(一)原始表单
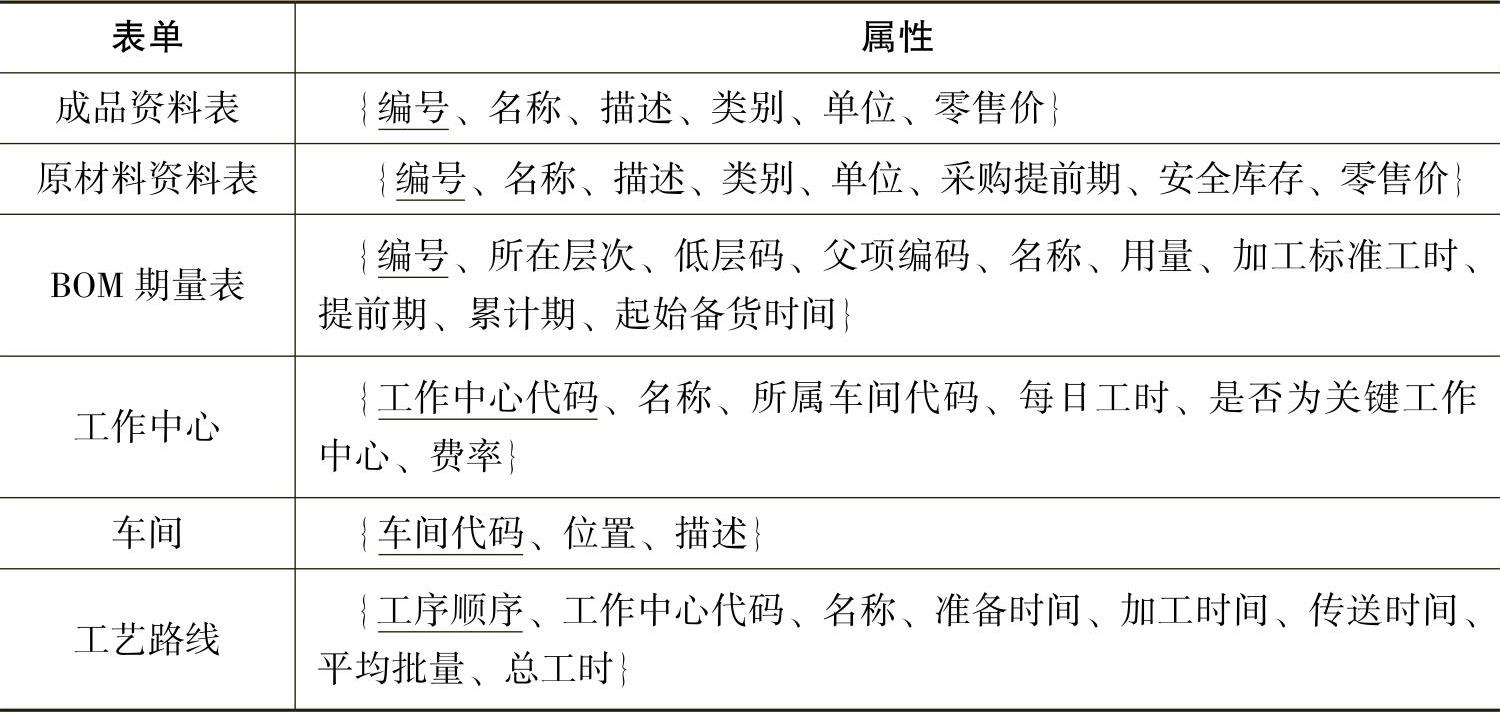
生产管理系统中涉及大量的表单,考虑到表单在数据库中的重要性,我们将选取销售订单、客户资料、库存信息、BOM期量表、成品资料表、原材料资料表、工作中心、车间、工艺路线等九个重要表单来进行分析,每个表单所涉及的属性如表5-2-2所示。
表5-2-2 关键数据表的属性

(续)
(二)数据的分类
在ERP系统中,根据数据的易变性将原始表单分为两类:静态数据和动态数据,如图5-2-3所示。

图5-2-3 ERP系统中数据处理流程
1.静态数据(或称固定信息)
静态数据一般是指生产活动之前要准备的数据,如BOM期量表、工作中心的能力参数、工艺路线、仓位代码等。我们所处的客观环境是不断变化的,因此所谓的静态也是相对的,就是说即使是静态数据,也要定期维护,保证其数据质量。
2.动态数据(或称流动信息)
动态数据一般是指生产活动中发生的数据,它们是不断发生、经常变动的。如销售订单、库存记录、完工报告等。一旦建立,需要随时维护。
结合上述的分析,可以将基础数据划分为两类,静态数据和动态数据,分类结果如表5-2-3所示。
表5-2-3 原始表单的分类

(三)脏数据的常见形式
脏数据指的是系统中的不准确、不一致、不完整以及不及时的数据。脏数据的存在将导致系统中数据质量下降,提高数据质量策略之一就是检测和清洗系统中的脏数据。
