(一)数据质量的定义
数据是信息的载体,好的数据质量是各种数据分析如OLAP、数据挖掘等能够得到有意义结果的基本条件。
目前对数据质量有不同的定义,Huang KT的文献[61]认为数据质量是数据适合使用的程度。Kahn BK等和Faloutsos C等的文献[62,63]认为数据质量是数据满足特定用户期望的程度。Aebi D等的文献[64]认为,数据质量主要指一个信息系统在多大程度上实现了模式和数据实例的一致性,及模式和数据实例在多大程度上实现了准确性、一致性、完整性和最小性。
(二)数据质量的分类
我们可以将数据源中数据质量问题划分为单数据源质量问题和多数据源质量问题两大类,每一类又根据模式相关和实例相关两个方面进一步划分为单数[65]据源模式问题、单数据源实例问题、多数据源模式问题和多数据源实例问题。如图5-1-1所示,并列出了各类有代表性的数据质量问题。
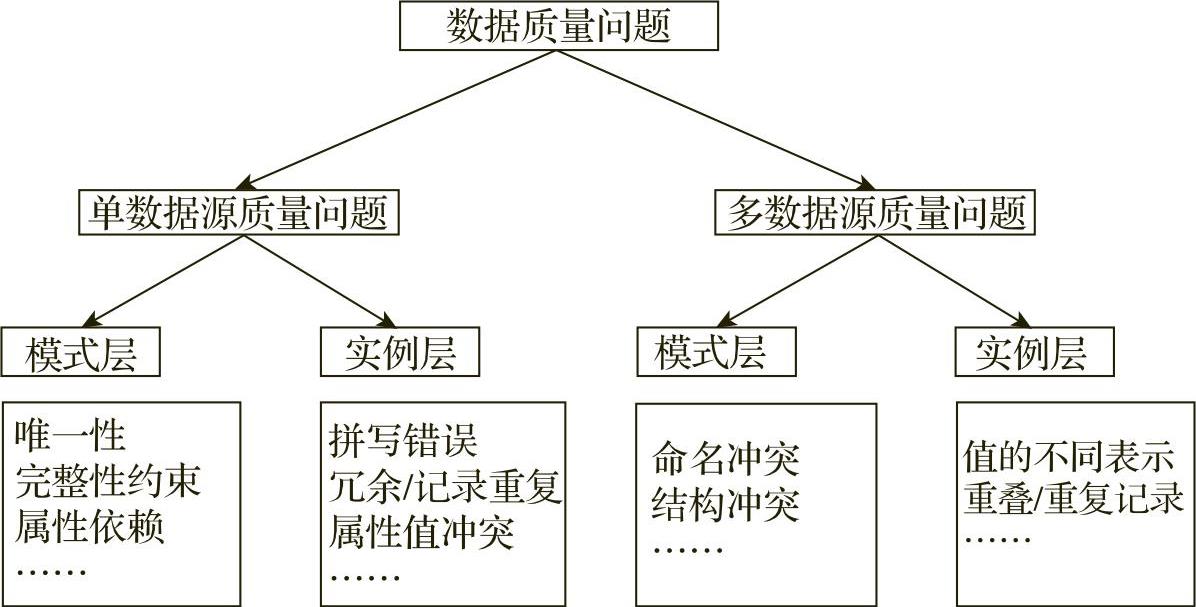
图5-1-1 数据源中数据质量的分类
1.单数据源问题
模式相关的数据质量问题是由于缺乏合适的数据模型或特定应用的完整性约束而引起的。模式相关的问题可以进一步细分为属性(字段)、记录、记录类型以及源数据四种不同范围的错误。属性出现的错误主要是数据错误,例如该库存信息中的现有库存低于安全库存;记录的错误主要是属性依赖性错误,例如BOM期量表中起始备货日期不等于累计期减去提前期的值;记录类型错误一般是指唯一键冲突的错误;源数据出现的错误是指参照完整性的冲突。
实例相关的问题是在模式层次上无法避免的问题。典型的实例相关的问题包括:①空缺值,在一些记录的属性上没有记录值,这往往由于在数据输入时没有合适的数据或者采用缺省值等而引起。②拼写错误。③缩写错误,如将Data Mining缩写为DM;内嵌数据,一个字段包括多个数据,这经常出现在一些具有自由格式的字段中。④属性依赖冲突,如城市名与邮政编码应该相对应。⑤数据重复,如由于数据输入的错误导致有多条记录表示现实世界中的同一个实体。
