为了保证平台的可靠性和经济性,工业互联网平台基于云计算技术,采用分布式存储的方式来存储数据,采用冗余存储的方式来保证存储数据的可靠性,通过软件控制来弥补硬件的不可靠,构造廉价、可靠的海量分布式存储系统。
在云计算平台上,大量廉价的普通PC服务器被作为结点用来构造计算机集群,因此集群中的结点失效是一种常态,每时每刻都会有结点处在失效状态,因此需要采用容错机制通过软件模块监视系统的动态运行情况,发现失效结点,进行自动恢复。
目前大部分云计算平台采用Hadoop团队开发的开源文件存储系统(HDFS)。Hadoop是工业互联网平台中应用最广泛的分布式系统基础架构,是由Apache软件基金会维护的一个适用于对大规模数据进行分布式处理的开源技术项目,是目前云计算与大数据分析中应用最广泛的一个技术框架。
Hadoop源于2002年Apache的一个开源Java实现的搜索引擎Nutch,它提供了运行搜索引擎所需的全部工具,包括全文搜索和网络爬虫。2004年Nutch创始人道格·卡廷(Doug Cutting)基于Google的谷歌文件系统GFS论文[14]实现了分布式文件存储系统,名为NDFS。2005年卡廷又基于Google于2004年发表的关于大规模数据分布式处理的论文“MapReduce:Simplified Data Processing on Large Clusters”[15]在Nutch搜索引擎实现了MapReduce的功能。2006年,卡廷将NDFS和MapReduce升级命名为Hadoop,Yahoo建立了一个独立的团队,由卡廷带领,专门研究和发展Hadoop。
Hadoop是一种在由多台通用计算机组成的集群上,对大规模数据进行分布式处理的框架。Hadoop的MapReduce功能将整个任务打碎,划分成在集群中任意结点上都可以执行的多个碎片任务,并分配给多个结点来执行,然后通过对各结点瞬间返回的信息进行重组,得到最后的结果。Hadoop假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的结点重新分布处理,因此具有较高的可靠性。
Hadoop采用并行方式,通过并行处理提高处理速度。Hadoop的分布式架构使大数据处理引擎尽可能地靠近存储,对诸如数据提取、转换和加载(ETL)这样的批处理操作非常合适,因为类似这样操作的批处理结果可以直接走向存储。因为Hadoop集群的规模可以动态调整,所以可以处理PB级甚至EB级的数据。
现今,Hadoop是一个分布式计算基础架构下的相关子项目的集合,这些项目属于Apache软件基金会,为开源软件项目社区提供支持,其架构如图5-2所示。
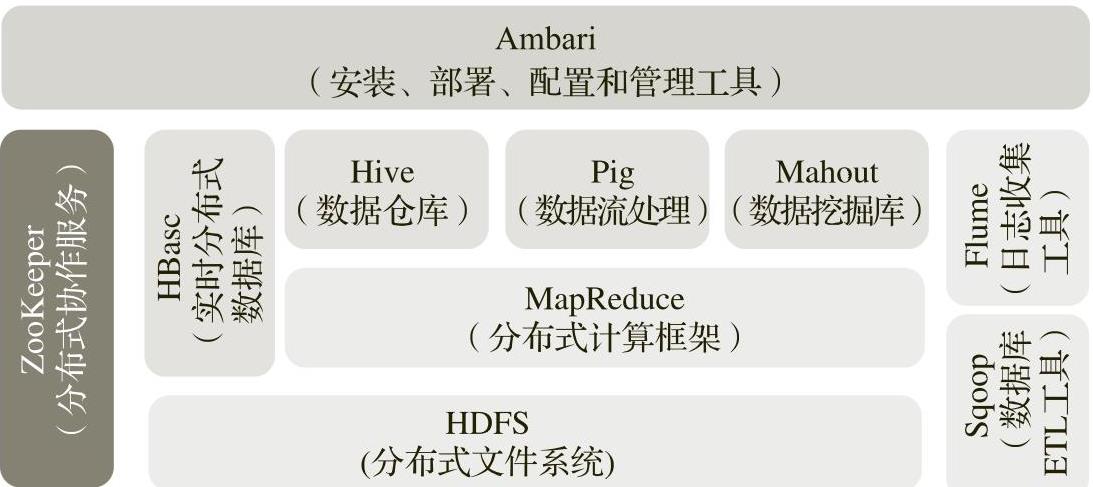
图5-2 Hadoop架构
Hadoop由许多组件和子项目组成,其中使用较多的如下。
1)HDFS:Hadoop使用的分布式文件系统,提供了Hadoop运算过程中的数据存储、数据备份、数据错误校验等功能。HDFS具有很高的数据吞吐量,可以用来存储大规模数据集。
2)Hadoop MapReduce:Hadoop使用的并行计算框架,是Google MapReduce的开源实现。使用该框架编程,开发人员可以在不了解分布式计算底层实现细节的情况下,编写出高质量的分布式并行程序。
