
首先,来说说搜索引擎抓取收录页面的一般流程,在互联网中,URL是每个页面的入口地址,“蜘蛛程序”就是通过这些URL列表抓取到页面的,“蜘蛛”不断地从这些页面中获取URL资源及存储页面,并加入URL列表,如此不断地循环,搜索引擎就可以从互联网中获取到足够的页面,如图3-5所示。
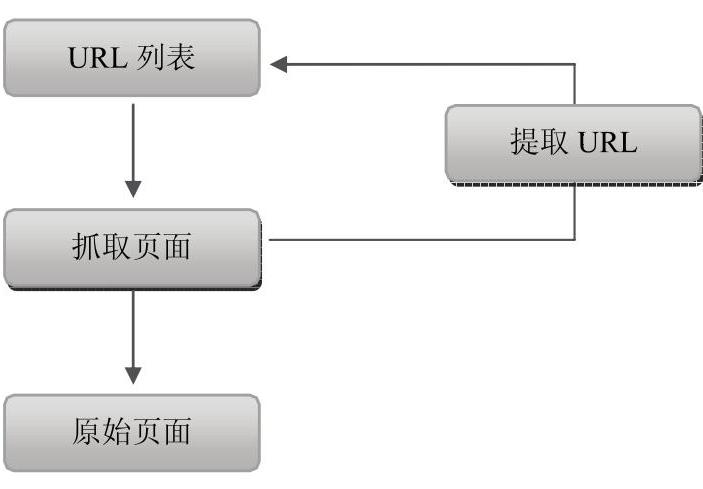
图3-5 搜索引擎抓取页面简单流程
URL是页面的入口,域名则是网站的入口,搜索引擎就是通过域名进入网站,挖掘URL资源的,换而言之搜索引擎在互联网中抓取页面的首要任务就是要有庞大的域名列表,再不断地通过域名,进入网站抓取网站中的页面。
上面的介绍让我们可以大致了解搜索引擎的工作方式,现在,我们来说一下页面收录的原理。假设把一个网站页面组成的页面看做是一个有向图,沿着页面中的链接,依照某种特定的战略对网站中的页面停止遍历。不停地从URL列表中移出曾经拜访的URL,同时提取原始页面中的URL的消息,再将URL分为域名及外部URL两大类,同时判定URL能否被拜访过,递归地扫描URL列表,直至耗尽一切URL资源为止,如图3-6所示。
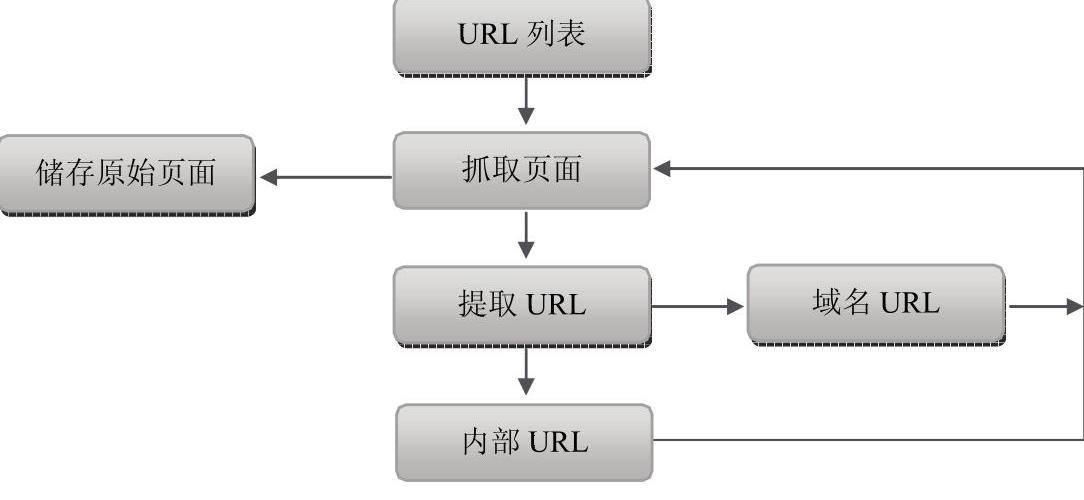
