要进行海量工业大数据的分析,并从中获得机器智能,需要大量的计算资源。为了迅速得到结果,常常需要几十、几百甚至上万台计算机同时执行同一个程序。这要求大数据的分析程序必须采用并行化编程,以便把计算负荷分配到各个结点的计算机上。
Google发明的MapReduce将并行化、容错、数据分布、负荷均衡等放在一个库里,将系统对数据的所有操作都归结为映射(Map)和归约(Reduce)两个阶段。程序员向MapReduce提交并行处理作业只需定义映射函数和归约函数,极大地方便了编程人员,使其在不精通分布式并行编程的情况下,也可将自己的程序运行在分布式系统上。工业互联网平台上通常都会使用Hadoop对MapReduce的开源实现。
MapReduce的基本原理是将大的数据分成小块逐个分析,最后再对提取出来的数据进行汇总分析,最终获得人们想要的内容。MapReduce的算法比较复杂,Hadoop MapReduce是对Google MapReduce的开源实现。MapReduce将并行编程的复杂过程简化为两个简单的映射和归约操作,从而大大简化了并行程序的开发。基于MapReduce开发的应用程序可以并行地运行在由上千台普通商用机器构成的集群上,以可靠容错的方式处理TB级别的大数据集。通常,MapReduce和HDFS运行在一组相同的集群结点上,集群计算结点也是存储结点,这种设计允许计算框架在那些已经存好数据的结点上高效调度任务,通过将计算任务移到存储结点上的方法可以大大降低集群上的网络流量,提高Hadoop集群的工作性能。
MapReduce的原理是将输入数据分片后转变为一个键值对(key/value pairs)的集合,经过计算,产生一个输出键值对集合。计算过程分为映射和归约两个阶段,如图5-4所示。
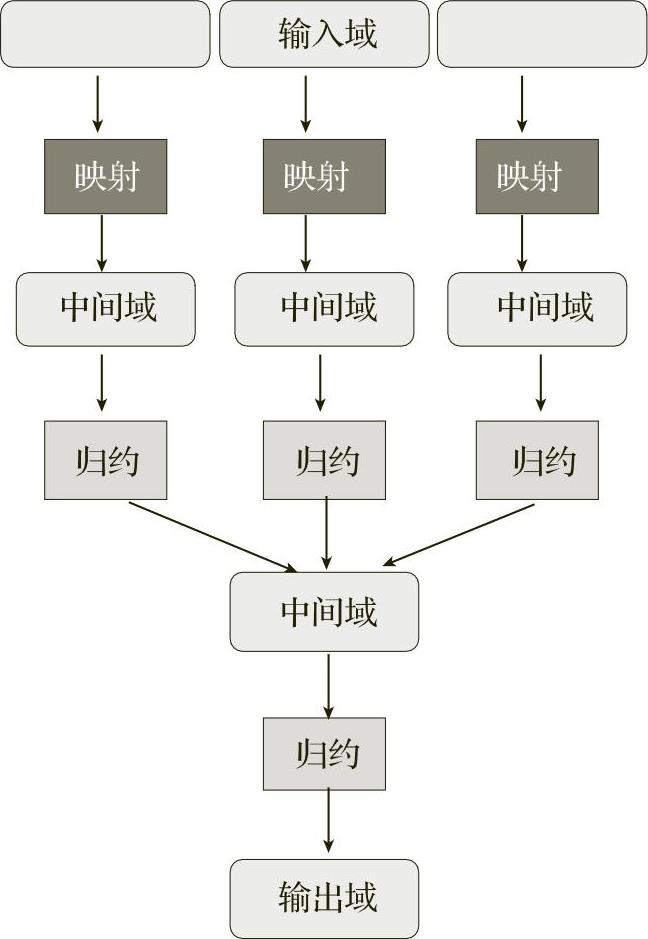
图5-4 MapReduce的原理
映射阶段:映射阶段将输入的键值对集合经过函数map()处理后,产生一个临时的中间键值对的集合,并且将这些结果保存在计算结点所在的本地存储上。
归约阶段:归约阶段将映射阶段输出的键值对的集合,调用函数reduce(),将相同键值对进行归约,得到最终结果,产生输出。
下面通过计算机床最高测量温度的例子,说明MapReduce的基本流程。
一个工厂有10000台机床,如果每秒都会有一个测量的温度数据,工厂希望找到机床最高的测量温度是多少。按照传统的计算方式,会对每个数据进行比较,找到最大值。但如果有1亿个这样的数据,这样的算法会需要很长的时间,可能无法满足实际的需要。