在本章中我们将按照常见的数据质量评价维度[5]将脏数据分为不准确的数据、不一致的数据、不完整的数据和不及时的数据。
1.不完整的数据
完整性一般是指数据的宽度、深度和规模满足相应需求的充分程度。数据的宽度和深度主要是从模式设计的角度来看,是否包含了应有的概念和属性;数据的规模主要是从实例层的角度而言,从字段的层次来看,若数据库中某条记录存在一个或一个以上的属性值为空,则认为该记录存在缺失值,不满足完整性的要求;从记录的层次来看,是否存在缺失的记录。本章主要关注的是实例层的问题,下面将从实例层的角度来对不完整数据进行分析,如表5-2-4所示。
表5-2-4 不完整数据示例

表5-2-4是成品资料表中的一些数据,表中给出了一些不完整数据的例子。在这个表中,由于种种原因,记录中的一些字段值为空值,如第一条记录中的“类别”和“零售价”为空,第二条记录中的“单位”为空。这种现象在数据库中经常出现,不完整数据的存在不但会影响企业信息系统的正常运行,而且也会对企业的业务运作产生负面的影响,还会引起决策支持系统的错误,产生不正确的分析结果,特别是记录中关键字段的缺失,或者数字型字段出现空值,因此必须要解决数据库中数据的不完整问题。
除了上述字段缺失的情况外,还有可能会出现少录入的情况。例如一条销售订单由于各种原因未录入到数据库中,游离于系统外。
2.不一致的数据