图3-6 搜索引擎收录页面的工作原理
在搜索引擎中要获取相对重要的页面,就涉及搜索引擎的页面收录方式。虽然知晓了“页面收录流程”和“页面收录原理”但是在搜索引擎中要获取绝对主要页面,页面收录方式则是指搜索引擎抓取页面时所使用的战略手段。为了能在互联网中挑选出绝对主要的消息,假设使用相同的抓取战略,搜索引擎在一样的时间内能够在某一网站中抓取到更多的页面资源,则会在该网站停留更长的时间,收录的页面数自然也就多了。因而,加深对搜索引擎页面收录方式的熟悉,有益于为网站树立相对应对的构造,增加被收录的数目。搜索引擎搜收录页面的方式主要有“广度优先”“深度优先”及“用户提交”(用户提交暂时不做详细描述)三种。
广度优先:如果把整个网站看做一棵树,首页就是根,每个页面就是叶子。广度优先是一种横向的页面抓取方式,先从树的较浅层开始抓取页面,直接抓完同层次的所有页面后才进入下一层。因此,在对网站进行优化时,我们应该把网站相对重要的信息展示在层次比较浅的页面上(例如:在首页推荐一些热门的内容)。反过来,通过广度优先的抓取方式,搜索引擎就可以首先抓取到网站中相对重要的页面。(www.daowen.com)
