C28x DSP的中央处理器(CPU)结构包括三个部分:CPU内核、仿真逻辑单元和CPU信号,如图3-1所示。
仿真逻辑单元的主要功能是监视和控制CPU以及其他外设的工作情况,并实现对设备的测试和调试功能。用户通过CCS的调试器工具以及硬件JTAG仿真器来访问和操作仿真逻辑单元。调试器通过仿真逻辑单元可以直接控制存储器接口以获得寄存器或存储器的内容或者对存储器的内容进行修改。仿真逻辑单元还能够响应多重调试事件,如用于调试的两条指令ESTOP0或ESTOPl产生的软件断点,对程序空间和数据空间指定单元的访问,以及来自调试器或其他硬件的请求,这些调试事件都能够在程序的执行过程中产生一个断点,使得C28x进入调试停止状态。
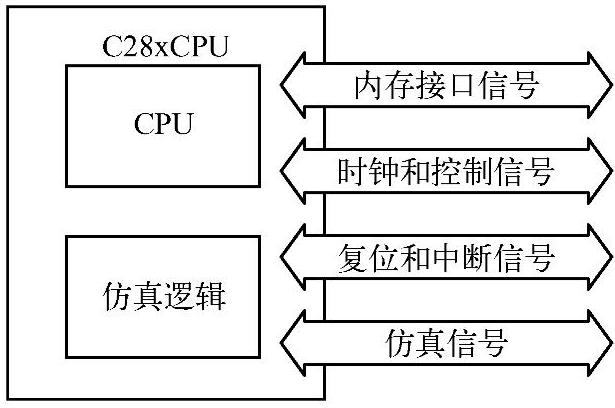
图3-1 C28x CPU组成概念框图
CPU的信号是指由CPU发出或者输入到CPU的工作信号,主要包括4种:
①存储器接口信号,这些信号是指CPU通过并行总线对存储器进行读写访问的时序信号,包括地址信号、数据信号和读写控制信号等。C28x的CPU是32位的,但它能根据不同存储器字段的长度(16位或32位)来区分不同的存取操作(16位或32位)。
②时钟和控制信号,为CPU和仿真逻辑单元提供时钟以及监控CPU状态。
③复位和中断信号,用来产生硬件复位和中断请求,以及对中断状态进行监视。
④仿真信号,用于仿真和调试。
图3-2给出了C28x的CPU内核的主要组成部分以及数据路径。从图中可以看出,C28x的CPU主要由总线、CPU寄存器、程序地址发生器和控制逻辑、地址寄存器算术单元(Address Register Arithmetic Unit,ARAU)、算术逻辑单元(Arithmetic Logic Unit,ALU)、乘法器和移位器等逻辑部件组成,还包括一些未在图中给出的逻辑单元,比如指令队列和指令译码单元、中断处理逻辑等。总线主要完成CPU内部寄存器与各逻辑部件之间或者CPU与外部存储器之间的数据传递。程序地址发生器和控制逻辑用于自动产生指令地址,将其送往程序地址总线,并控制对应指令的读取。ARAU的主要作用是产生指令操作数的地址并将其送往对应的数据地址总线。ARAU还控制堆栈指针以及辅助寄存器的内容,操作数的不同寻址方式是由ARAU单元实现的。ALU为32位的算术逻辑单元,主要执行二进制补码的算术运算和布尔运算。在运算之前,ALU从寄存器、数据存储器或程序控制逻辑单元接收数据,然后进行运算,最后把结果存入寄存器或数据存储器中。C28x的CPU还有一个32位的乘法器,可以执行32×32位的二进制补码乘法运算,并产生64位的计算结果。为了同乘法器关联,C28x运用32位乘数寄存器(Extended Tempo-rary Register,XT)、32位乘积寄存器(Product Register,P)和32位累加器(Accumula-tor,ACC)。XT寄存器提供乘法的一个乘数,乘积被送往P寄存器或ACC中。CPU的移位器实现对操作数的移位操作。