在企业的信息系统中包含着众多的关系模式,相同的属性有可能同时被多个关系模式所包含,这就需要设计时对不同表中的相同属性采用同样的命名、类型以及属性定义等。例如常见的参照完整性约束,指的是一个关系中的参照属性必须被参照关系中的主键属性所包含。如果不同关系表中的同一属性取值出现明显的不一致时,则表示系统中出现了不一致的数据。
表5-2-5和表5-2-6列出了单数据源和多数据源情况下常见的数据不一致情况。在本章中我们只讨论单数据源情况下数据质量的改进。
表5-2-5 单数据源中数据不一致的情况
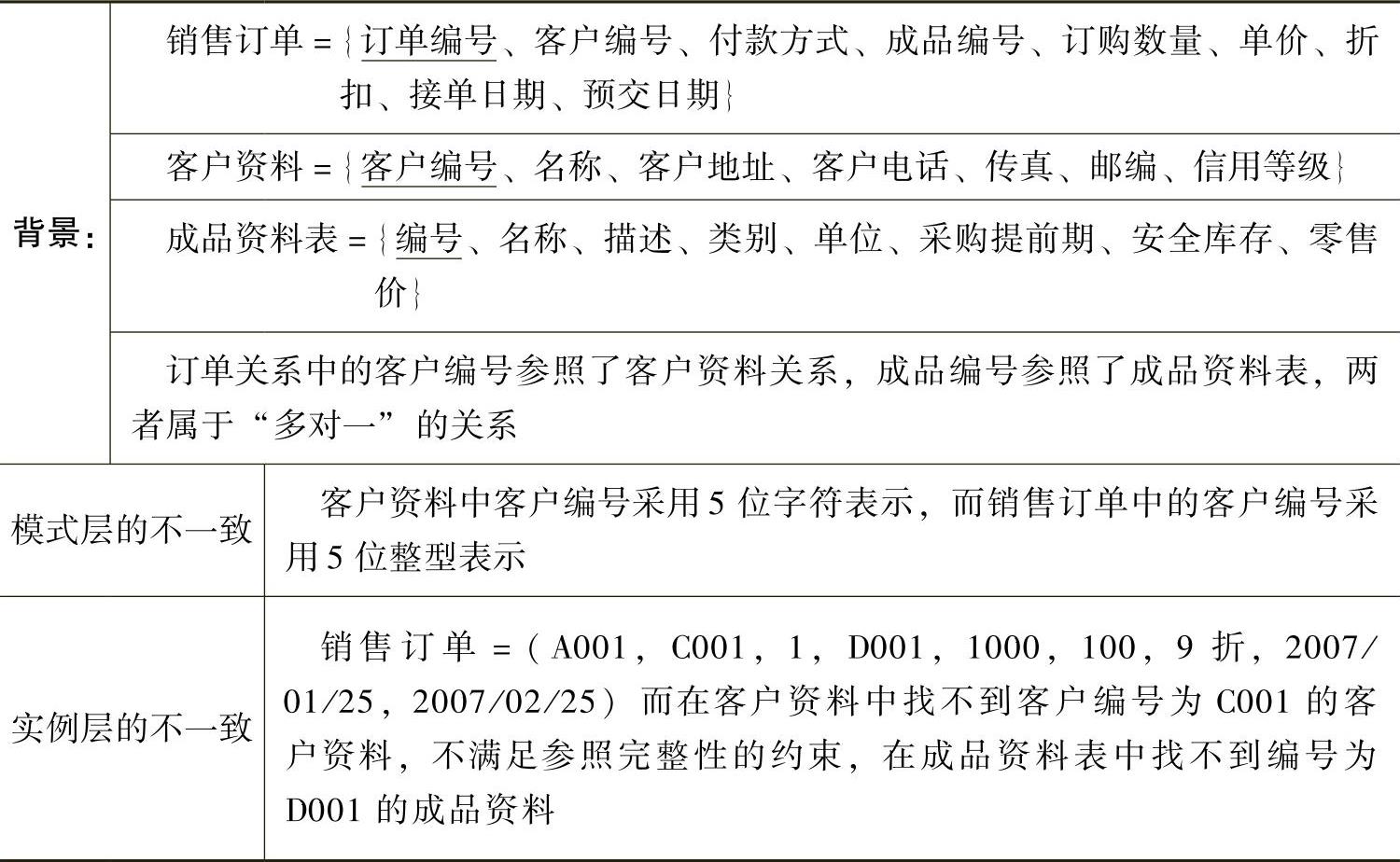
表5-2-6 多数据源不一致数据的情况
 (https://www.daowen.com)
(https://www.daowen.com)
3.不准确的数据
如果从字段的层次来定义,准确性是指一个记录的字段值v′与被认为正确的某个值v之间相一致或相接近的程度。从记录的层次来定义,准确性指的是相同的现实实体在数据库中只有一条记录与之相对应,而不存在多条记录与之相对应的情况。
根据上述的定义,可以将不准确数据分为两种形式:一种是指字段中存在错误;另一种是数据的重复录入,造成数据库中相似重复记录的存在。
(1)异常数据
针对第一种错误类型,被称为异常数据。根据字段的数据格式分为以下三类:
1)连续型异常数据。主要是指连续型数值存在错误。例如,销售订单中订购数量的错误,或库存信息中现有库存数据的错误。