首先,“蜘蛛”从网站的首页出发,抓取首页上所有链接指向的页面,形成页面集合A,并分析出A中所有页面中的链接;再跟踪这些链接抓取下一层的页面,形成页面集合B;就这样递归地从浅层页面中解析出链接,再从深层页面,直至满足某个设定的条件才停止抓取进程,如图3-7所示。
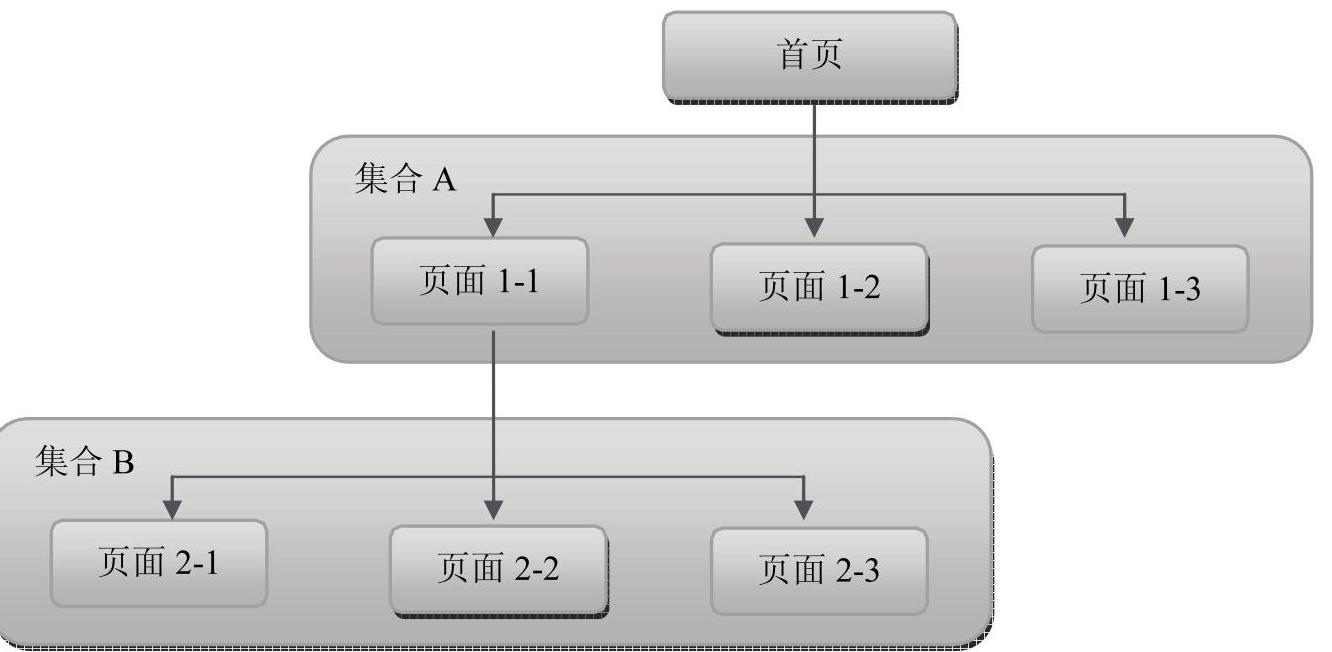
图3-7 广度优先抓取流程
深度优先:与广度优先的抓取方式相反,深度优先首先跟踪浅层页面中的某一链接,后逐步抓取深层页面,直至抓完最深层的页面才返回浅层页面再跟踪其另一链接,继续向深层页面抓取,这是一种纵向的页面抓取方式。使用深度优先的抓取方式,搜索引擎可以抓取到网站中较为隐蔽、冷门的页面,这样就能满足更多用户的需求。
首先,搜索引擎会抓取网站的首页,并提取首页中的链接:再沿着其中的一个链接抓取到页面A-1,同时获取A-1中的链接并抓取页面B-1,获取B-1中的链接并抓取页面C-1,如此不断地重复,满足到某个条件后,再从A-2抓取页面及链接,如图3-8所示。
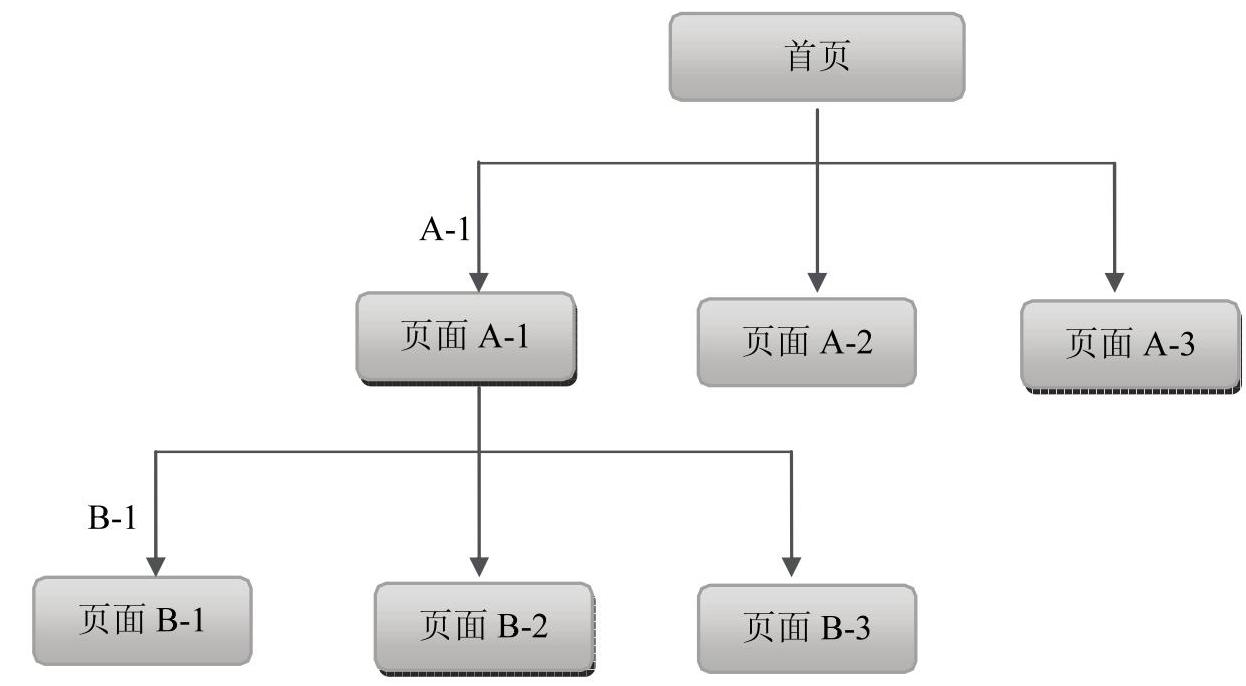
图3-8 深度优先抓取流程
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