3)HBase:一个超级可扩展的键值存储数据库,是对Google BigTable的开源实现,它的工作原理非常像持久的散列映射。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
4)ZooKeeper:一个分布式的,高可用性的协调系统,主要提供配置服务、名字服务、分布式同步、组服务等功能,用于管理集群的同步性。其设计目标是封装复杂、易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
5)Hive:一个基于Hadoop的数据仓库平台。Hive定义了一个类似SQL的查询语言HiveQL,Hive通过一个HiveQL解析器将HiveQL语句转化为MapReduce作业,然后在Hadoop集群上执行。使用HiveQL可以轻松地在大规模数据集上进行数据查询等操作,使得Hadoop海量数据分析中的数据归纳、查找和分析变得更加容易、简单。
6)Pig:一个基于Hadoop的大规模数据分析平台,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时,Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。Pig定义了一个类似SQL的语言Pig Latin,其编译器会将Pig Latin的数据请求转换成一系列经过优化处理的MapReduce运算。
7)Sqoop:Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间的数据传输。数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性。
8)Flume:Cloudera提供的日志收集系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。Flume是一个分布式、可靠和高可用的海量日志采集、聚合和传输系统。(https://www.daowen.com)
9)Mahout:一个基于Hadoop的机器学习工具。Mahout的主要目标是创建一些可伸缩的机器学习算法,供开发人员使用。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁项集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB或Cassandra)集成等数据挖掘支持架构。
分布式文件系统(HDFS)是Hadoop的存储系统,其设计具有高性能、高容错、可扩展等特点,可以部署在普通计算机硬件上。HDFS具有很高的数据吞吐量,适合有超大规模数据集的应用。HDFS将大数据文件分块,并以副本的方式存储在集群多个结点的计算机上,从而可以保证数据的可靠性和分布式计算的高效性。
