(一)字段匹配算法
字段相似度是根据两个字段的内容而计算出的一个表示两字段相似程度的数值S,其中0≤S≤1。S越大表示两个字段的相似程度越高,当S=1时表示两个字段为完全重复字段,S=0表示两个字段无任何相似性。根据字段的类型不同,计算方法也不相同。
1.布尔型、离散型字段
对于布尔型字段、离散型数值数据相似度,如果两字段相等,则相似度取1,如果不同,则相似度取0。
2.连续型数值字段
对于连续型数值字段,可以采用计算数字的相对差异。如式(5-4-14)所示。
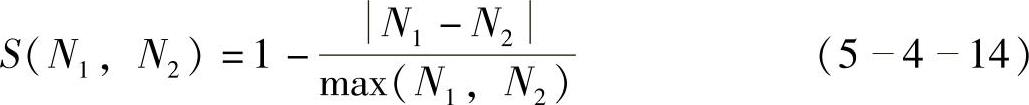
3.日期型字段
对于日期型字段,可以采用计算两个日期之间的间隔天数来确定它们之间的差异。假设一年为360天,每月为30天,两个日期的间隔天数如式(5-4-15)所示。
间隔天数=年数之差×360+月数之差×30+天数之差(5-4-15)
例如2008/4/5与2008/5/7间隔天数为32天。
根据间隔天数的值,来确定相似度。判断公式如式(5-4-16)所示。

4.字符串型字段
近似字符串匹配的研究方法很多,包括基本字符串匹配算法、递归匹配算法、Smith-Waterman算法、基于动态规划的编辑距离法、N-Grams距离法和快速过滤法等。下面重点介绍比较常见的基于编辑距离的字符串匹配算法。字符串编辑距离是建立在一系列编辑操作的基础之上,编辑操作一般指字符串的单个字符的插入、删除和替换。但编辑距离也有一定的缺陷,不能反映单词位置交换、长单词的插入和删除错误。
两个字符串X和Y之间的编辑距离d(X,Y)定义为:把一个字符串转换成另一个字符串时在单个字符上所需要的最小编辑操作(比如,插入、删除、代替)的代价数。字符串间的编辑距离可以通过动态规划的方法来计算。基于编辑距离的字符串匹配算法描述如图547所示。