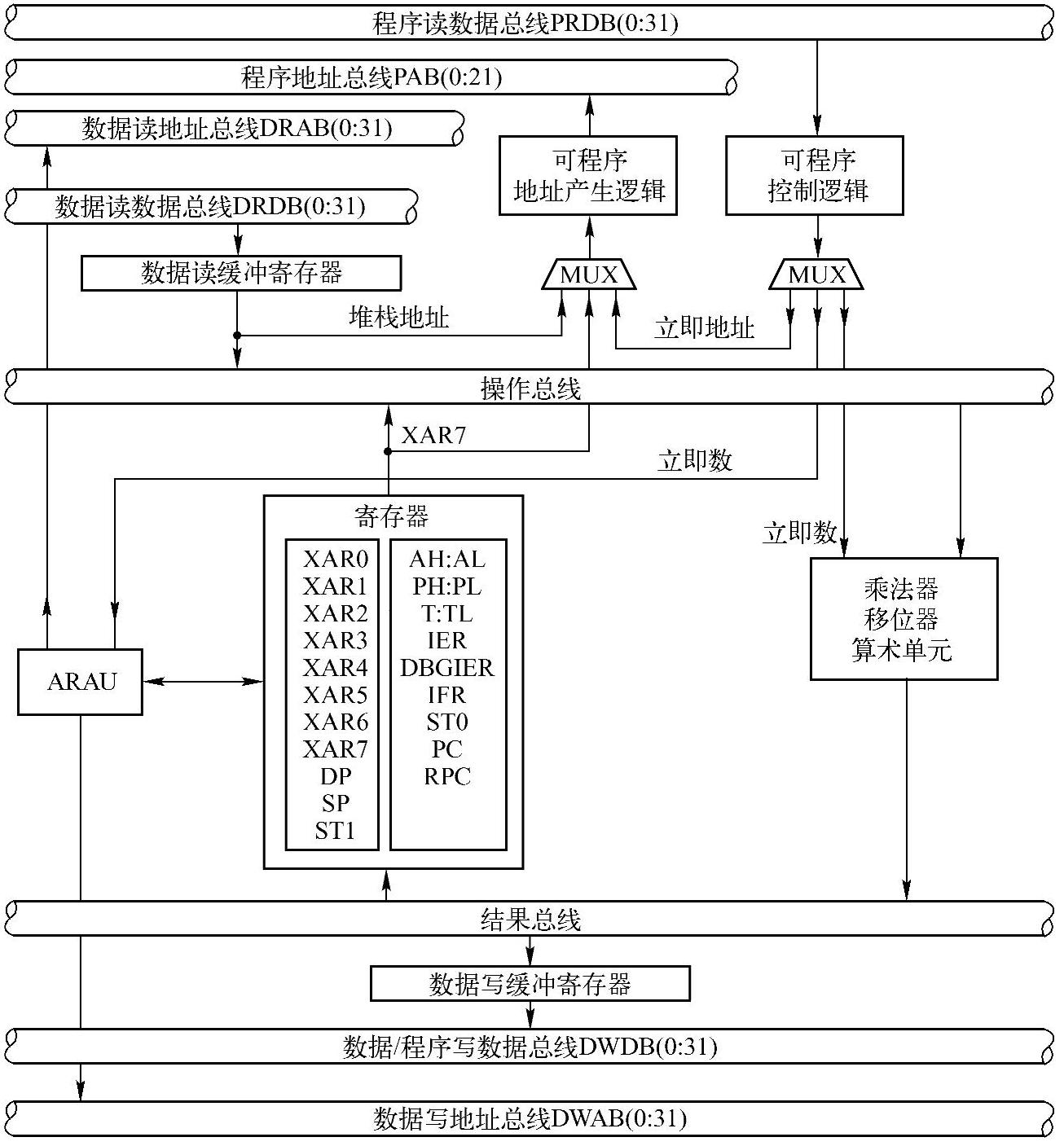
图3-2 C28x DSP的CPU结构框图
C28x拥有一个高性能的32位定点数字信号处理CPU内核,该内核集中了数字信号处理器的诸多优秀特性,如采用改进型哈佛总线结构、精简指令系统(RISC)功能以及循环寻址(Circular Addressing)等。
C28x具备改进哈佛结构处理器的特点,其存储空间被划分为程序空间和数据空间,CPU也设计有专门的访问程序空间的指令。但是,与其他采用哈佛结构的存储器模式(如2407)不同,C28x的程序空间和数据空间本身是重合的,也没有独立的I/O空间,其外部引脚中也没有用来控制访问程序、数据空间的硬件使能信号。而2407具有独立的程序、数据和I/O空间。在硬件控制信号上,它设计有专门的访问程序空间的使能信号、访问数据空间的使能信号与访问I/O空间的使能信号。因此,其三大存储空间在物理上也可以进行区分,从而不会出现冲突。C28x的改进型哈佛结构使其既保留了哈佛结构的优点,即通过对程序和数据空间的区分以避免二者的冲突,也可实现对2407系统程序的兼容,同时其又能够应用于冯·诺依曼模式。在冯·诺依曼模式下,程序和数据被存放于同样的存储器空间中而不做区分,由用户程序自己来管理二者,这种存储器管理功能正是一个操作系统的主要任务之一。因此,在C28x上可以方便地运行嵌入式操作系统。
C28x采用RISC设计,其大多数常用指令为单周期指令,并且采用8级流水线结构。C28x也保留了一些复杂的指令或特殊的寻址方式,如循环寻址方式,这种寻址方式对于DSP实现复杂的数学运算(如FFT变换)具有十分重要的价值,可大大提高运算速度和执行效率。
C28x改进哈佛结构以及RISC特性的基础是多总线结构。基于多总线的CPU可以实现对程序空间或数据空间的独立访问以及实现指令流水线操作。如图3-2所示,C28x的CPU内部包含多种总线。操作数总线为CPU的乘法器、移位器和ALU的运算提供操作数,结果总线则把运算结果送往各寄存器和存储器。
CPU与存储器的接口地址和数据总线共有6组,包括3组地址总线和3组数据总线。CPU通过这6组独立的地址和数据总线来完成指令和数据的并行读写及处理。
3组独立的地址总线(Address Bus)包括:
1)程序地址总线PAB(Program Address Bus)。PAB用来传送来自程序空间的读/写地址,PAB是一组22位的总线。可以访问4MW存储空间。
