基于区域的人体运动跟踪方法目前已有较多的应用,例如Wren[47]等利用小区域特征进行室内单人的跟踪,他们将人体看作由头、躯干、四肢等身体部分所对应的小区域块所组成,利用高斯分布建立人体和场景的模型,属于人体的像素被规划于不同的身体部分,通过跟踪各个小区域块来完成整个人的跟踪。
基于区域的人体运动跟踪的难点是处理运动目标的影子和遮挡,这或许可利用彩色信息及阴影区域缺乏纹理的性质来加以解决,如McKenna等首先利用色彩和梯度信息建立自适应的背景模型,并且利用背景减除方法提取运动区域,有效地消除了影子的影响;然后,跟踪过程在区域、人、人群三个抽象级别上执行,区域可以合并和分离,而人是由许多身体部分区域在满足几何约束的条件下组成的,同时人群又是由单个的人组成的,因此利用区域跟踪器并结合人的表面颜色模型,在遮挡情况下,也能够较好地完成多人的跟踪。
有人提出了一种新的方法来进行人体运动跟踪。该方法不针对特定人体运动方式,能对复杂、变化背景中的人体各部位的大幅度运动进行跟踪。下面结合一个人体跟踪的例子来具体阐述基于区域跟踪的设计理论和实现方法。
其基本思想是在建立人体模型的基础上,按自上而下的顺序依次跟踪人体各部分,并在其中采用了基于图像差分的运动预测和分区域直方图相似度算法。该过程的整体框架如图5-2所示。
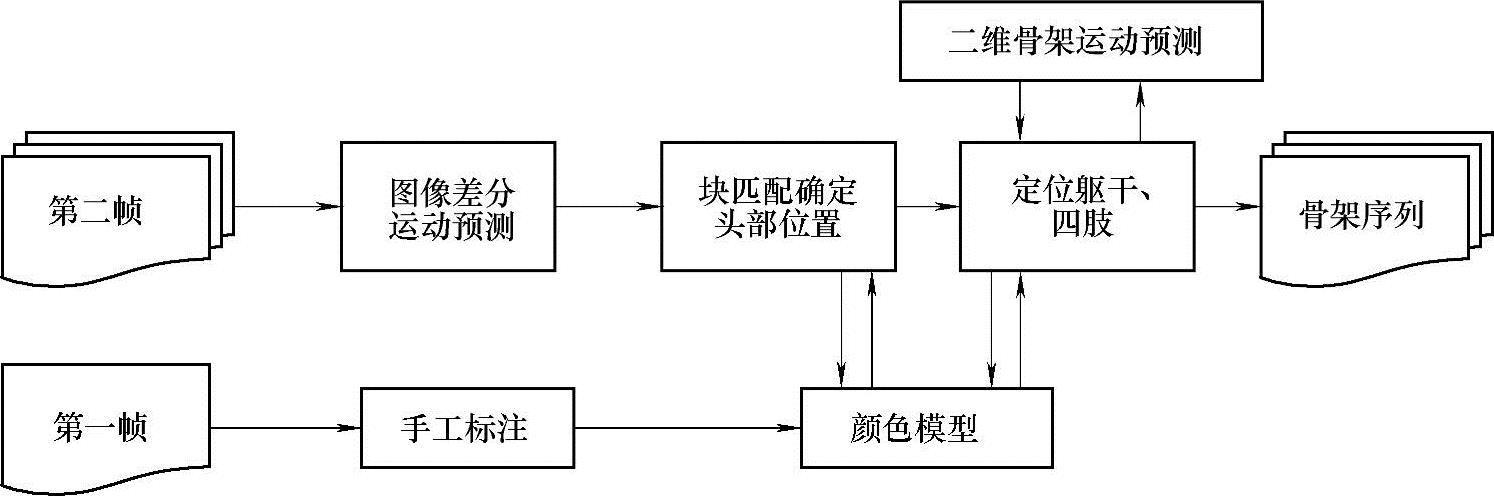
图5-2 系统整体框架
他们将三维人体看成由关节点连接的刚体集合,如上肢是由肘关节连接的上下臂两个刚体,上臂与躯干是由肩关节连接的。他们以三维人体骨架来描述人体运动。将人体投影到二维平面上后,骨架中各线段的空间关系依然保持不变,而有些线段的长度会发生变化,即刚体的投影相对于原刚体外形发生了变化。在二维图像序列的人体跟踪中,由于线段不易由图像信息来表征,所以他们以二维人体块模型来表示人体在二维平面上的投影,如图5-3所示。各长方形的中心线即为人体投影后的骨架,中心线将相应的长方形分为等面积的两部分。长方形的长为刚体投影后的长度,宽由人体学知识来获取。当用户对第一帧中的特征点进行标注后,就得到了该帧中各个长方形的图像信息。因此,如果在后续帧序列中能找到各个长方形相应的新位置,也就得到了投影平面上的人体二维运动骨架。由于用户的首帧标注具有高可靠性,因此实际上将特征提取与特征对应这两步合二为一来完成,即在寻找图像序列特征点的过程中也完成了对应的建立。
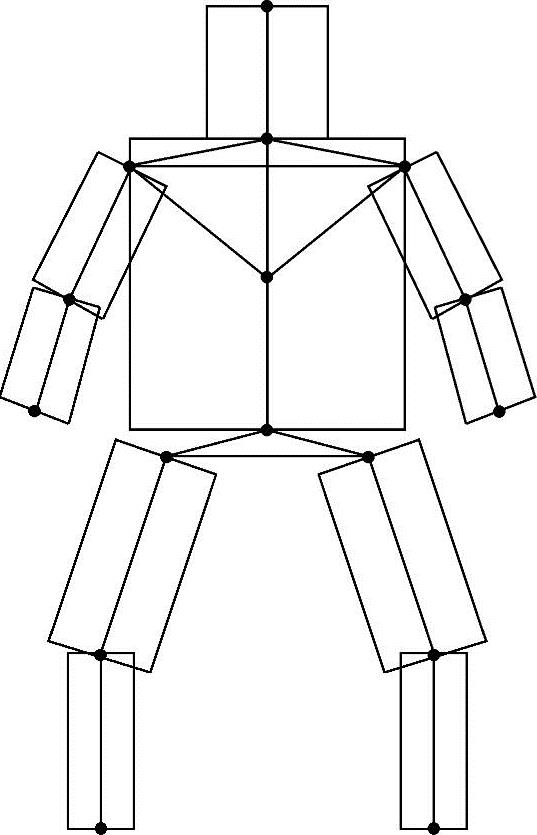
图5-3 二维人体块模型
1.骨架跟踪
