我们已经知道ETL是将业务系统的数据经过抽取、清洗、转换之后加载到数据仓库的过程,通常情况下,商业智能项目的ETL部分会占整个项目的1/3以上,ETL的设计会直接决定商业智能项目的成败。下面详细介绍ETL中的抽取、清洗、转换、加载等各个部分的内容。
1.数据抽取
数据抽取就是从源系统中获取业务数据的过程。数据的抽取需要充分满足商业智能系统的决策分析需要,为了保证不影响系统的性能,数据抽取时需要考虑很多因素,包括抽取方式、抽取时间和抽取周期等内容。
例如,抽取方式包括增量抽取、全量抽取。抽取时间应该尽量在系统使用的低谷时段,如夜间。抽取的周期是根据业务的需求制定的,如按小时抽取,或者按天、月、季度、年等抽取。在数据抽取之前,需要确定业务系统的数据情况,了解数据量的大小,以及业务系统中每张表的数据结构、字段含义、表之间的关系等信息,当收集完这些信息后,才能进行数据抽取的设计开发等工作。数据抽取有下面几种情况:
1)如果业务操作型数据库和数据仓库之间的数据库管理系统完全相同,那么只需要建立相应的连接关系就可以使用ETL工具直接访问,或者调用相应的SQL语句或者存储过程。
2)如果数据仓库系统和业务操作型数据库的数据库管理系统不相同,那么比较简单的方式是使用ETL工具导出成文本文件或者Excel文件,然后再进行统一的数据抽取。
3)如果需要抽取的数据量非常庞大,此时就必须考虑增量抽取。通常用标记位或者时间戳的形式,每次抽取前首先判断是否是抽取标记位或者是当前最近的时间,然后再将数据源的数据抽取出来。
2.数据清洗
在一般情况下,数据清洗的目的就是选择出有缺陷的数据,然后再将它们正确化和规范化,从而达到用户要求的数据质量标准。其中数据“缺陷”可能包括以下几种情况:数值重复、数据缺失、数据错误、数据范围混淆、存在“脏”数据和数据不一致等几种情况,如图7-43所示。其中数值重复是指标准不唯一,很多数值都代表着相同的含义。数据范围混淆是指相同的数值会应用到不同的场合中,代表着不同的含义。
第一步,需要跟业务部门进行沟通交流。为了提高数据的质量,得到标准的数据,应该首先过滤掉不符合业务要求的数据,这些数据都违背业务规则,数据清洗过程会根据业务规则去修正这些数据,每个业务规则都规定了数据必须满足的条件,然后通过ETL程序去修正这些不符合业务规则的数据。
第二步,为了确保用于决策分析的数据质量,需要跟用户积极沟通,将缺失的数据补全,最后才能过滤到数据仓库中。而那些错误的数据,应该等用户完全修正后再抽取。重复的数据,同样应该等用户确认完毕后再进行抽取。我们应该理解数据清洗是一个非常费时、复杂的工程,需要多个业务部门的配合和技术开发人员对业务数据的理解,通过不断修正问题和解决问题才能完成。
