(一)不完整数据的处理流程
为了检测和清洗不完整数据,首先要检测不完整的数据,其次是对不完整数据的处理。
对不完整数据处理分为以下几步来完成:
1.判断数据的可用性
如果一条记录中字段值缺失的太多,或者是关键的字段值缺失,就没有必要去处理该记录。因此,对于检测出的不完整数据,要根据每一条记录的不完整程度以及其他因素,来决定这些记录是保留还是删除。
2.忽略缺失字段的值
对于不重要的字段值缺失,一般采取忽略的方法。如果某一属性中大多数的字段都是缺失的,可以考虑是否保留该属性。
3.填充缺失字段的值
对于那些要保留的记录,要采取一定的方法来处理该记录中缺失的字段值,一般可采取填充的办法。可以参照原始单据进行填充,如果原始单据中也是空值,由于多数情况下,字段值之间并不是相互独立,可以根据关联规则、预测等方法进行填充缺失的字段值。
图5-3-1给出了不完整数据的处理流程图。
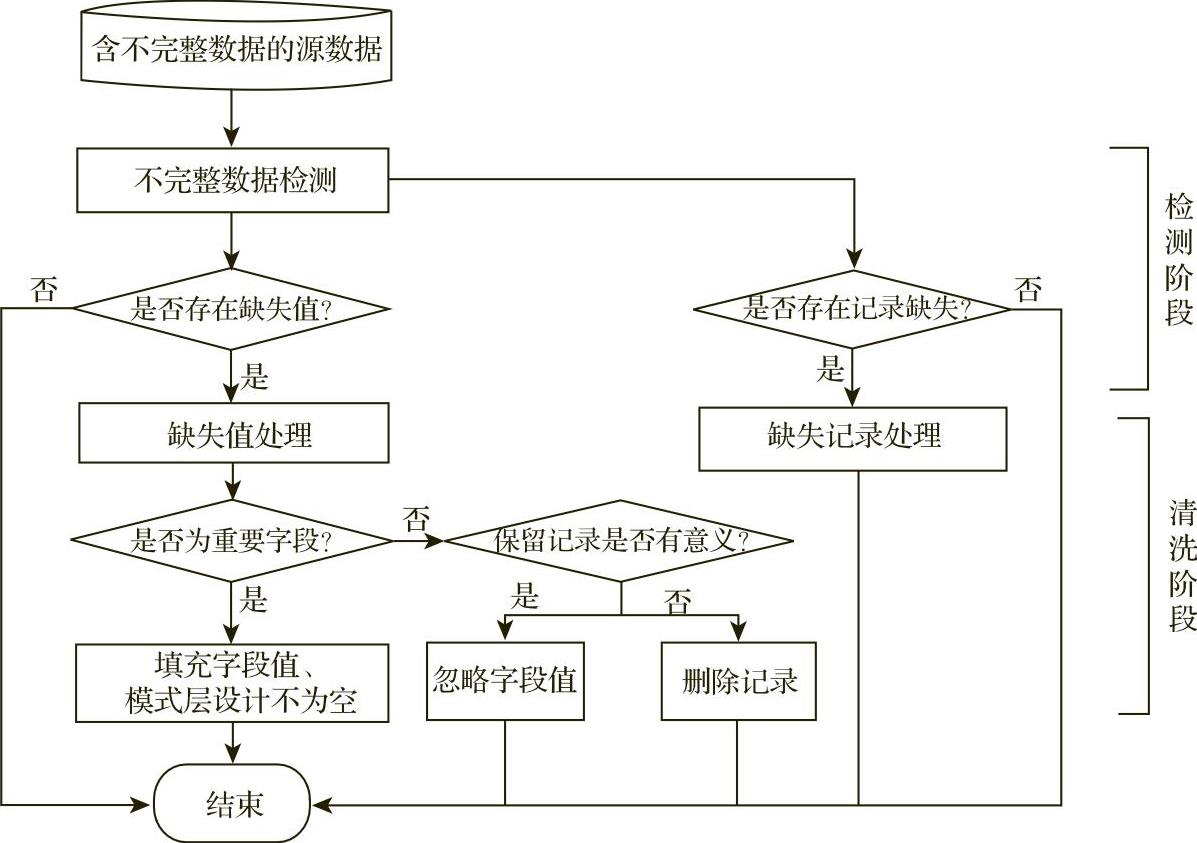