d(X,Y)计算的是字符串间的绝对距离,相似度的公式如式(5-4-17)所示。
similar(X,Y)=1-d(X,Y)/Maxdis(X,Y) (5-4-17)
式中Maxdis(X,Y)表示的是字符串X和Y的最大长度。
(二)记录匹配算法
判断两条记录是否为重复记录可以采用记录相似度的方法,即通过计算字段的相似度及其权值计算记录的相似度。如果两条记录相似度超过了某个阈值(由用户预先定义的值),则认为两条记录是匹配的,否则认为它们是代表不同实体的记录。
字段的权值表明一个字段在决定两条记录相似度中的重要程度。由于记录中不同字段对反映记录特征的贡献不同,因此应为其赋予不同的权值。字段的权值可由用户根据经验分配。如果某个字段对整条记录的贡献大,重要程度高,且容易出错,则分配给它较大的权值,同时保证所有字段权值的和应该等于1。另外,在相似重复记录清洗过程中,可以对权值进行调整,以便尽可能发现更多的重复记录。
设关系表有字段F1,F2,…,Fn,其权值分别为w1,w2,…,wn。给定关系表中的两条记录X和Y,令S[1],S[2],...,S[n]为计算所得的字段相似度,则X和Y的记录相似度如式(5-5-18)所示。
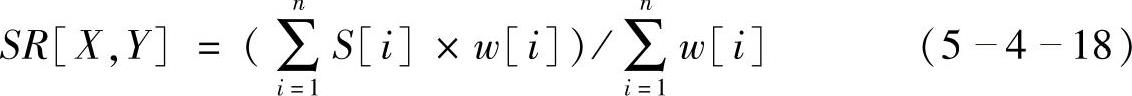
图5-4-7 基于编辑距离的字符串匹配算法流程
但由于通常情况下,字段中有可能会出现空值,当分别采用各种字段匹配算法进行匹配时,会出现较大的差距,因此需要消除字段缺失造成的负面影响。在此我们引入有效权值的概念。对上述的字段匹配公式进行修改,修改后公式如式(5-4-19)所示。
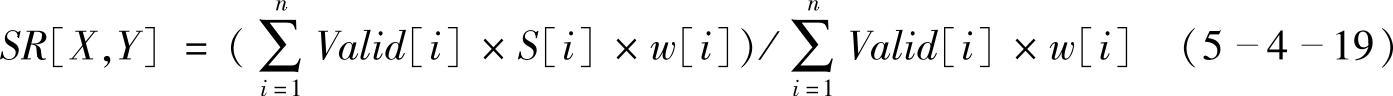
只有当两条记录在第i个属性上对应的值都不为空时,才进行字段比较,此时Valid[i]等于1,对应的权值为有效权值,否则Valid[i]等于0。设置相似度阈值δ,如果SR[X,Y]>δ,则X和Y为相似重复记录。
(三)相似重复记录检测算法改进
目前采用比较普遍的方法是基本邻近排序算法(SNM),它有下面两个重大缺陷:①对排序关键字的依赖性太大。②滑动窗口的大小w的选择很难控制。w较大时进行比较的次数多,而有些比较是没有必要的;w较小时可能漏配。
针对SNM算法存在的缺陷,Hermandez等人提出了多趟邻近排序算法(MPN),该算法的基本思想是独立地执行多趟SNM算法,每趟创建不同的排序关键字和使用相对较小的滑动窗口。然后采用基于规则的知识库来生成一个等价原理,作为合并记录的判定标准,将每趟扫描识别出的重复记录合并为一组,在合并时假定记录的重复具有传递性,即计算其传递闭包。所谓传递闭包,是指若记录R1与R2互为重复记录,R2和R3互为重复记录,则R1和R3互为重复记录。通过将每趟扫描识别出的重复记录计算传递闭包,可以得到较完全的重复记录集合,能部分解决漏配问题。
但是改进后的该算法仍然存在着以下缺陷:①识别窗口大小固定,窗口的大小选取对结果影响很大。②采用传递闭包,容易引起误识别的问题。例如,R1和R2互为重复记录,R2和R3互为重复记录,则判断R1和R3互为重复记录,同时如果R3和R4为重复记录,根据传递闭包,则判断R1和R4也互为重复记录,这样就形成多层传递关系。而多层传递关系是很不可靠的,容易形成错误的结论。
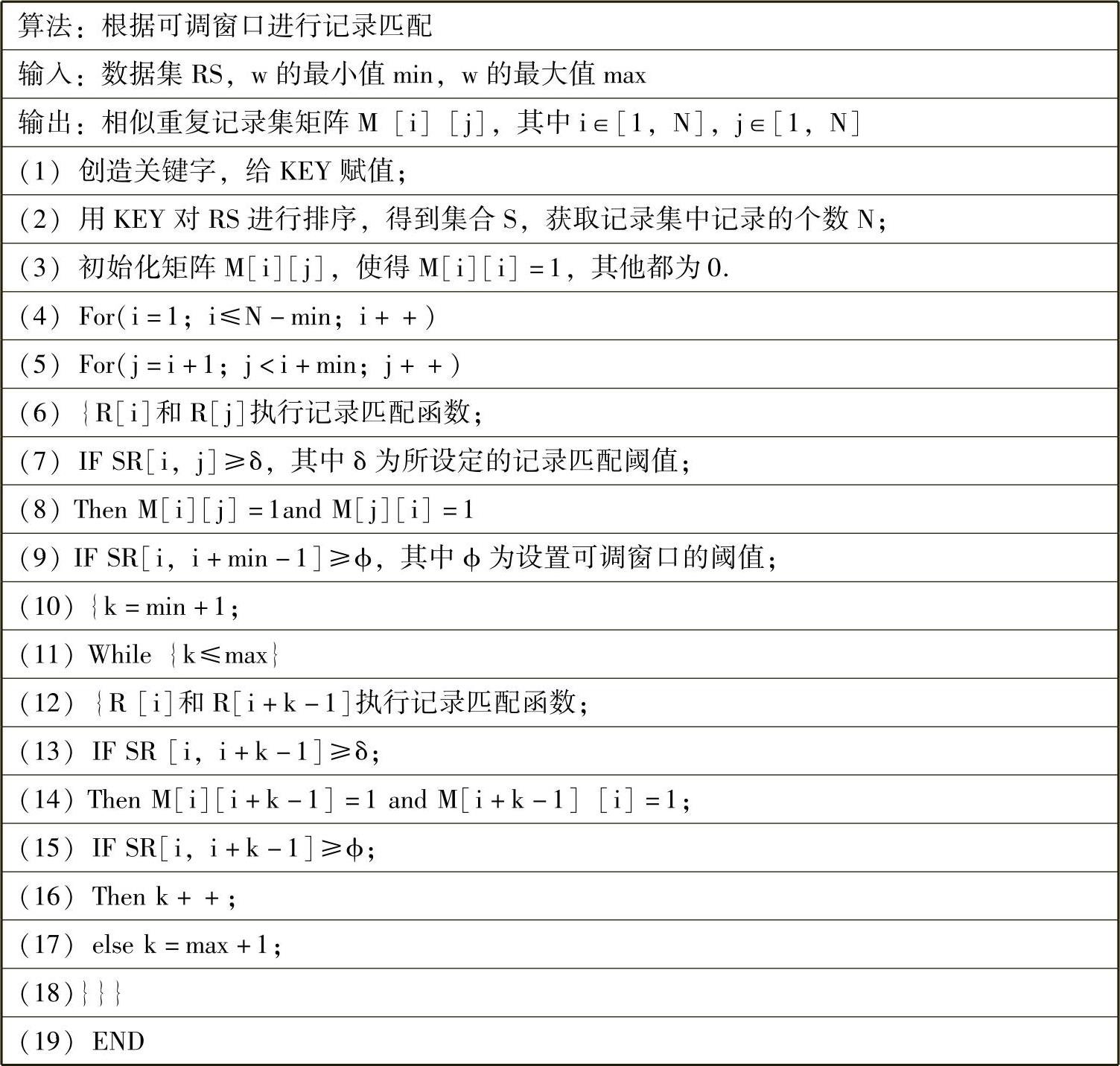
由于MPN算法存在的上述缺陷,我们将提出MPN的改进算法,主要从以下方面进行改进:将识别窗口w的大小设为一个可调节的值,为了简化,我们设为两重调节,一个值为min,另一个值为max。ϕ为阈值,窗口初始值w=min,将窗口内的记录进行匹配。当匹配到该窗口的最后一条记录时,即R1和Rmin的相似度大于ϕ,则窗口w将扩大,R1继续与下一条记录匹配。当相似度小于ϕ或窗口w>max,该次匹配终止;然后移动到记录R2进行相同的操作。改进后的算法流程如图5-4-8所示。
 (www.daowen.com)
(www.daowen.com)
图5-4-8 根据可调窗口进行记录匹配的算法流程
度量相似重复记录算法效率的主要标准是该算法能否把数据源中的所有重复记录都检测出来,常用的标准有查全率,查准率,分别定义如下:
1.查全率
查全率是指被正确识别相似重复记录数与实际的相似重复记录数的百分率,如式(5420)所示。

