工业互联网平台通常由几百、几千甚至更多台普通服务器组成。要保证系统的工作性能,需要采用分布式资源管理技术,通过锁机制协调多任务对于资源的使用,以保证数据操作的一致性。
Google在系统的可靠性方面提出了中心化的组件Chubby——粗粒度锁服务,通过锁原语为其他系统实现更高级的服务,如组成员、域名服务和引领机(Ieader)选择等。Chubby本身通常是由五个Chubby结点组成的一个小型的单元格,单元格内部采用类似于状态机副本的形式实现可靠容错。Yahoo借鉴Chubby的设计思想开发了ZooKeeper,并将其开源。和Chubby相比,ZooKeeper做了很多突破。不像Chubby的单点服务的结构,ZooKeeper采用多个服务器同时处理客户的请求,异步读同步写,通过主结点来同步数据的更新,这一点大大改善了读服务的性能,当然,弱化了客户与服务器之间的一致性。另外,ZooKeeper采用Block Free的服务接口,采用Watch机制的方式异步处理请求结果和指定数据的变更。ZooKeeper对外提供了更加低级的原语,基于此可以实现更多、更加复杂的分布式算法,如queue、barrier和lock等。如今很多云计算系统或者平台都使用ZooKeeper来做可靠容错,进行订阅分发服务,或者其他应用。
与Chubby相同,ZooKeeper采用Fast Paxos来实现消息传输的一致性。ZooKeeper开发了原子多播协议(Zab)来实现数据的一致性传输。ZooKeeper采用的是主结点-备用结点的结构,主结点产生非交换事务,通过协议按序地广播到其他备用结点上。面对复杂的网络环境,多变的软硬件条件,结点挂掉、重启,数据重复发送,ZooKeeper的Zab协议很好地保证了整个系统状态的一致性。
Zab协议以相当于序列号的历元(Epoch)的方式执行。每个历元最多只有一个进程多播数据。如果某个进程执行了协议的第一阶段,那么进程将不再接收之前还没确定提交的历元的数据。这样一来就保证了进程在恢复阶段不会出现丢失已提交数据的情况。在某个历元下,所有参加这个历元的进程必须在此时段之前已经提交了全部的数据镜像。为了保证一致性,进程在完全恢复之前不能广播新的事务。Zab协议的这几个特点处理了主结点异常、新旧主结点以及备用结点异常的情况,保证了主结点进程原子多播的序列特性。
ZooKeeper服务自身组成一个集群,具有2n+1个服务,允许其中的n个失效。ZooKeeper服务有两个角色:一个是引领机,负责写服务和数据同步;另一个是跟随机(Follower),提供读服务。引领机失效后会在跟随机中重新选举新的引领机。
ZooKeeper逻辑图如图5-16所示。
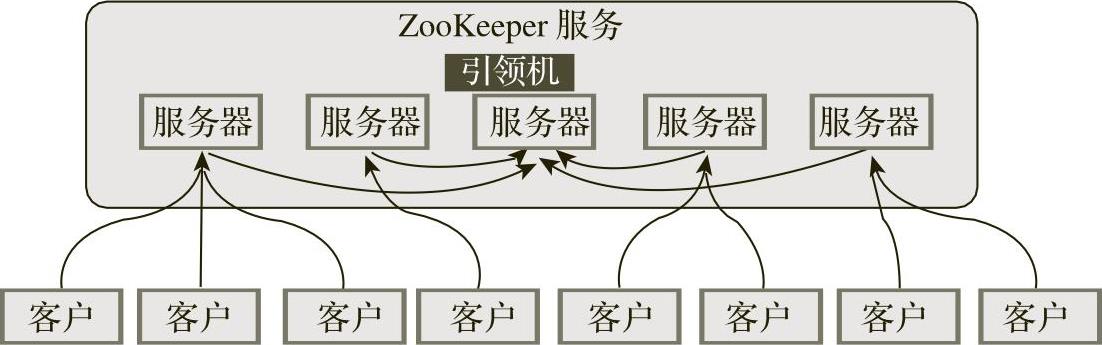
图5-16 ZooKeeper逻辑图
1)客户可以连接到各个服务器,每个服务器的数据完全相同。
2)每台跟随机都和引领机有连接,以接收引领机的数据更新操作。
3)服务器记录事务日志和快照到持久存储。(https://www.daowen.com)
4)大多数服务器可用,整体服务就可用。
ZooKeeper数据模型如图5-17所示。ZooKeeper表现为一个分层的文件系统目录树结构。与文件系统不同的是,结点可以有自己的数据,而文件系统中的目录结点只有子结点。圆形结点可以含有子结点,多边形结点不能含有子结点。一个结点对应一个应用,结点存储的数据就是应用需要的配置信息。ZooKeeper具有以下特点:
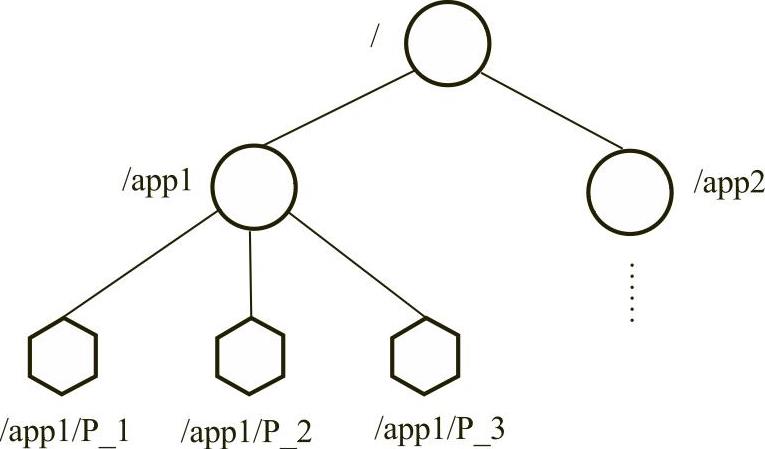
图5-17 ZooKeeper数据模型
1)顺序一致性。按照客户发送请求的顺序更新数据。
2)原子性。更新要么成功,要么失败,不会出现部分更新。
3)单一性。无论客户连接哪个服务器,都会看到同一个视图。
4)可靠性。一旦数据更新成功,将一直保持,直到有新的更新。
5)及时性。客户会在一个确定的时间内得到最新的数据。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