由于人体的头部较少有自遮挡现象,可以方便地获取其颜色特征。并且当头部长方形确定后,躯干长方形的一个特征点——颈部就已知了。同样,当上臂长方形确定后,肘关节就固定了,对于下臂只需确定手的位置即可。因此,我们从头部顶点开始,按自上而下的顺序依次跟踪人体各部分。下面按头部、躯干、四肢三部分来分别讲述各自的跟踪。
2.头部跟踪
由于对于任何一个图像帧而言,在帧序列中,人的头部可能向各个方向运动,如果采取局部搜索的方式,那么查找到的位置可能不是全局最优的。如果采取全局搜索的方式,那么效率又会很低。因此,他们采取的是两种方式的结合:为了减少下一帧中对人的头顶特征点的搜索范围,他们采用基于图像差分的运动预测来估计下一帧中头部位置;然后以该预测点为中心,选取一条搜索路径进行形变块的匹配,以精确定位头部位置。
(1)基于图像差分的运动预测 设当前帧k中的头部顶点和颈部点已知,他们将头部区域近似为一个圆形区域H,如图5-4所示。H的直径为L,圆心为O。由于一帧之间头部位移较小,定义差分区域为一个以O为圆心、2L为半径的圆形区域Ω。由下列各式计算差分区域的颜色值:
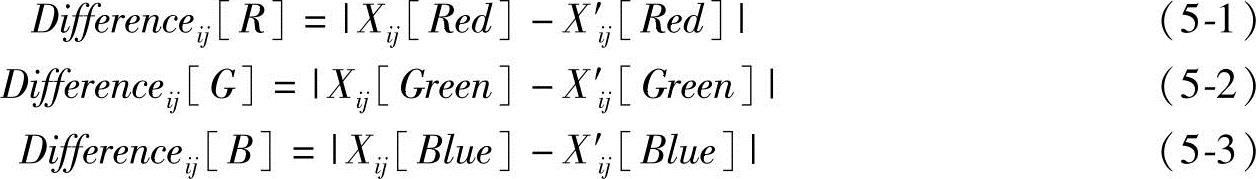
式中,Xij表示k帧中坐标为(i,j)的像素点的RGB颜色值;X′ij表示k+1帧中坐标为(i,j)的点的颜色值。由于下一帧中头部可能向各个方向运动,所以必须先判断其运动方向,然后再估计位移的大小。图5-5是差分区域示意图,H′为下一帧中的头部位置。本节假设相邻帧之间背景变化较少,因此差分区域中除了两个头部区域之外,其值接近为零。下面按如下算法求运动方向α:
1)从α0=90°开始,以αn+1=αn+5°,得到36个α角度值;
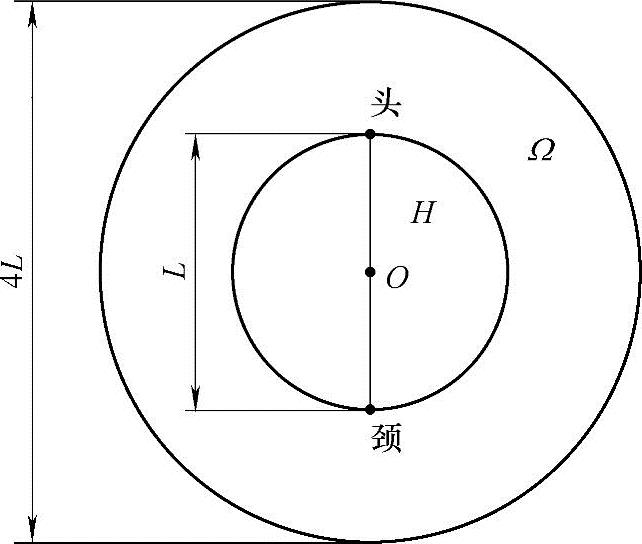
图5-4 头部区域示意图
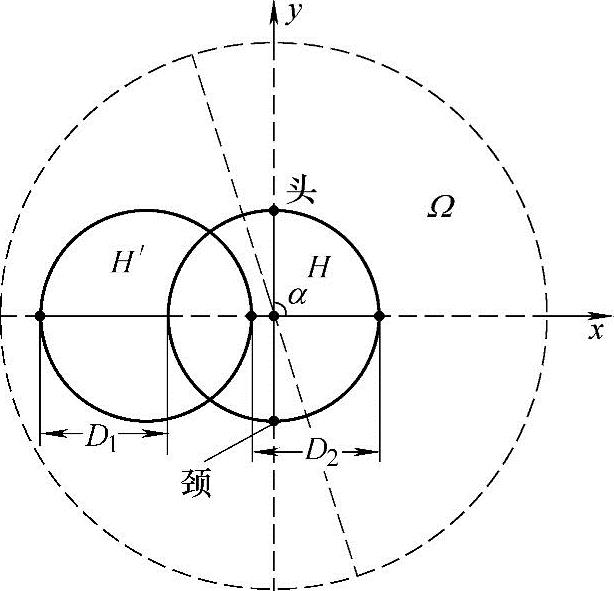
图5-5 差分区域
2)将每个αn所在的直径延长到与差分区域Ω的边界相交,得到36条长为4L的线段Ln;
3)按下式计算每条线段Ln上所有点的颜色总和:(www.daowen.com)
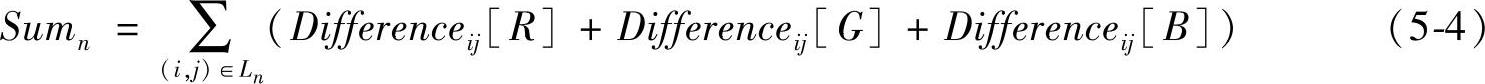
4)取α为使Sumn最大的Ln所对应的角度,即
α={αn|Sumn=max(Sum0,Sum1,…,Sum36)} (5-5)