2.查准率
查准率是指被正确识别出的相似重复记录数与识别出的相似重复记录数的百分比,如式(5-4-21)所示。

通过简单的应用,可以发现改进后的算法在不降低算法效率的前提下,有效地减少记录的匹配次数,改进算法与原有算法的对比如表5-4-20所示。
表5-4-20 改进算法与原有算法的比较

(四)生产管理模块中的应用
在生产管理模块中重点存在以下两种相似重复记录:客户资料和销售订单表。下面将分别介绍对两种相似重复记录的检测过程。
1.客户资料
(1)属性选择和权值分配
由于“信用等级”属性在各个记录中重复性较大,所以在进行属性选择不予考虑;“客户编号”是系统自动赋给每个客户资料的唯一代码,并不反映客户内在的信息,所以也不予考虑。这样,最终选取的属性有五个,根据它们的重要性,赋予的权值如表5-4-21所示。
表5-4-21 客户资料表单属性权值分配表

(2)字段匹配和记录匹配
选取关键字段进行排序,例如在本例中我们将选择“名称”和“客户电话”进行两次排序,对排序后的结果数据集进行字段匹配,最终计算记录匹配值,如果两个记录的记录匹配值大于阈值即为相似重复记录,并予以记录下来。由于上述数据都属于字符型数据,采用编辑距离函数来进行字段匹配。注意的是在进行编辑距离的比较前需要将其中的数字以及空格删除,这是处于匹配效率以及提高匹配效果的目的。
2.销售订单
(1)属性选择和权值分配
由于“付款方式”属性在各个记录中重复性较大,在进行重复记录检测时不予考虑;“折扣”属性,也不予考虑。“订单编号”是系统自动赋给订单的一个唯一的值,所以也删除,不予考虑。最终保留下了六个属性,它们的权值分配如表5-4-22所示。
表5-4-22 销售订单表单属性权值分配表

(2)字段匹配和记录匹配
选取关键字段进行排序,我们将选择“客户编号”和“成品编号”进行两次排序,对排序后的结果数据集进行字段匹配,最终计算记录匹配值,如果两个记录的记录匹配值大于阈值即为相似重复记录,并予以记录下来。
上述数据不仅涉及了字符型数据,还有连续数值型数据,日期型数据;字符型数据采用编辑距离函数来求相似度,连续数值型数据通过式(5-4-14)来计算,日期型数据根据式(5-4-15)和式(5-4-16)计算。
在完成相似重复记录的匹配之后,还存在着合并问题,即完成数据清洗的最后一步,常见的几种合并策略有:
1)随机抽样策略:从一类的多个记录中随机选出一个。
2)最新策略:从近似的记录中选取最新的记录。
3)语义策略:选取最长的记录。
4)综合策略:综合所有相似记录,再生成一条新记录。
最后需要引起注意的是:在进行客户资料检测之后,对于删除的相似重复记录,还需要搜索其在销售订单中的所有记录,同时进行修改,从而保证数据的一致性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





