分析前一章的数据架构规划图,其中在数据临时区中有非结构化数据一项,如图5-7所示。
如何处理非结构化数据呢?如图5-8所示。
首先可以使用“网络爬虫”手段收集非结构化的数据,在Hadoop平台中建立非结构化信息的标签、摘要、索引、日志、内容等,然后提取结构化的元数据信息,如类别、摘要等内容,最后与基础数据中的结构化数据进行整合。
对于流数据来说,它强调的是实时处理与分析,而不是数据存储,所以只在内存中进行处理,不落在具体的磁盘中。随着时间的流动,它只对一段时间内的数据进行处理。例如,它把银行交易系统的日志信息实时地放到流平台当中,进行反欺诈的实时监测,流计算一般可以在几秒钟之内对海量数据中的异常行为进行预测和分析。
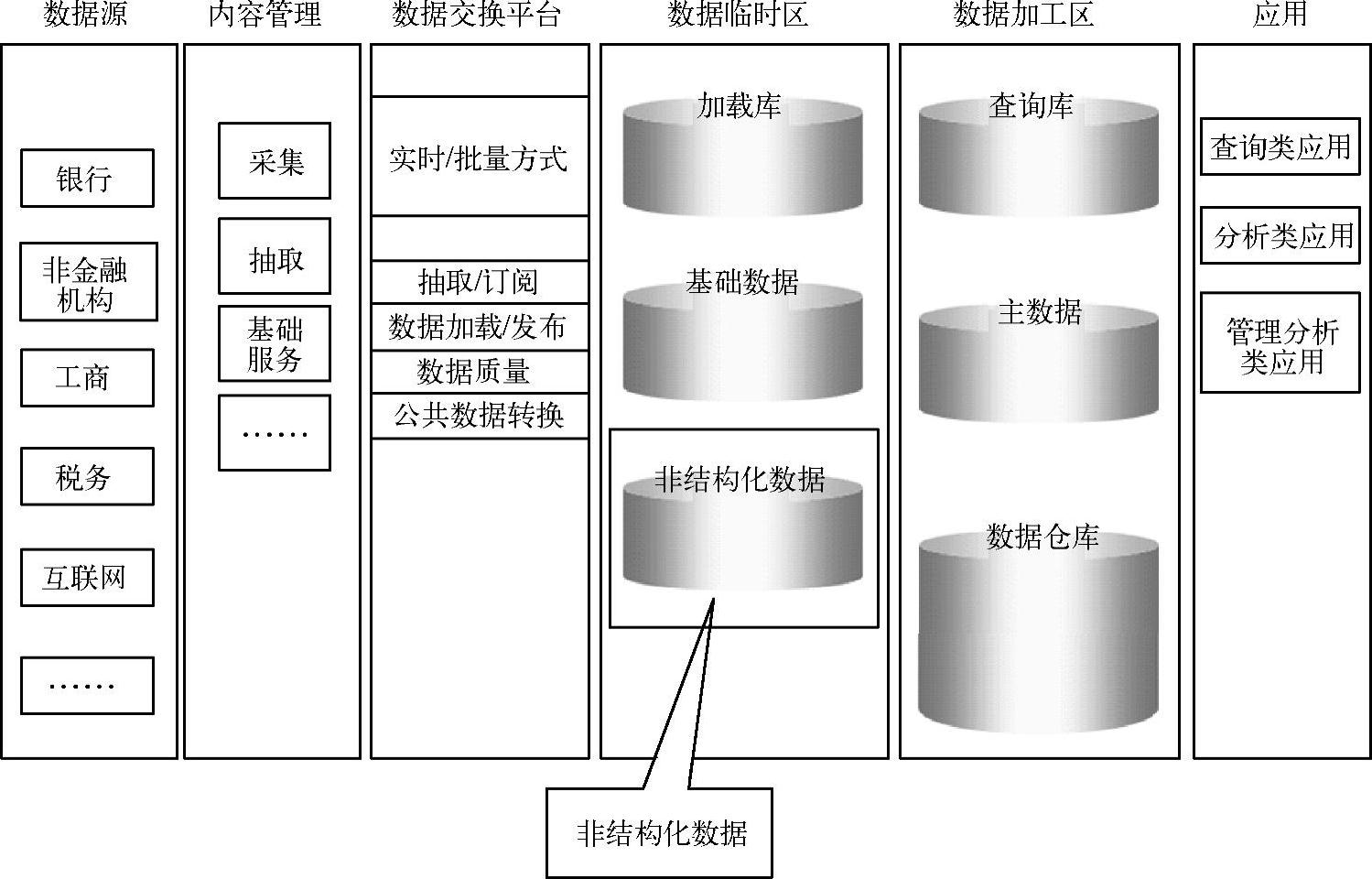