这个算法的根据是在运动方向上头部区域的位移最大,因而反映在差分区域上应该是该方向上点的颜色值总和最大。在确定了运动方向后,下面要估计头部在这个方向上位移的大小。取α所对应的线段Ln,将线段上所有点的RGB颜色值以曲线形式描述出来,如图5-6所示。由图5-6可以看到,这是一个明显的双峰值曲线,图中左边峰值对应于图5-5中H′与背景的差分,右边峰值对应于H与背景的差分。这两个差分实际上代表了头部在投影平面上的位移,而且双峰的宽度应大致相等。本节的方法是,先将线段Ln上所有点的颜色均值α求出,然后以一个百分比p(如50%)为阈值,在图5-6作一直线y=αp,该直线与双峰值曲线相交有两条线段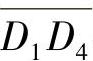 与
与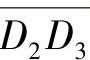 。取
。取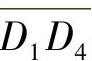 与
与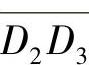 长度的均值为头部的位移。上面描述的确定运动方向的算法只是将方向定在一条线段上,而未确定向线段的哪一端运动。实际上,只需计算
长度的均值为头部的位移。上面描述的确定运动方向的算法只是将方向定在一条线段上,而未确定向线段的哪一端运动。实际上,只需计算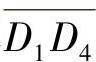 与
与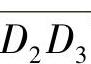 离O的距离,如果
离O的距离,如果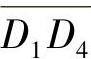 离O远,则头部向
离O远,则头部向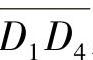 所在方向运动,反之则向
所在方向运动,反之则向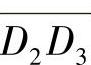 所在方向运动。这样通过图像差分的方法就可以得到下一帧中头部顶点的估计位置。根据形变块匹配得到了头部的准确位置后,还需要衡量一下运动估计的准确度。如果发现估计位移过大,则增加百分比阈值p;反之,则减小p。这样经过自适应地调整阈值后,运动估计的准确度得到了提高。
所在方向运动。这样通过图像差分的方法就可以得到下一帧中头部顶点的估计位置。根据形变块匹配得到了头部的准确位置后,还需要衡量一下运动估计的准确度。如果发现估计位移过大,则增加百分比阈值p;反之,则减小p。这样经过自适应地调整阈值后,运动估计的准确度得到了提高。
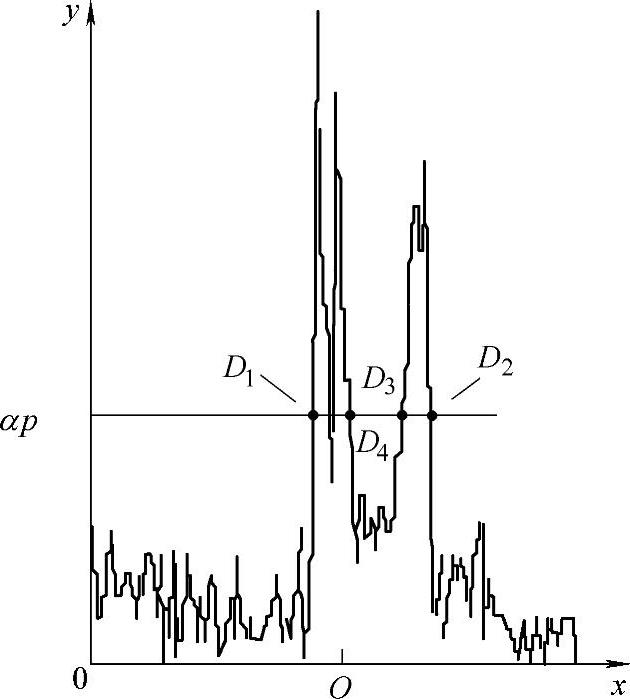
图5-6 运动方向上的双峰值曲线