2)离散型异常数据。在信息系统数据库中,存在着大量的离散型数值,这些数据往往以一种离散的形式存在,如性别的取值为“0/1”,销售商信用水平的度量分为“优秀/良好/一般/较差”等几个等级,往往数据库中离散数据的错误将会导致企业作出错误的决策。例如销售商的信用等级原本是较低的,但由于错误的数据录入导致销售商的评级增高,从而给予了较高赊销额度,这种错误的决策将会给企业带来巨大的风险。
3)其他类型异常数据。在数据库中还涉及一些其他数据,如“日期”“电话号码”等,这些类型数据的异常值可通过常识来进行判断,如“2007/2/30”就属于异常数据值。
表527是销售订单表中的一些数据,表中给出了一些错误数据的例子。在这个表中,由于种种原因,记录中包含有一些错误数据。比如订单编号为A0018的“订购数量”应为“1400”而非“140”,单价折扣对应的应为“8折”而非“全价”,预交日期应为“2007/2/28”而非“2007/2/31”。
表5-2-7 异常数据表

(2)相似重复记录
所谓的相似重复记录指的是一个现实实体可能由多个完全不同的记录来表示。产生相似记录的原因有很多方面:包括数据录入员的失误、不同的缩写形式、自由格式的文本以及数据的变迁等。
相似重复记录的判断是个复杂的问题。在关系数据库中判断两条记录是否重复,这需要通过记录的比较决定记录间的相似程度,即通过记录各字段值语法上的比较结果,决定两条记录语义上的等价性,这也称为记录的匹配问题。现实中的数据又是比较复杂的,两条记录是否描述的是同一实体有时还要根据实际情况来判断。表5-2-8给出了相似重复记录的实例。表中描述的对象是同一实体,但由于操作员的错误将相同客户信息又重新输入了一遍,从而产生了相似重复记录。