图5-3-1 不完整数据的处理流程图
(二)缺失值的填充
使用忽略缺失字段值的方法比较简单,但有可能将有该记录有关的有价值的信息一并删除。因此我们一般建议是把那些不完整的数据填充,而不是删除掉。
缺失值填充算法也是数据清洗领域研究的热点之一,缺失值填充即把缺失值用最接近它的值来替代,从而提高数据的质量。
常见的集中处理方法有:
1.人工填写缺失值
该方法很费时,并且当数据集很大、缺失值很多时,该方法可能行不通。
2.常量值替代法
常量值替代法就是对所有缺失的字段值用同一个常量(如“Unknown”或-∞)来填充。由于所有的缺失值都被当成同一个值,容易导致错误的结果。尽管该方法简单,但并不十分可靠。(https://www.daowen.com)
3.采用统计的方法
这类方法主要是通过对数据的分析,得出数据集的统计信息,然后利用这些信息填充缺失值。其中最简单也是最常用的方法是平均值填充方法和最大概率填充方法。
均值填充法是把完整数据的算术平均值作为缺失数据的值,它是根据正态分布的原理,“在正态分布下,样本均值是估算出的最佳的可能取值”。均值填充法的缺陷在于会影响缺失数据与其他数据之间的相关性。
最大概率法是选择数据集中出现次数最多的值来填充缺失值。
4.采用估算值的方法
估算值替代法比较复杂,但它是比较科学的一种方法。首先采用相关算法,如用判定树归纳、回归、神经网络等方法来预测并进行填充。比较适用于连续型数值的填充。
5.采用分类的方法
分类是在已有数据的基础上构造出一个分类函数或模型,即通常所说的分类器。该函数或模型能够把数据库中的数据记录映射到给定类别中的某一个类别。常见的分类技术如贝叶斯网络、神经网络、粗糙集理论以及决策树等。主要适用于离散型数值的填充。
6.基于规则的方法
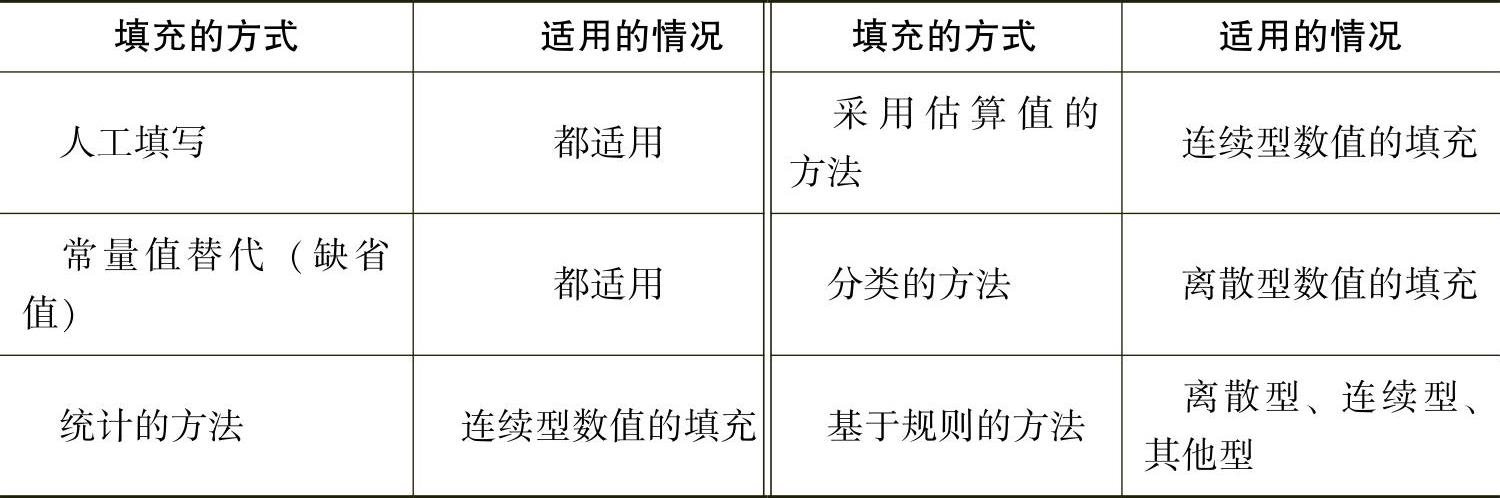