2.多数据源问题
在单数据源情况下出现的问题在多数据源情况下变得更加严重。在每个数据源中都有可能包含脏数据,而且每个数据源中的数据表示方法都不相同,还可能出现数据重叠或者矛盾冲突。因为在很多情况下,各个数据源都是为了满足某一个特定的需要而简单设计、配置和维护的,这在很大程度上导致了数据库管理系统、数据模型等的异构性。
在多数据源中存在的模式相关的问题主要是名字冲突和结构冲突。名字冲突表现在同一个名字表示不同的对象或不同的名字表示同一个对象;结构冲突的典型表现是在不同的源中同一对象用不同的表示方式。
除了模式相关的质量问题外,许多质量问题只出现在实例层次上,如单数据源中所出现的问题都将以不同方式出现在多数据源中,如重复记录、矛盾记录等。即使在具有相同属性名称和数据类型的情况下,各异构数据源中的数据也可能有不同的表示方式或不同的解释,信息的力度以及代表的时间点都有可能不同。
(三)数据质量的评估
目前还没有系统化的数据质量评估指标,现有的数据质量评估往往只针对系统中比较重要的指标,如一致性问题、准确性问题、完整性问题等。(https://www.daowen.com)
数据质量评估是解决数据质量问题的一个源头性问题。尽管对数据质量的定义有着不同的看法,但一般认为数据质量是一个层次分类的概念,每个质量类最终分解成具体的数据质量维度。数据质量评估的核心在于如何具体地评估各个维度,目前方法主要分为两类:定性的分析策略和定量的分析策略。
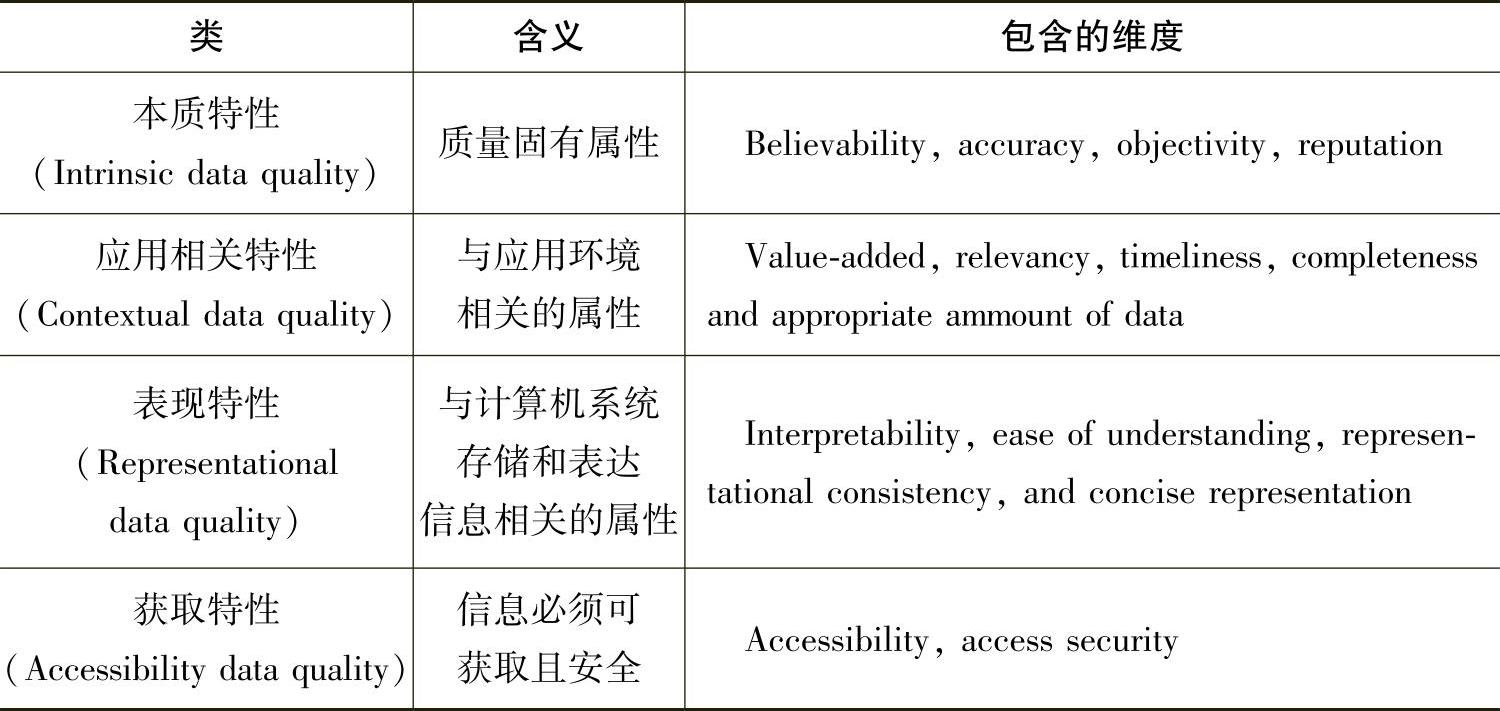
定性分析策略的研究主要侧重于维度的定义,以及采取定性的分析方法(如发放调查问卷)来获得某一个具体维度的评估值,但缺乏客观、量化的分析。Ballou DP等的文献[66]最早提出了数据质量的属性,主要包括准确性、一致性、完整性和及时性。WandY的文献[67]指出数据质量是一个多维度的概念,作者从数据消费者的角度将与数据质量有关的118个属性归纳为15个维度,划分为4个大类,如表511所示。
