(一)异常数据的处理流程
1.连续型异常数据的处理
处理步骤如下:
(1)进行数据概化描述
1)度量数据的中心趋势。数据集的“中心”最常用、最有效的数值度量是算术均值。
尽管均值是描述数据集的最有用的单个量,但不总是度量数据中心的最好方法。均值的主要问题是对于极端值(如离群点)很敏感。
为了抵消少数极端值的影响,我们可以使用截断均值。截断均值是去掉高、低极端值得到的均值,但需要注意的是两端截断的比例避免过大,导致损失有价值的信息。
对于倾斜的(非对称的)数据,数据中心的一个较好度量是中位数。设给定的N个不同值的数据集按数值序排序。如果N是奇数,则中位数是有序集的中间值;如果N是偶数,中位数是中间两个值的平均值。
2)度量数据的离散程度。数值数据趋向于分散的程度称为数据的离差或方差。数据离散程度的最常用度量是极差、五数概括(基于四分位数)、中间四分位数极差和标准差。
(2)根据一定的方法对孤立点进行检测
可用的方法有统计、聚类等。
(3)处理满足一定规律的数据
根据一定的方法对数据进行序列预测,确定一个取值范围,并与实际的数据值进行对比,判断正误,可用于预测的方法有BP神经网络预测和回归分析预测;也可以根据一些字段之间的关系变化来发现异常数据。
图5-3-3给出了连续型异常数据的处理流程图。
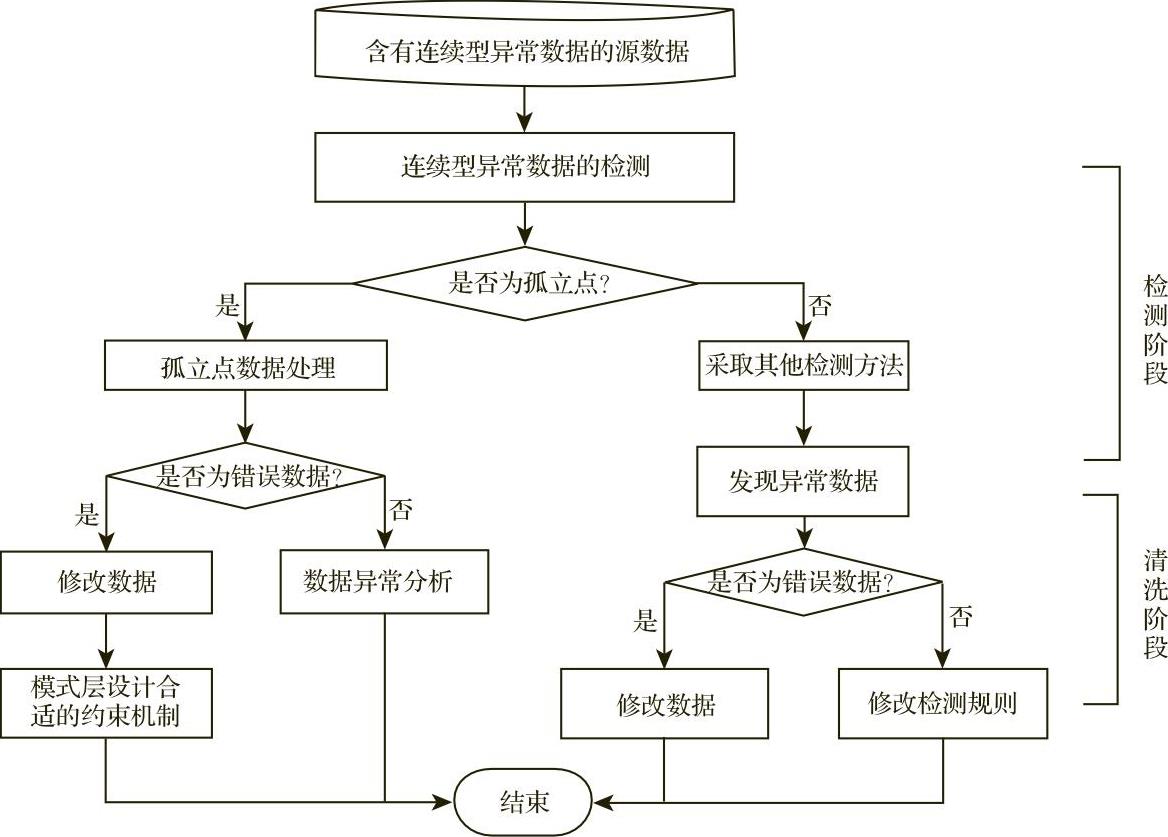