系统中的数据之间存在着一定的勾稽关系,或是依据某种约束关系。可以根据这些勾稽关系和约束关系来填充不完整的数据。填充方法的对比如表5-3-1所示。
表5-3-1 填充方法的对比
(三)数据不完整性改善在生产管理模块中的应用
针对生产管理系统中的不完整数据,其检测主要分为以下几个步骤:①查找需要连续编号的记录是否满足编号的连续性。②重要字段在设计时设置为“不允许空”,那么查找重要字段值为缺省值的记录。③重要字段在设计时设置为“允许空”,那么查找重要字段值为空值的记录,并根据空值的情况判断是否为缺失值,并进行填充。
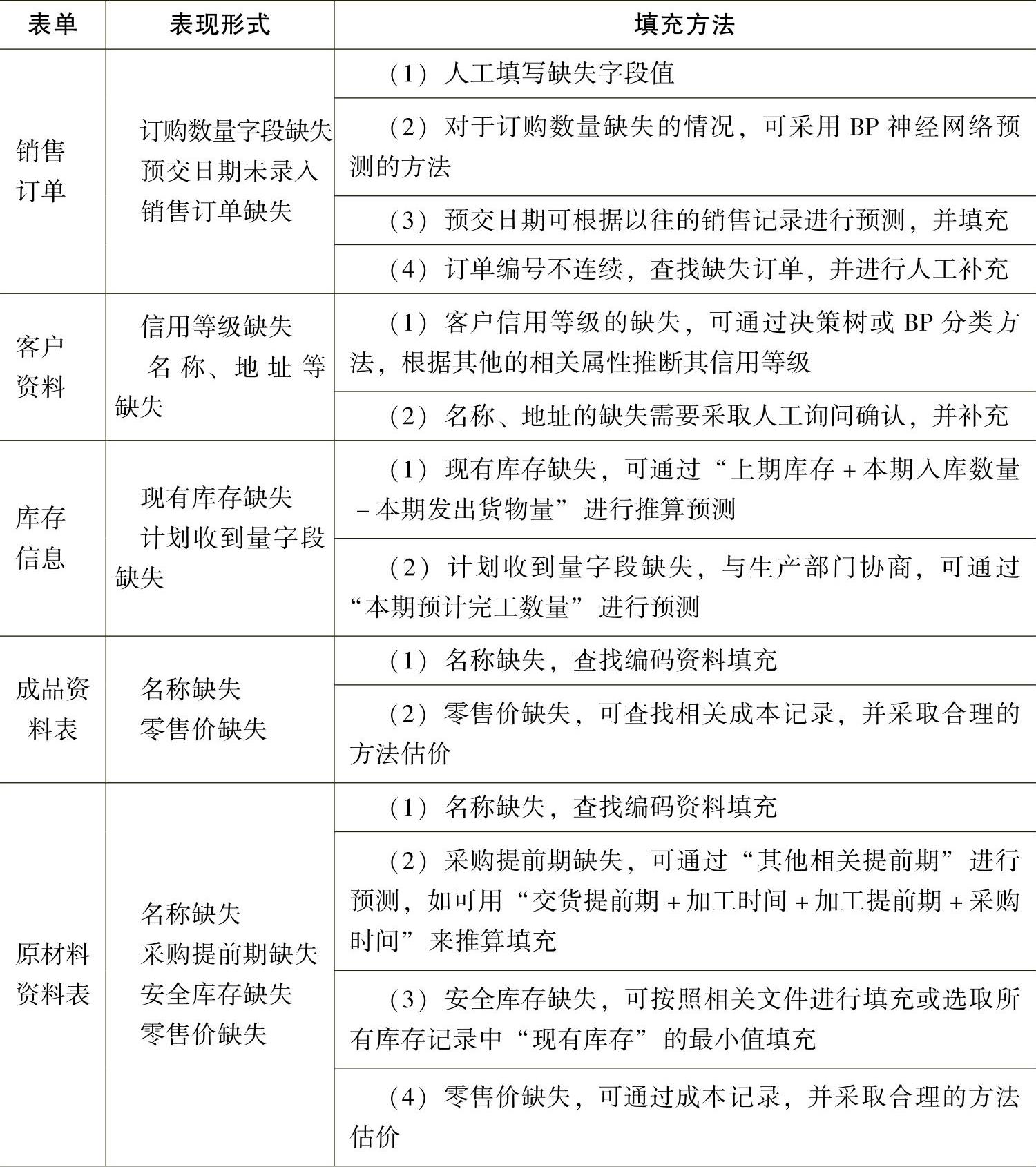
以生产管理模块为例,其缺失值的填充方法如表5-3-2所示。
表5-3-2 生产管理模块的缺失值填充
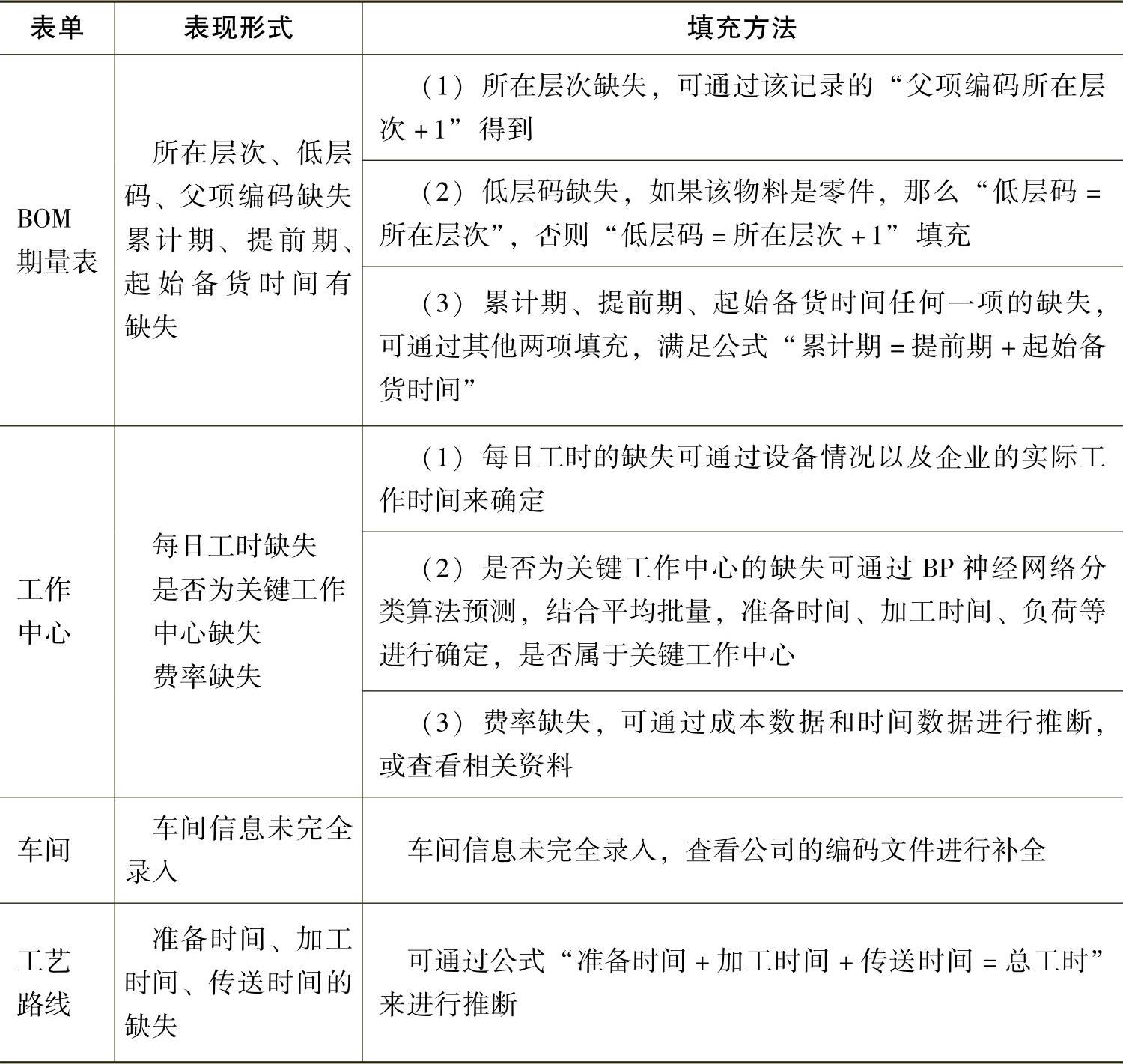
(续)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