Tayi GK等的文献[68]提出了数据工程中数据质量的需求分析和模型,认为存在许多候选的数据质量衡量指标,用户应根据应用的需求选择其中一部分。指标分为两类:数据质量指示器和数据质量参数。前者是客观的信息,比如数据的收集时间,来源等;后者是主观性的,比如数据来源的可信度、数据的及时性等。Redman TC的文献[69]指出了一些数据质量的评估指标。在进行数据质量评估时,要根据具体的数据质量评估需求对数据质量评估指标进行相应的取舍。
表5-1-1 数据质量维度描述
Parssian A等的文献[70]中提出应在本体的概念上来理解数据质量各个维度的含义,避免数据质量维度的定义缺乏统一的语义基础。数据新鲜度在分布式系统的数据利用中尤为重要,Parssian A等的文献[71]中从数据抽取延误和原始数据更新频度两个因素进行了分析。
由于定性的分析缺乏客观性和可重现性,定量评估技术成为一个值得关注的方向,目前这个方面的研究主要集中在关系数据库中数据的质量评估技术。Misster P等和Yang WL等的文献[72,73]中采取取样计算的方法,对关系数据库中数据质量的两个维度即精确度和完整度进行量化,并具体分析了四种常见的关系代数操作:选择、投影、笛卡儿积、连接等对数据质量的影响。Shankaranarayan G等的文献[74]提出针对特定的领域可以通过源数据来定义质量视图,通过这个质量视图来指导具体的数据处理过程。
还有一些研究者为了更客观地评价数据质量,分别从不同对象的角度对数据质量进行评价,最后分析偏差,寻找原因。鲍玉斌的文献[75]中提出了AIMQ方法对数据质量进行测度,将问卷的访问者分为两类:数据用户和数据管理者,最后对评价结果进行偏差分析,并提出改进方案。