图5-3-3 连续型异常数据的处理流程
2.离散型异常数据的处理
离散型异常数据大多是由于实例层的原因而造成的,一般而言,很难通过模式层的约束来检验输入错误。离散型异常数据的处理步骤如下:①发现离散型数据与其他字段之间的内在决策关系。②确定训练样本,根据一些算法对训练样本进行训练,发现决策规则或内在联系模型,常用的算法有BP神经网络分类算法,决策树方法等。③将待检验的样本输入该模型中,发现异常的数据值并进行分析。
3.其他类型数据
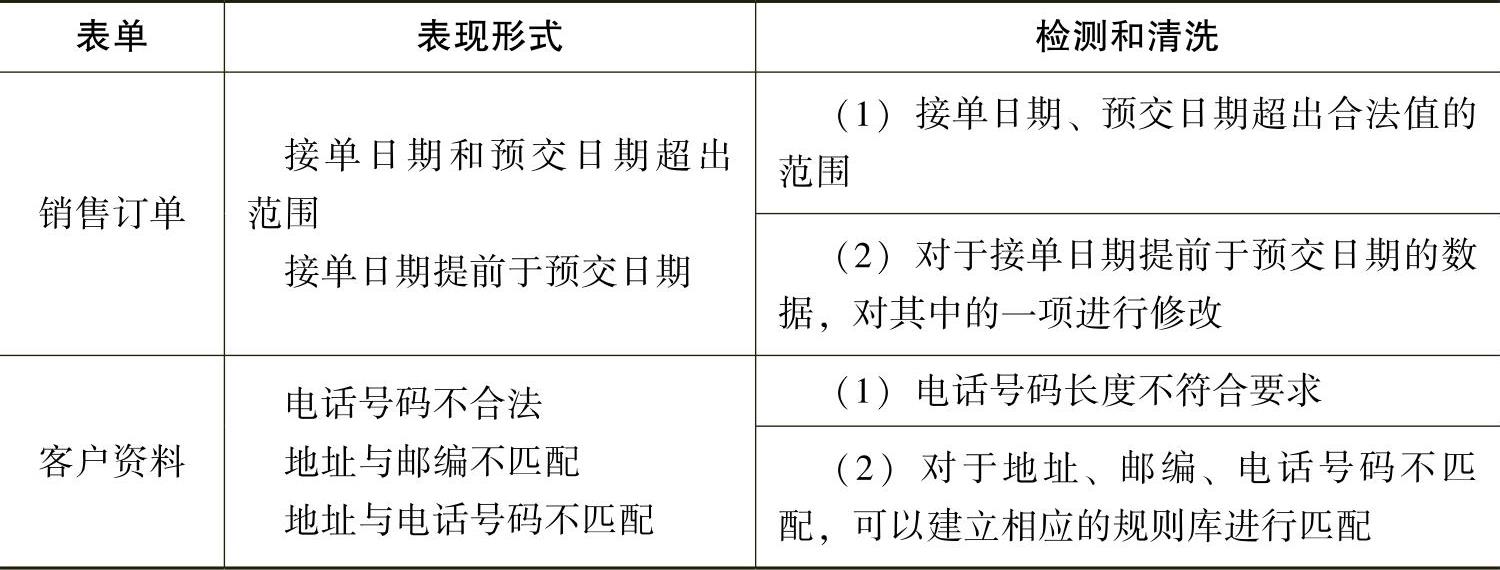
在数据库中还涉及一些其他数据,如“日期”“电话号码”等,这些类型数据的异常值可通过常识来进行判断,如“2007/2/30”就属于异常数据值。对于这类数据,需要在模式层设计时进行充分的输入约束,或者建立良好的匹配机制,如地址与邮编之间的匹配表,地址与电话号码区号的匹配等。其他类型数据的异常值检测和清洗如表5-3-4所示。
表5-3-4 其他类型数据的异常值检测和清洗
 (https://www.daowen.com)
(https://www.daowen.com)
(二)相似重复记录的处理流程
目前比较常用的重复记录清洗是先将数据库中的记录排序,然后比较邻近记录是否匹配来检测相似重复记录。图5-3-4给出了相似重复记录的处理流程图。
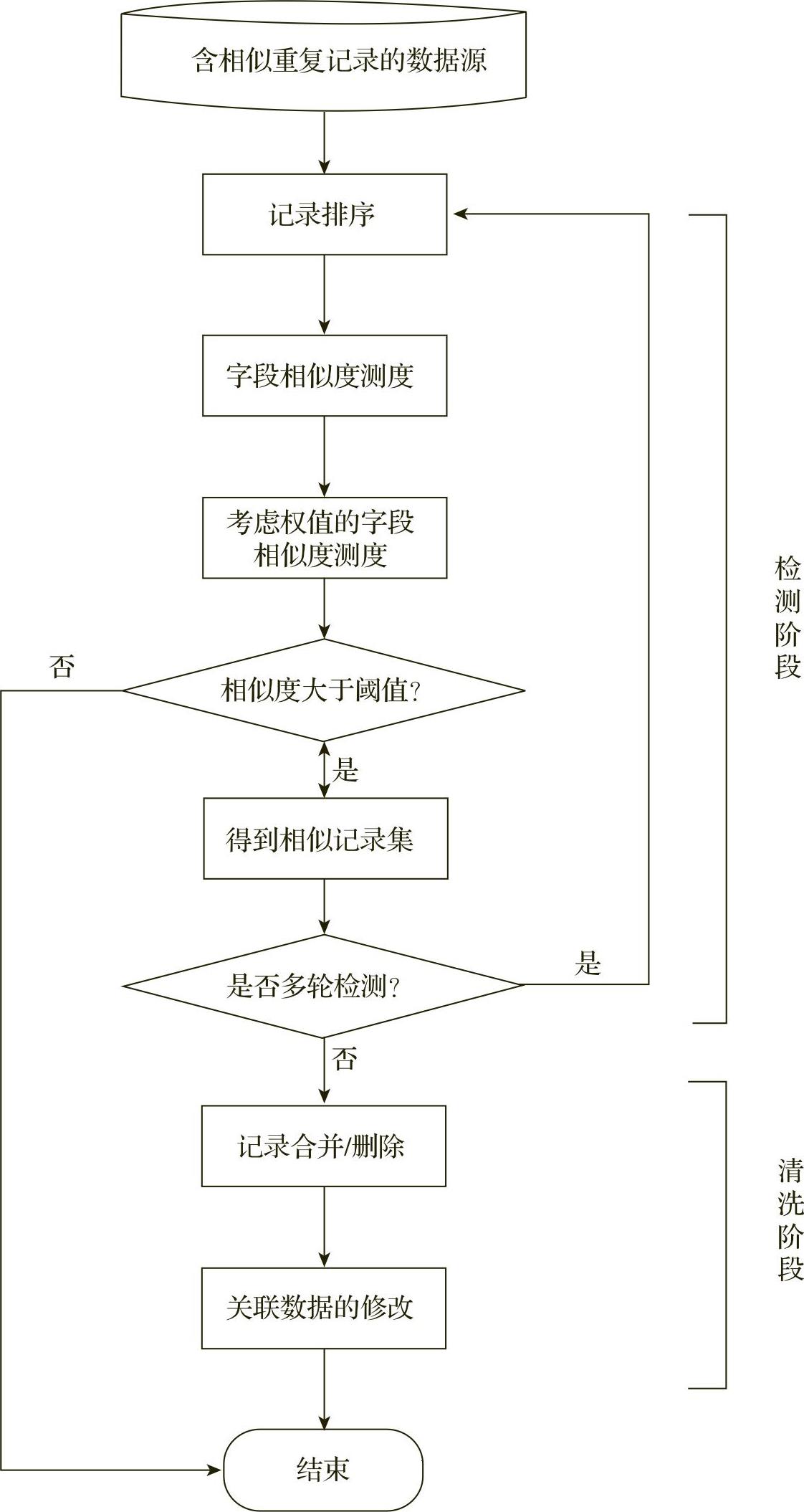