表5-2-8 相似重复记录实例

相似重复的存在将造成以下问题:
1)损害信息的一致性。多条相似记录在数据库中以不同的主键来标识,它们的信息可能互为补充,但存在冗余,而且可能相互矛盾。当现实世界中的实体发生状态改变时,操作员会更新这些相似记录中的某个“代表记录”,而其余的记录往往得不到同步更新,这样会进一步损害信息的一致性。
2)资源浪费。相似重复记录不仅会造成数据库中的数据冗余,浪费存储空间,更坏的情况下可能使客户产生不满。例如,企业为了维持良好的客户关系,经常会给客户邮寄许多产品资料,如果信息系统中存在相似重复记录,则就会给客户邮寄多份重复资料,造成企业不必要的浪费,同时也给客户带来麻烦。
4.不及时的数据
及时性是指一个属性值在时刻T以前是正确的,在时刻T是错误的,那么它在T时刻是过去状态,必须进行实时更新,及时性可以用过时的时间长度来度量。及时性的定量评价可采用0~1范围内的数据来表示,计算公式为:
Timeliness={max[(1-currency/shelf-life),0]}δ (5-2-1)
其中currency是通过最后更新数据的时间来测度,对应的是数据被更新的最后时间点;shelf-life代表的是数据的保质期,易变性强的数据对应的shelf-life值则非常小,相反易变性弱的数据对应的shelf-life值则非常大;δ是一个参数,用于控制Timeliness与currency/shelf-life比率的敏感性。