MapReduce会这样做:首先数字是分布存储在不同块中的,以某几个块为一个映射,计算出该映射中最大的机床温度值,然后将每个映射中的最大机床温度值做归约操作,归约再取最大机床温度值,得到最终结果,如图5-5所示。
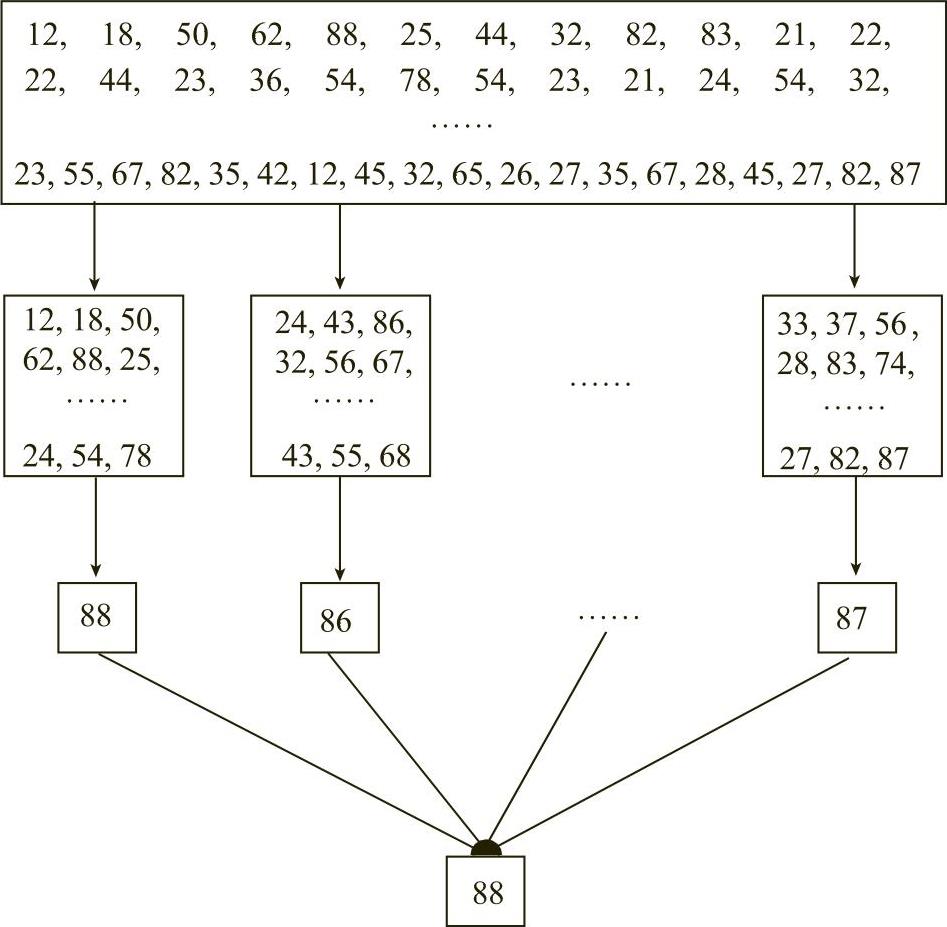
图5-5 MapReduce的运用流程示例(www.daowen.com)
MapReduce的系统架构如图5-6所示,包括两个主要组件:工作追踪器(JobTracker)和任务追踪器(TaskTracker)。其中工作追踪器运行在集群的主结点上,任务追踪器运行在集群的所有从结点上。任务追踪器接受工作追踪器的调度,可以同时分配多个任务来执行计算。
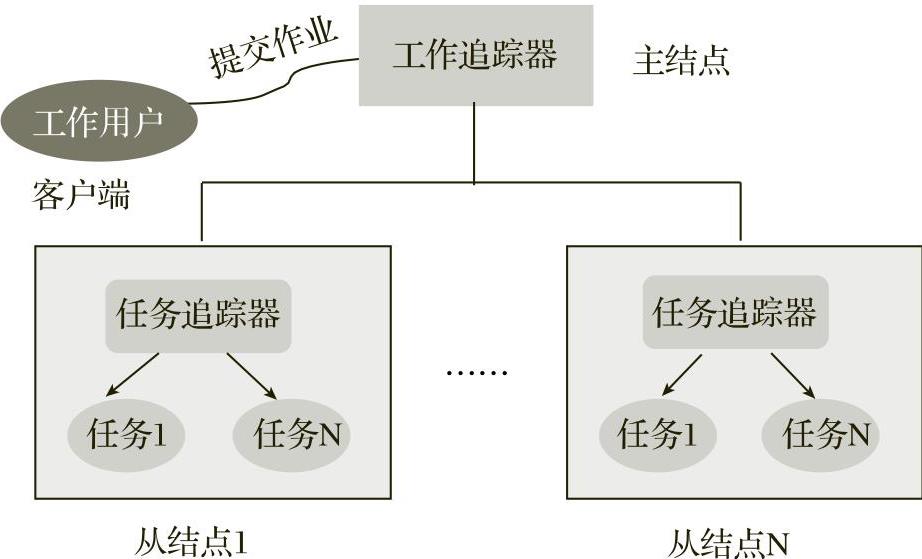
图5-6 MapReduce的系统架构
客户将工作提交到集群上,工作追踪器负责工作的执行计划,包括将工作分配给哪些任务追踪器执行,以及监控所有工作的运行状况。如果有些结点上的任务执行失败,则工作追踪器能够在其他结点上自动重启失败的任务。
运行在每个从结点上的任务追踪器负责管理该结点上任务的执行情况。任务追踪器接受工作追踪器的调度,执行工作追踪器分配给它的单项任务。任务追踪器必须持续地和工作追踪器进行通信。如果工作追踪器在指定的时间内没有收到来自任务追踪器的“心跳”,则工作追踪器会假定该任务追踪器已经崩溃,进而将任务分配给其他结点执行。
MapReduce是一个并行编程模型,适用于编写大规模分布式应用程序。MapReduce具有以下特点。
1)处理海量数据。MapReduce处理大型数据集,数据存储在HDFS等分布式文件系统中,数据的规模都在TB、PB级别。
2)高度并行性。通常使用上百、上千或更多的CPU同时计算。任务追踪器所分配的任务在工作结点上并行执行,任务执行过程相互独立,具有高度并行性。
3)将计算移到存储结点。将计算移到数据结点比将数据移到计算结点具有更好的性能。这样将很小的计算代码移到存有数据的存储结点上,避免了将大量的数据复制到计算结点上。
4)高容错功能。MapReduce假设计算机可能发生故障,当工作追踪器获取不到任务追踪器的“心跳”时,就认为工作结点失效,因此会将失败的计算任务调度到其他工作结点运行,从而保证计算过程的可靠性。
5)编程便捷。MapReduce屏蔽了底层分布式计算实现的细节,应用开发人员只需要编写自己业务的编码,框架即可实现分布式并行运算。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