图5-3-4 相似重复记录的处理流程图
1.记录排序
(1)预处理
制定初步的记录匹配策略,建立算法库和规则库。
(2)初步聚类
主要是对数据库中的记录进行初步排序。
2.相似记录检测
(1)字段匹配
选择用于字段匹配的属性,调用算法库中的字段匹配算法,计算出字段的相似度。
(2)记录匹配
根据属性在检测相似重复记录中的重要程度的差别,赋予每个属性不同的权重,调用算法库中记录匹配算法,结合上一步的字段相似度的结果计算出记录相似度,判断是否为相似重复记录。
(3)重复记录检测
在数据库应用检测重复记录的算法对整个数据集中的重复记录进行检测。为了能检测出更多的重复记录,一次排序不够,要采用多轮排序,多轮比较,每次排序采用不同的键,然后把检测到的所有重复记录聚类在一起,从而完成相似重复记录的检测。
3.记录的合并/删除
对相似重复记录进行合并、删除,只保留其中正确的记录。
4.关联数据的修改
对相似重复记录进行合并或删除,会对数据库中其他数据产生影响,例如客户资料的删除会导致销售订单中某些记录的客户编号在客户资料中找不到对应的编号,从而对数据的一致性产生负面的影响。因此需要将记录进行合并/删除之前,对关联数据表中的数据进行一致的修改,从而保证数据的一致性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