对于静态数据而言,其变动频率很小,一般不需要对及时性进行特殊的关注;但对于动态数据而言,其变动频率较大,数据是否及时会直接影响到企业的运行和决策。ERP系统中经常存在着这样的情况:取消的销售订单依然在执行,成品退库的信息未及时录入到系统中,导致成品实际已经退回入库,但系统中却没有此产品退库的记录。
不及时数据主要是由于数据更新的不及时、各部门之间协调沟通不畅所造成,很难通过清洗的方式来发现数据中的问题。企业可以采用以下方式来提高数据的及时性:
1)取消的销售订单首先及时通知销售部门将订单数据进行修改,同时告知生产部门对生产计划进行调整,通知财务部门对取消的销售订单进行相应的会计处理;
2)对于退库的产成品,需要库存部门及时对产成品进行入库登记,同时通知销售部门、财务部门、生产部门对销售数据、会计数据、生产计划进行修改,从而保证系统中数据的及时、一致。
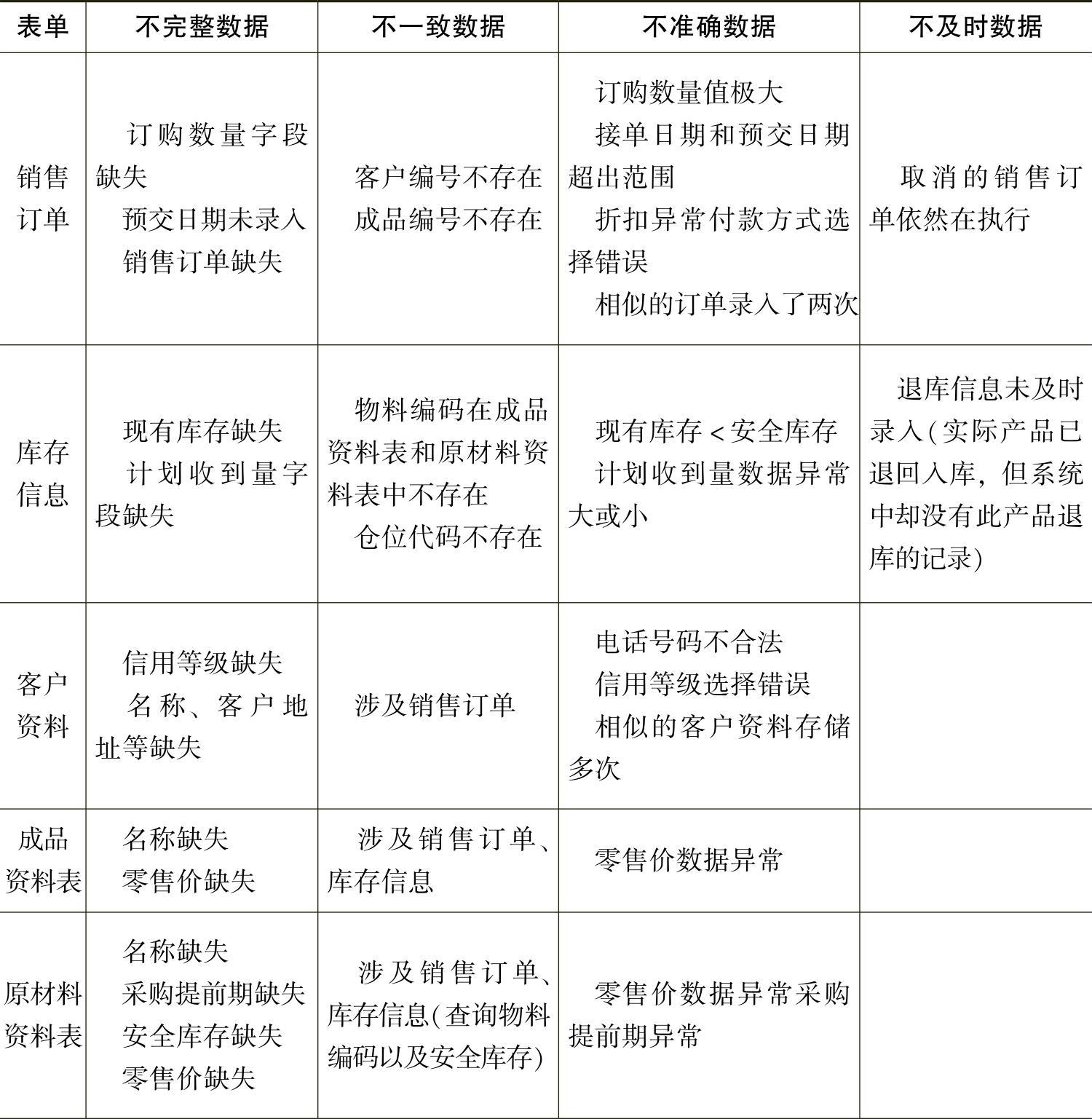
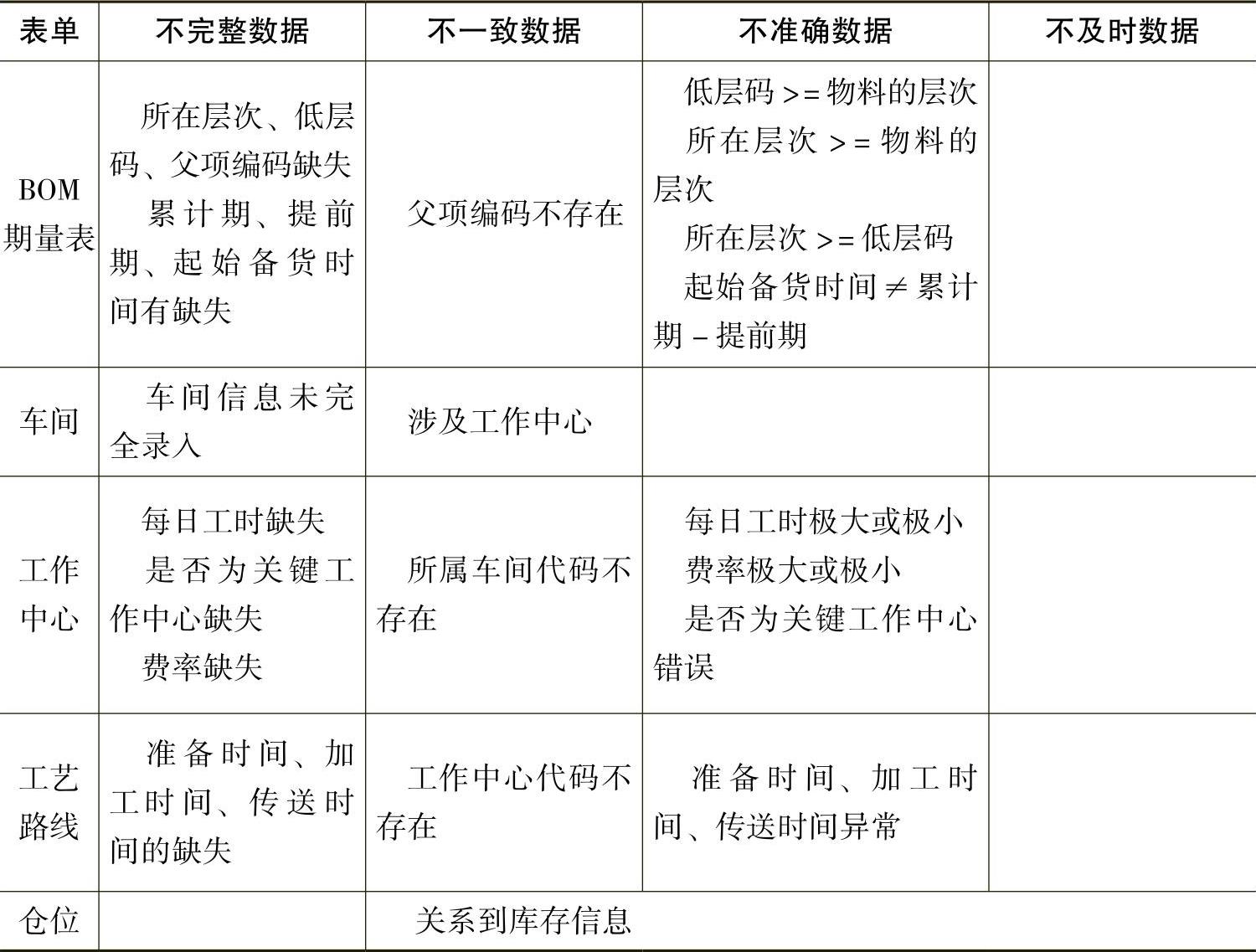
根据上述的四种分类,表5-2-9列出了ERP系统中生产管理模块中脏数据的常见形式。
表5-2-9 生产管理模块中脏数据的常见形式
(续)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