2)数据读地址总线DRAB(Data-Read Address Bus)。32位的DRAB用来传送数据空间的读地址。
3)数据写地址总线DWAB(Data-Write Address Bus)。32位的DWAB用来传送数据空间的写地址。
3组独立的数据总线(Data Bus)包括:
1)程序读数据总线PRDB(Program-Read Data Bus)。PRDB在读取程序空间时用来传送指令或数据。PRDB是一组32位的总线。
通常,CPU自动产生指令的地址并将其通过PAB送往程序存储器,程序存储器中被读取的指令则通过PRDB总线进入CPU的指令队列,这个工作是由CPU硬件自动进行的。不过,C28x也有专门的程序空间访问指令(如PREAD和PWRITE),用户可以采用这些指令来访问程序存储器的内容。对程序空间的访问,被访问的存储器地址通过PAB传递,而被读取的数据通过PRDB来传递。
2)数据读数据总线DRDB(Data-Read Data Bus)。32位的DRDB在读数据空间时用来传送数据。(https://www.daowen.com)
3)数据/程序写数据总线DWDB(Data/Program Write Data Bus)。32位的DWDB在对数据空间或程序空间进行写数据时用来传送数据。
通常,数据存储器内存放用户定义的变量,由用户通过指令来访问。C28x的CPU内部对数据存储器的读/写地址总线是分开的,读/写数据总线也是分开的。另外,向程序空间和数据空间写操作均通过DWDB传递数据。需要指出的是程序空间的读和写不能同时发生,因为它们都要使用程序地址总线PAB。程序空间的写和数据空间的写也不能同时发生,因为两者都要使用数据/程序写数据总线DWDB。运用不同总线的传输是可以同时发生的,如CPU可以在程序空间完成读操作(使用程序地址总线PAB和程序读数据总线PRDB),而同时在数据空间完成读或写操作;或者在数据空间完成读操作(使用数据读地址总线DRAB和数据读数据总线DRDB),同时在数据空间进行写操作(使用数据写地址总线DWAB和数据/程序写数据总线DWDB)。
281x DSP芯片外部为16位数据总线Data(0:15)和19位地址总线Address(0:18)的单一形式。2803x芯片没有外部数据总线和地址总线。
多总线的结构使C28x能够实现流水线的指令执行机制。在执行一条指令时,C28x执行下列操作:
①从程序存储器中读取指令。
②对指令译码。
③从存储器或CPU的寄存器中读数据值。
④执行指令。
⑤向存储器或CPU的寄存器写入结果。