相对于卡尔曼滤波中较多的矩阵运算而言,他们提出的方法具有运算效率高的优点。但由于基于图像差分的运动预测仅考虑相邻帧的图像信息,并没有利用运动历史的信息,因此在某些情况下,受噪声干扰较大,影响了预测的效果。
(2)形变块匹配 图5-6所示的运动方向上的双峰值曲线图像差分仅仅给出了下一帧中头顶点的预测坐标,下一步即以该点为中心选择一条搜索路径进行匹配,以精确定位头部的位置。为了便于图像匹配,他们将头部在图像上的区域近似为一个长方形(m×n),它的长度m为头部顶点与颈部点的距离,宽度n可通过人体学中头部外形的知识获得。长方形中m×n个点的颜色信息(RGB值)作为头部的颜色模型保留下来,以用于下一帧的匹配。由于图像上的头部区域是三维头部在投影平面上的投影,因此头部在三维空间的运动会造成投影的形状发生变化。如在下一帧中,头部由直立变为略微向左侧倾斜,或头部变大了(这可能是人向相机走来)。因此他们的块匹配必须在形变块之间进行。为此,他们采用一种分区域直方图相似度算法。
定义形变块A={(x,y),m,n,θ},如图5-7所示。(x,y)为块的中心线与一条边的交点;m为块的长;n为块的宽;θ为块的中心线与x轴的夹角。现有参照块A={(x,y),m,n,θ}和比较块A′={(x′,y′),m′,n′,θ′},再按下面三个步骤计算两者的相似度:
1)将块A分为相等面积的4个小区域b1、b2、b3、b4,如图5-7所示。分别计算这4个小区域的颜色直方图H1、H2、H3、H4。
2)将块A′分为相等面积的4个小区域b′1、b′2、b′3、b′4,分别计算这4个小区域的颜色直方图H′1、H′2、H′3、H′4。
3)计算:S=WkΣ4k=1Σni=min(H,k,H′,k′)
Wk表示各个区域在整个块中所占的比重;Hk是将Hk(k=1、2、3、4)标准化后的直方图;n为直方图的维数;min()表示对两个直方图进行求交操作,两个直方图越相似,求交的结果越接近1;反之,则越接近0。因此,他们以S表示两个形变块之间的相似度的度量,S越大,则相似度越大。采用分区域的方法是因为这样不仅考虑了块中的颜色在数量上的分布,也考虑了颜色在位置上的分布。对于一个图像帧序列而言,他们将上一帧中已跟踪到的头部长方形区域定义为参照块A,而前帧中待跟踪的头部长方形为A′。由于一帧之间头部转动很小,所以取θ′为θ-Δθ≤θ′≤θ+Δθ,Δθ为很小的角度值。头部的投影大小都为按比例缩放,所以m-Δm≤m′≤m+Δm;n-(n/m)Δm≤n′≤n+(n/m)Δm。这样,对于搜索路径中的每一个待选点(x,y),他们都由{(x,y),m′,n′,θ′}形成几个A′,分别计算其与上一帧头部区域的相似度,保留具有最小相似度的A′的信息。最后,具有最小相似度的A′即为当前帧中头部区域的位置。由于头部区域的颜色会随光照等条件发生变化,他们还采用线性加权的方法来自适应地更新颜色模型。
