簧来连接质点。弹簧通常是线性的,但是非线性的弹簧也常被使用,以模拟对象的非弹性的行为。质点的运动服从于牛顿第二定律。整个网格系统的运动是通过结合所有质点的运动来实现的。在计算机人脸动画中,质点-弹簧系统已被广泛地用于模拟人脸部的表情变化。Terzopoulos和Waters将动态质点—弹簧系统用于人脸的动画。根据人脸组织的生理解剖结构,他们建立了一个三层质点网格结构,如图7-10所示。三个可变形网格层对应于皮肤层、脂肪层和与骨骼连接的肌肉层。肌肉收缩力通过网格层扩展,以产生脸部表情动画。
5)有限元素法 根据物体的几何结构、物理性质和应用要求的不同,有限元素法(FEM)将一个目标变形对象分解成由几个有限种元素组成的集合,以连续的方式模拟每个元素的变形。每个元素由一个插值函数来定义元素内的数值变化。各元素之间通过离散的节点连接、对节点和元素边界的限制,实现元素间的连续性。针对不同的应用要求和不同的对象形状,可定义不同的元素,这些元素是通过它们的节点数量和几何形状来定义的。与前面的两种方法一样,有限元素法也无法生成类似皱纹的脸部细节。
6)伪肌肉变形法 基于肌肉的物理方法为实现某个特定的人脸结构和动画,则需要大量的参数调整和精确的建模。伪肌肉变形方法忽略脸部复杂的生理结构,通过变形脸部网格来模拟脸部肌肉变形而实现人脸动画,可以作为基于肌肉的物理方法的替代方法。这里的肌肉变形可以是全局变形,也可是发生在脸部网格的一个相对小的区域内的局部变形。变形的方法有基于样条的、基于自由变形的等。
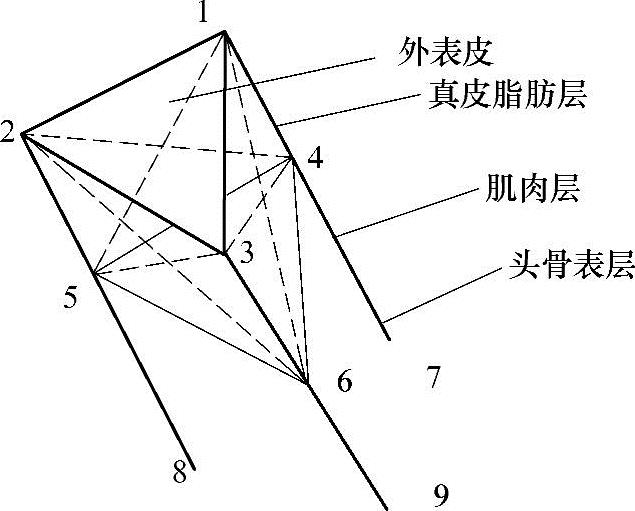
图7-10 分层网格肌肉模型
1,2,3—外表皮节点 4,5,6—肌膜节点 7,8,9—骨骼节点
注:虚线和直线均表明了节点之间的弹性网格连接。
自由变形方法:通过控制分布在三维立体栅格上的控制点来变形体对象,即把一个可变形体放在一个可变形的、包含3D控制点栅格的控制框架内。当控制框架被任意地挤压、弯曲、扭曲时,控制框架内部的变形体也相应地变形,如图7-11所示。自由变形既可以实现局部变形,也可实现整体变形,同时还可以控制变形前后物体体积的变化程度。自由变形方法的缺点是计算量大、网格的调整非常麻烦,为获得合适的物理形状,需要仔细地选择和移动许多控制点。其主要的改进方法有直接控制的基于加权狄里克利的自由变形造型(DFFD)、有理自由变形技术(RFFD)、基于NURBS的自由变形技术等。
用样条实现的伪肌肉变形方法:一个理想的脸部模型应该有一个支持平滑和灵活变形的表面。样条肌肉模型为此提供了一个很好的解决办法。样条通常有C2的连续性,因此一个小面片可确保是平滑的且允许局部变形。进一步,仿射变换能够通过一小部分控制点的变形来定义,而无须通过整个网格点来定义,这就降低了计算的复杂性。一个分层的样条模型减少了一些不必要的控制点的个数。Wang[18]等显示了一个将分层样条模型与基于区域表面变形的模拟肌肉模型相结合的系统。之所以使用双立方B样条是因其提供平滑性和弹性,而这些特点是传统的多边形模型很难达到的。