图5-7 数据架构规划图
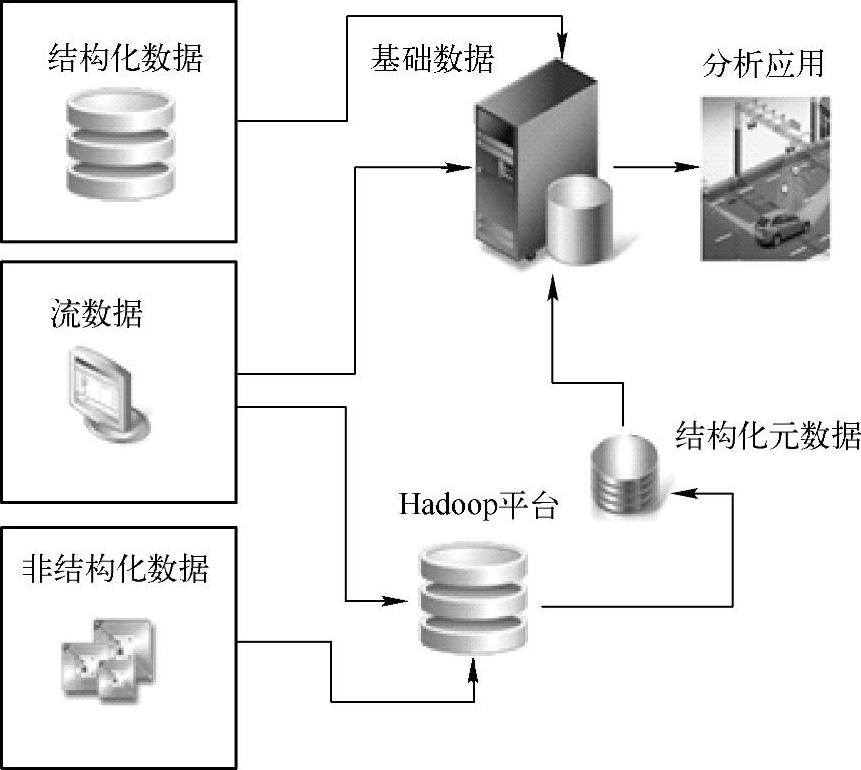
图5-8 非结构化数据的处理流程
总之,对于基础数据来说,它存储的都是有用的信息,类似于存储的都是“黄金”。Hadoop平台存储的是从网络中收集来的沙子,我们的目的就是将沙子里的黄金筛选出来。非结构化数据通过网络爬虫等手段把数据放入到Hadoop平台中,再转化成结构化数据进行分析。
大数据的一个重要应用就是舆情分析,利用网上收集的信息,如正而、负面的信息,分析人们的情感和进行预警分析。舆情分析包括企业的声誉分析、品牌分析、服务质量分析、竞争产品分析、市场动态跟踪等内容。
随着业务的扩展,用户应该对大数据进行数据架构规划,如图5-9所示。