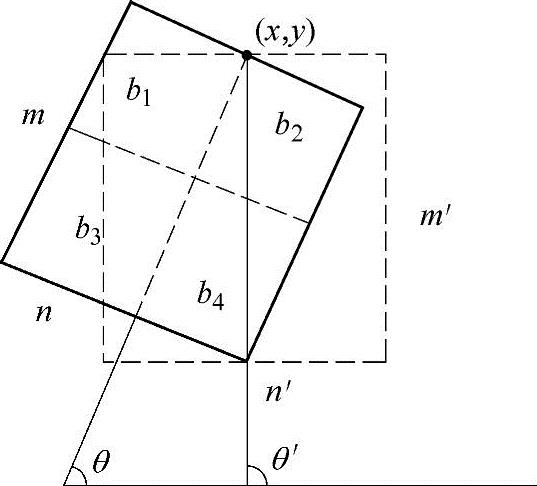
图5-7 特征块
3.躯干跟踪
他们定义躯干部分的长为从颈部点到腹部点的距离,宽为左右肩部之间的距离。为了有效地定位整个躯干的位置,将胸部点的上下两部分合为一部分来考虑。与头部相比,躯干块的长度与宽度不一定是按比例同时缩放的,所以对长度和宽度应分别定义Δm与Δn,然后用分区域直方图相似度算法来确定躯干块的位置。此时躯干块的宽度即为本帧中的肩宽度。躯干确定后,腹部点也就确定了。对于左右臀部两点,他们假设它与上体躯干一起发生旋转。如果上体旋转后肩宽度为上一帧的90%,则本帧中左右臀之间的距离也为上一帧臀间距的90%。
4.四肢跟踪
由于四肢的运动具有相似性,四肢部分在一帧之间可能运动较多,所以应先采用一定的预测机制来估计下一帧中四肢可能的位置,然后再精确定位。以腿部为例,将每一帧中膝部关节点相对臀部的角度值作为运动轨迹信息保存下来。每次预测时,取前两帧的角度值作为均值,以该值作为本帧的初始角度值θ′,然后在(θ′-Δθ,θ′+Δθ)的范围内确定精确的角度值。结果发现,对于四肢的大幅度运动,预测机制能有效地减少块匹配的搜索范围。在描述四肢形变块的参量中,除了θ之外,另一个重要参量是m。因为对于四肢而言,从任何视角投影过去,其宽度变化很小,而长度可能变化很多。所以在每次跟踪四肢部分时,(x,y)已定,n不变,m与θ需要由前述的相似度算法来确定。
在四肢的跟踪中,还有一个必须考虑的问题是遮挡的处理问题。以上肢为例,在某一帧上肢被躯干遮挡后,往往在块的匹配中反映出较低的相似度。但在遮挡消除后,相似度又会升高。因此他们提出了将块匹配的相似度S同时作为块匹配的可信度来度量。在帧序列的匹配过程中,保存每个四肢块的匹配可信度。如果发现在两个较高匹配可信度的帧之间有一个或几个较低可信度的帧,则用高可信度帧中关节点的坐标线性插值,求出中间几帧的关节点坐标。
从分析这种模型匹配的方法中我们发现,当被跟踪人体存在大量自遮挡现象时,跟踪的效果将会受到很大影响。解决这一问题的途径有两个:一是在跟踪过程中,加入用户的反馈,这种交互式跟踪的效果将是非常好的;二是借助三维人体模型的知识来指导二维跟踪,这样就可以最大限度地减少用户反馈的次数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。