然而,当要求一个变形比patch(面片)解决方案更加完善时,对复杂表面使用原始的B样条的缺点显而易见。为了产生更好的patch方法,表面的一整行或一整列需要被复分。这样,可以加入更多的细节(和更多的控制点)。对比而言,分层样条提供了对B样条表面区域的完善,而只在一个特定的区域内加入新的patch(见图7-12)。分层B样条是一种经济且简便的表示样条平面且获得高渲染速度的方法。带有分层样条表面的肌肉可以产生带有褶皱的皮肤表面以及各种面部表情。
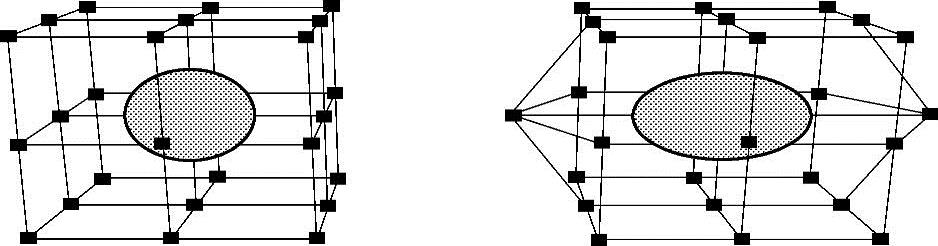
图7-11 自由变形方法
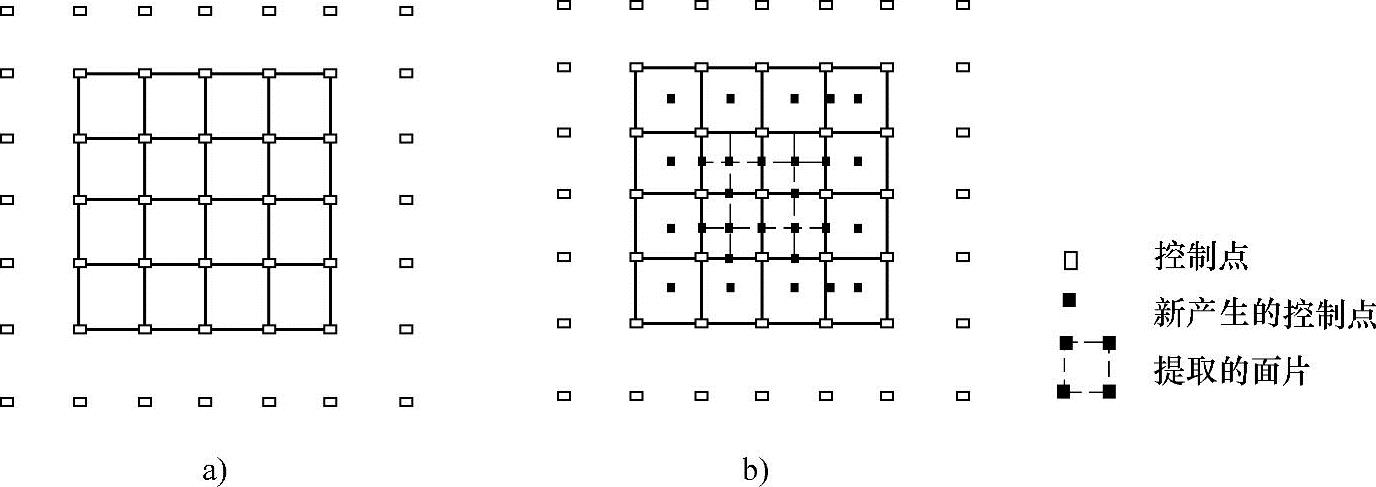
图7-12 控制点的表面和4条路径
a)显示了一个具有16个路径、49个控制点的表面 b)显示了中间定义的4条路径
7)表演驱动法 表演驱动(Performance to Driven)法又称为表情映射(Expression Mapping)法,也是一种流行的脸部动画方法。此方法捕捉在各种面部表情下真实人脸部的特征来驱动脸部模型而产生真实的脸部表情。常用的方法是在一个演员的脸上设置许多特征点,在演员表演各种面部表情时,捕捉这些特征点的运动向量,然后使用所得到的特征点的运动向量来驱动脸部模型的相应特征点而产生脸部表情。它提供了一种直观和有效的方式直接控制脸部表情的产生。动态轮廓模型(Snake)和光流跟踪(Optical Flow Tracking)的技术常被用来获取脸部的特征变化。这种方法可以和MPEG4(运动图像专家组4)标准相结合产生脸部动画,并能提高数据的压缩率。这种方法的缺点是,它仅仅捕捉了脸部特征的几何变化,而忽视了光照的变化,因此可能引入不真实的效果,而且此方法不能产生类似皱纹等脸部表情细节。
8)Morphing方法 Morphing(变形)方法实现两个指定图像和模型之间的变形转换。首先,在两个图像或模型上确定一套特征点集;然后用映射函数确定两个目标对象之间特征点集的相应特征点的点对点的对应关系;接着用Warpping函数确定中间图像的特征点的2D和3D位置或纹理空间的坐标值;最后,使用离散点插值函数产生其他非特征点的顶点的2D和3D位置或纹理空间的坐标值。Morphing方法有2D图像Morphing方法、视点Morphing方法和3D Morphing方法。从图像真实性出发,2D图像Morphing能够产生真实的脸部表情图像。但是2D图像Morphing的缺点是,它要求确定特征点之间的点对点的对应关系;其次,2D图像Morphing没有考虑对视点和对象姿势变化的处理,真实的头部运动无法实现。当视点和姿势发生变化时,产生不真实的脸部表情图像。为了克服2D图像Morphing的限制,Pighin[14]等人将2D图像Morphing和几何模型的3D变形相结合而实现3D Morphing。他们用3D几何插值来实现脸部表情之间的变化,用2D图像Morphing实现对应的纹理图像的变化。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