数据清洗的流程包括以下几个方面,如图7-44所示。
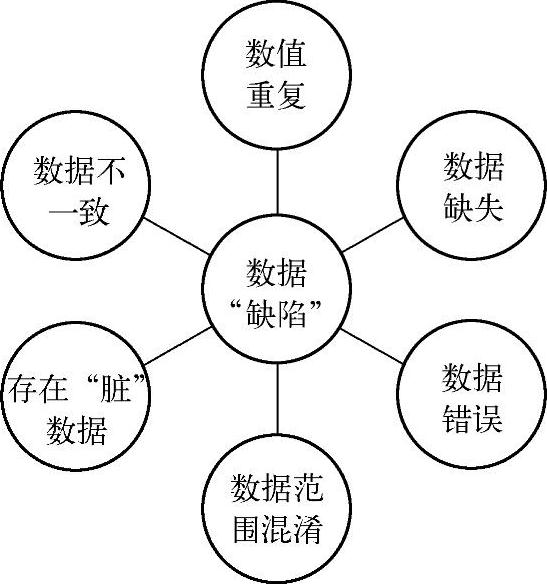
图7-43 数据“缺陷”图
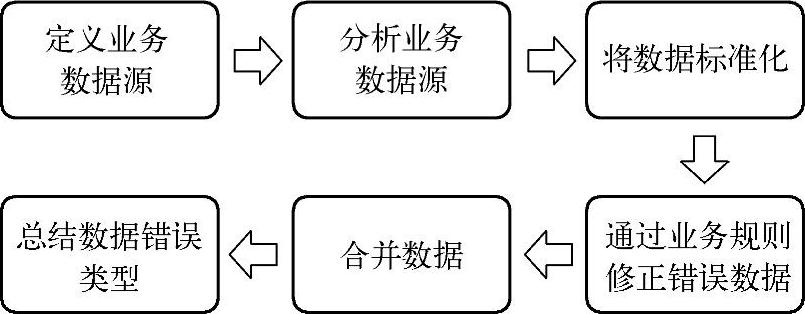
图7-44 数据清洗的流程图
(1)定义业务数据源
标识出满足需求的数据源,并且决定什么时候进行数据清洗。
(2)分析业务数据源
分析数据源的数据是否符合业务的规则和定义,是否存在非正常的数据结构。
(3)将数据标准化
定义标准化格式的数据,并且加以转换。
(4)通过业务规则修正错误数据
定义是否为正确数据的标准,确定如何处理错误数据的方法。
(5)合并数据
将属于同一实体的多个数据进行合并,合并时应该有去重的功能。
(6)总结数据错误类型(www.daowen.com)
通过总结数据出错的类型,提高清洗程序的完整性和正确性,从而降低数据出现重大问题的可能性。
3.数据转换
数据转换是指从业务系统中抽取出源数据,然后根据数据仓库模型的需求,进行一系列数据转换的过程。
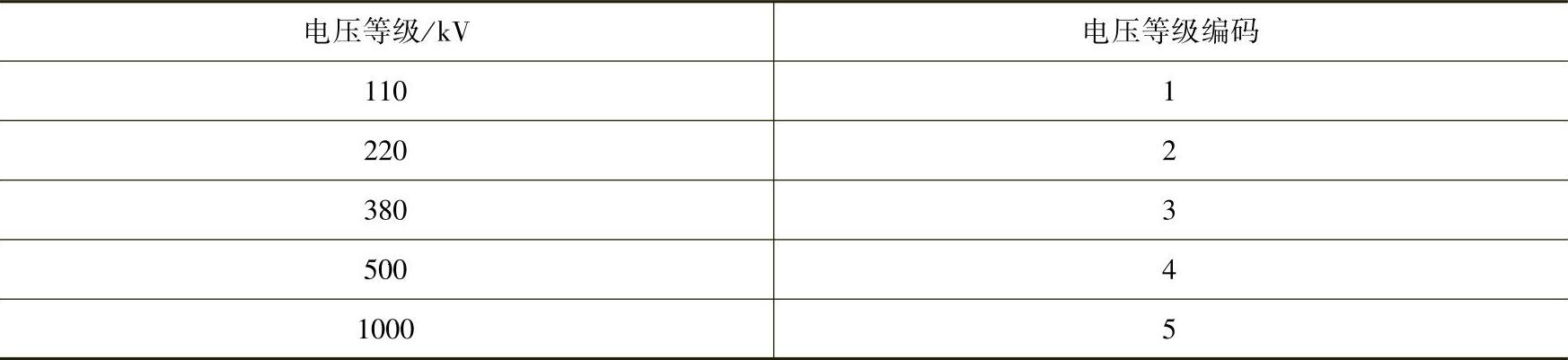
我们已经知道数据转换是整个ETL过程中复杂程度相对较高的过程,包括对数据不一致性的转换,业务指标的计算和某些数据的汇总,为决策分析系统提供数据支持。其中对数据不一致性的转换就是依赖于编码表的设计,通过电压等级编码表(见表7-3)将不同业务系统中相同类型的数据进行转换,即将各个省市的电力营销系统的电压等级编码标准化,例如将110 kV的编码统一设置成1,220 kV的编码设置成2,380 kV的编码设置成3,500 kV的编码设置成4,1000 kV的编码设置成5,以消除数据仓库系统中数据存在不一致的可能。
表7-3 电压等级编码表
通过建立程序代码编写规范,与模型设计小组共同制定编码规则,不仅可以提高数据模型的可靠性、可读性、可修改性、可维护性和一致性,而且还会提高数据模型的可继承性,促使每个人的成果可以互相共享。同时也应该建立公共的编码表作为数据转换的依据,可以根据编码表制定的业务规则进行数据的转换,保证数据仓库系统内部数据的一致性。例如,性别在客户关系表中用1和0分别代表男和女,而在单位员工表中可能使用m和f区分男和女,需要对不同业务表中相同类型的业务含义进行统一和规范。