既然一条指令的执行需要不同的步骤,为了提高效率,采用流水线的方式,在同一时刻处理多条指令,只要这些指令处于不同的阶段,不同时占用同一CPU资源(总线和寄存器)即可。采用流水线机制可以大大加快指令的执行速度,实现指令的执行在单机器周期内完成。C28x采用了8级流水线,即采用8个独立的步骤完成指令的执行,也就是说,在某一时刻,流水线上最多可以运行8条指令,下面是8个具体的步骤。
1)取指令阶段1:在该阶段,CPU将指令地址通过22位的程序地址总线PAB送往程序存储器。
2)取指令阶段2:在该阶段,CPU通过32位的程序读数据总线PRDB对程序存储器进行读操作,并把读取的指令放入指令队列中。
3)译码阶段1:DSP支持32位和16位指令,指令可以被安排到偶地址或奇地址,在此阶段,CPU硬件识别取指队列中指令的边界,并测定下一条待执行指令的长度,同时也确定指令的合法性。
4)译码阶段2:在此阶段CPU硬件从取指队列中取回指令,并将该指令放入指令寄存器,完成译码。一旦指令进入该阶段,就一直会执行到结束。该阶段主要完成的工作根据指令不同而不同,例如:
①若指令需要从存储器中读出数据,则CPU在该阶段产生源地址。
②若指令需要将数据写入存储器,则CPU在该阶段产生目标地址。
③地址寄存器算术单元ARAU按要求完成对堆栈指针(SP)、辅助寄存器或辅助寄存器指针(ARP)的更改。
④如果执行流程控制指令,则该阶段断开程序的连续执行。
5)读阶段1:如果指令要从存储器中读取数据,在此阶段硬件会将地址送到相应的地址总线上。
6)读阶段2:在该阶段,硬件通过相应的数据总线取回读阶段1所寻址的存储器内的数据。
7)执行阶段:在该阶段CPU执行所有的乘法、移位和ALU操作,这包括所有运用累加器和乘积寄存器的主要算术和逻辑操作。这些操作涉及读数据、改变数据和向原位置写回数据等。例如,乘法器、移位器和ALU使用的所有CPU寄存器值都将在执行阶段开始时从寄存器中读出,而运算完成后,在执行阶段结束时向CPU寄存器中写回结果。
8)写阶段:如果要将指令执行的结果或转换值写回存储器,则该操作在此阶段发生。CPU会驱动目标地址、相应的写选通信号和数据完成写操作。
尽管每一条指令都需要经过这8个阶段,但对具体指令来讲并非每个阶段都是有效的,一些指令在第二步译码2阶段就已经结束,另外一些指令在执行阶段结束,还有一些指令在写阶段结束。例如,不从存储器读的指令在读阶段就没有操作,不向存储器写的指令在写阶段就没有操作。由于不同的指令会在不同阶段对存储器和寄存器进行修改,一个不受保护的流水线会不按预定顺序在同一位置进行读写,这种现象称为流水线冲突。为了防止流水线冲突,CPU会自动增加无效周期来确保这些读写按预定方式进行。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