需要指出的是数据质量的各个指标之间并不是相互独立的,它们之间存在着相关性。假如在某一应用领域一个指标被认为比其他指标更重要时,提高该指标意味着对其他指标将产生负面影响。常见需要做出指标之间权衡的有:及时性与准确性之间,完整性和一致性之间。
可以看到数据质量的评估已经开始引起大家的重视,但在定量评估方面,还有待进一步的探索和研究。
(四)数据质量的改进
提高数据质量的策略多种多样,可以从不同的角度进行分类。数据质量提高策略可以分别从问题的发生时间或质量问题解决依赖的知识两个角度来划分。首先从问题的发生时间来看,数据质量的提高主要分两个角度来考虑:一类是从预防的角度,即在数据生命周期的任何一个阶段,都有严格的数据规划和约束来防止脏数据的产生;另一类是事后诊断,即由于数据的演化或集成,会有脏数据的逐渐涌现,必须采取特定的算法检测出现的脏数据。从数据质量问题解决依赖的知识来看,数据质量提高策略分为两类:一类提高不依赖特定业务规则,是应用独立的,如数据拼写错误、分布异常、某些缺失值处理等,这类问题的解决不依赖于特定的业务规则,可以从数据本身寻找特征来解决;另一类解决方法与特定业务规则有关,是应用依赖的,这些相关的领域知识是消除数据逻辑错误的必需条件。
张云涛,龚玲的文献[76]中将全面质量管理理论应用到数据领域,提出了全面数据质量管理方法(Total Data Quality Management,TDQM)。全面数据质量管理是将产品质量管理的理念引入信息产品领域,分为四个阶段:定义、测度、分析和改进。这些阶段是相互执行的,构成了一个循环。图512为全面数据质量管理进程图。
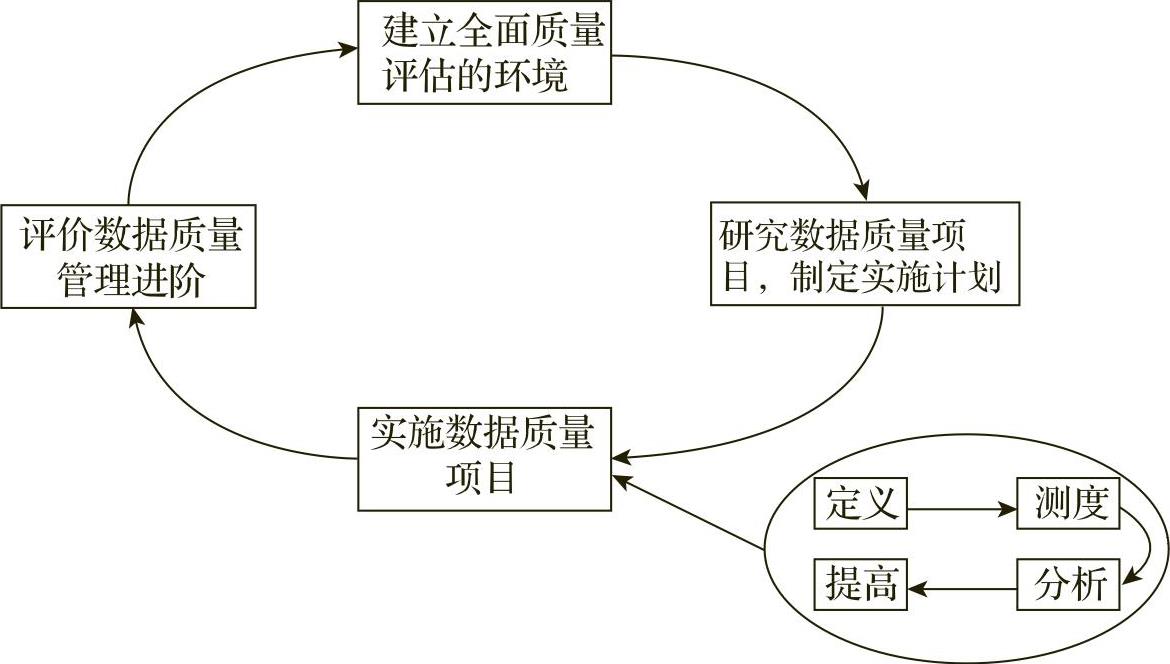
图5-1-2 全面数据质量管理进程图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