HDFS的设计基于主从结构,每个HDFS集群都有一个名称结点(NameNode)和多个提供存储块的数据结点(DataNode),如图5-3所示。存储在HDFS中的文件被分成块,然后这些块被复制到多个作为数据结点的计算机中。块的大小(通常为64MB)和复制的块数量在创建文件时由客户机决定。
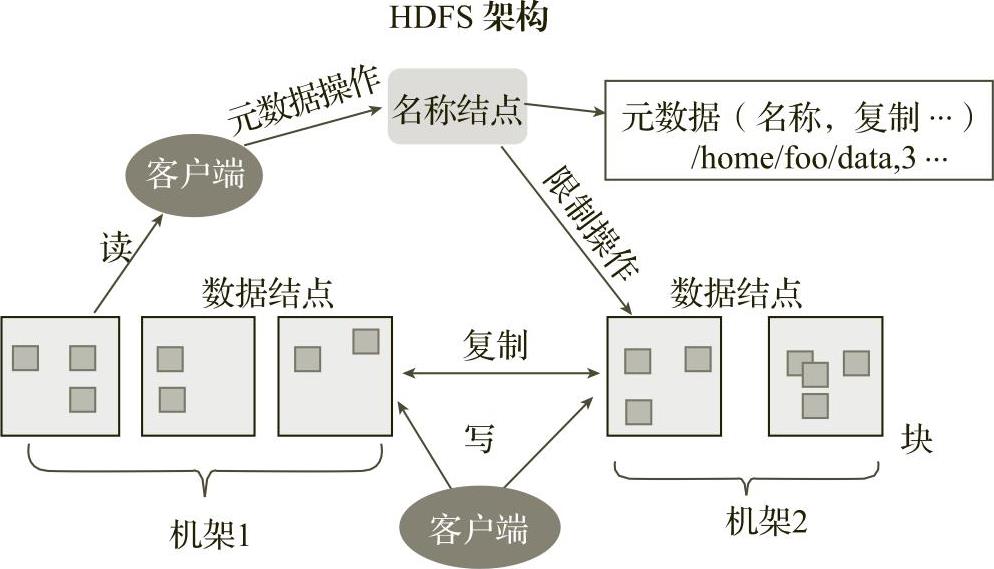
图5-3 HDFS系统架构
名称结点是集群的主结点,主要用于管理分布式文件系统命名空间,存储文件名、文件目录、文件属性等元数据信息,以及数据块和数据结点之间的映射关系。名称结点对外提供创建、打开、删除和重命名文件或目录的功能。名称结点将所有的元数据信息保存在内存中以加快HDFS的访问速度。在HDFS集群中,名称结点是这个HDFS的核心。如果名称结点出现故障,则整个文件系统将无法使用,而且文件系统中的数据也会丢失。
数据结点是HDFS集群的从结点,用于管理实际的数据存储,在本地文件系统上存储文件块数据以及数据块的校验等信息。它还负责来自客户的文件读/写请求,同时执行块的创建、删除以及来自名称结点的文件和块的操作指令。数据结点可以在集群中动态地增删而不会影响HDFS的使用,这是HDFS集群可以进行线性扩展的关键。
在HDFS中,数据结点定期向名称结点上报“心跳”,名称结点通过响应“心跳”来控制数据结点。HDFS内部的所有通信都基于标准的TCP/IP。对外部客户机而言,HDFS就像一个传统的本地文件系统,可以创建、删除、移动或重命名文件或目录。
HDFS的设计目标和特征如下:
1)处理超大文件。HDFS处理的超大文件是指单个文件大小达到几百GB、TB,甚至PB级别的文件。
2)流式数据访问。HDFS的数据处理流程是从数据源生成或复制数据到HDFS,然后在该数据集上进行各种分析。每次数据分析都会涉及数据集的全部或大部分,因此读取整个数据集的时间延迟非常重要。HDFS的流式数据访问模式可以提高数据的读取速度。
3)运行于普通计算机硬件。HDFS被设计运行于主流的普通计算机硬件上,因此结点失效常常发生。HDFS将数据分块,在集群中保留分块数据的多个副本,因此即使集群结点频繁失效,也可以保证数据不会丢失。
4)高数据吞吐量。Hadoop的设计目标是面向海量数据的分析处理,因此数据的高吞吐量是其设计目标之一。HDFS为了达到高数据吞吐量的目标,牺牲了低延时的特性。
HDFS不适合处理的情况介绍如下。
1)大量小文件:HDFS的名称结点将文件的元数据信息保存在内存中以加快客户的数据访问。大量的小文件会使得元数据信息过大,加重名称结点存储元数据的负担,最终影响整个Hadoop集群的数据访问性能。在HDFS中处理单个大文件是最高效的数据处理方式,对于大量小文件,HDFS提供了将大量小文件归档后进行处理的工具。
2)低延时的数据访问:HDFS为了保证高的数据吞吐量,采用了牺牲低延时为代价的设计,因此低延时数据应用不适合在HDFS上存储和运行。对于低延时应用,可以使用HBase。
3)多用户写入:HDFS中的写入是将数据添加到文件末尾,其设计目标是一次写入、多次读取的数据分析应用。目前HDFS不支持多个用户的同时写入操作,也不支持在文件的任意位置进行修改。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