在转换过程中,对粒度的分析也是工作的重要组成部分,因为存放到数据仓库中的数据对粒度的要求可能不相同,用户需要将低粒度的数据汇总形成决策分析型的数据,同时完成各种数据指标的计算,这都需要经过ETL转换过程。最后一步,将转换后得到的数据加载到数据仓库中,以供企业高层领导决策分析时使用。
ETL转换过程可能包括以下几个方面,如图7-45所示。
1)对空值的处理:如果在转换过程中捕获到某些字段存在空值,那么在进行加载时需要将空值替换成某一数据或者直接进行加载,不做任何转换。
2)对数据格式的规范化:根据业务数据源中各个字段的数据类型,进行数据格式的规范和统一。例如,统一将数值类型转化成字符串类型。
3)根据业务需求进行字段的拆分或者合并。
4)对缺失数据的替换:根据业务需求对缺失数据进行替换。
5)根据业务规则对数据进行过滤。
6)根据编码表进行数据唯一性的转换:根据编码表制定的业务规范进行数据的转换,实现数据仓库系统内部数据的一致性。
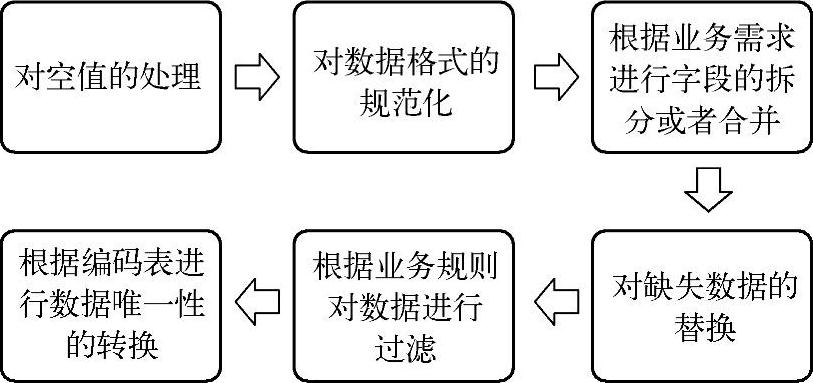
图7-45 ETL的转换过程
4.数据加载
数据的加载过程就是将已经转换完成的数据存放到目标数据库的过程。这是ETL过程中的最后一步,需要保证加载工具必须具有高效的性能去完成数据加载,同时还需要考虑数据加载的周期和策略。数据加载策略包括时间戳的加载方式、全表对比的加载方式、通过读取日志表进行加载的方式、全表删除后再进行加载的方式,如图7-46所示。

图7-46 数据加载策略
时间戳的加载方式是通过对源系统的表添加时间戳字段,将系统当前时间和时间戳的值进行对比,决定哪些业务数据需要被抽取,可以实现数据的递增加载,是比较常见的一种加载方式。
全表对比的加载方式是在数据加载前,将每条数据都与目标表的所有记录进行全表对比,根据主键值是否相同,判断数据是更新还是插入。当数据量比较大的时候,有耗时长、效率低的缺点。通常也对全表对比进行改进,采用版本号、标记字段等缓慢变化维的形式进行增量的抽取。
通过读取日志表进行加载的方式是当源数据表发生变化时,不断更新日志表的信息,将日志表的信息作为数据加载的一个依据。日志表维护相对麻烦,会存在一定风险。
全表删除后再进行加载的方式是在数据加载前,先删除目标表的所有数据,然后去加载全部的数据,但是不能实现数据的递增加载,效率较低,实现方式却相对简单。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。