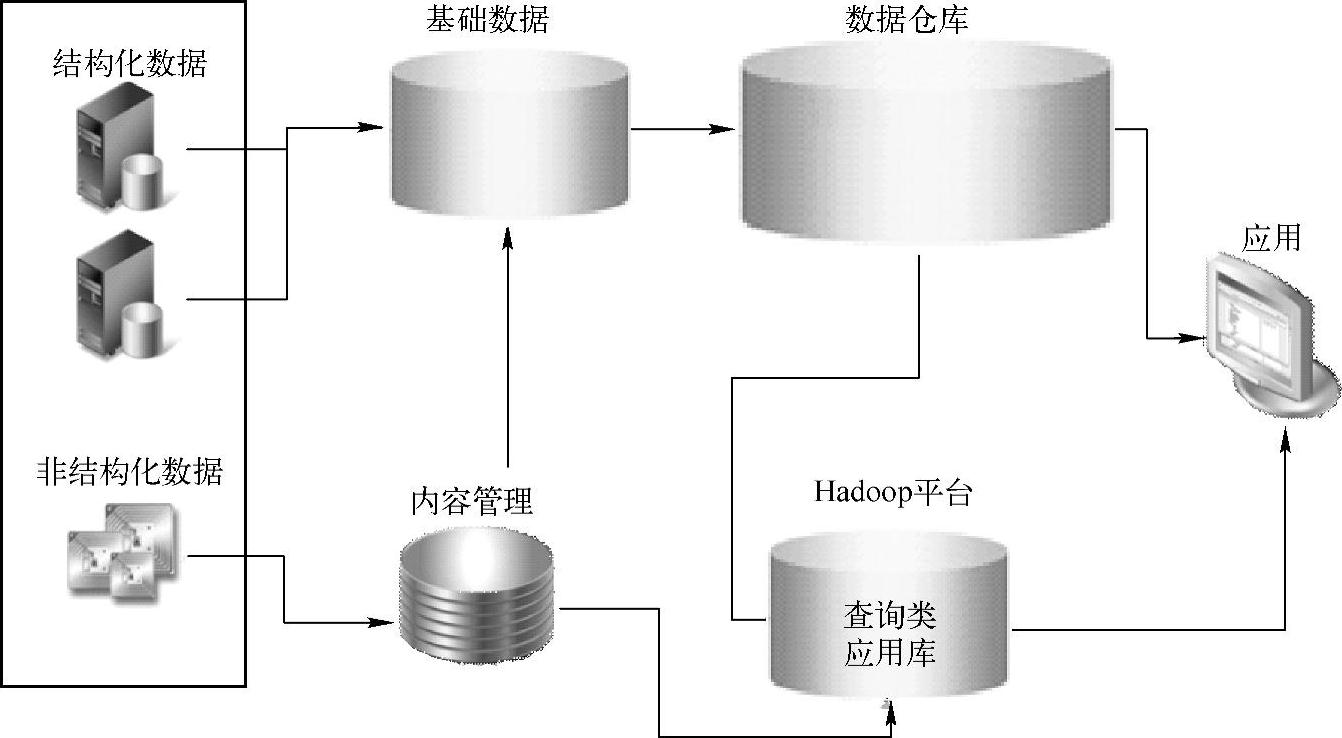
图5-9 大数据的数据架构规划
大数据的数据架构规划可以采用Hadoop技术,通过与结构化数据的关联,进一步拓展对非结构化数据的处理,其中数据源包括结构化数据、半结构化数据、非结构化数据,特别是非结构化数据和半结构化数据通过网络爬虫的方式收集信息,经过内容管理平台的处理,将非结构化数据、半结构化数据结构化处理,其中可以将内容管理平台处理得出的非结构化数据的元数据信息存放到基础数据存储中。
对于Hadoop平台来说,它是基于HDFS或Hbase存放非结构化/半结构化数据。对于应用来说,它是基于结构化数据、半结构化数据、非结构化数据进行综合分析。
对于我们熟知的流数据,具有哪些特性呢?如图5-10所示。
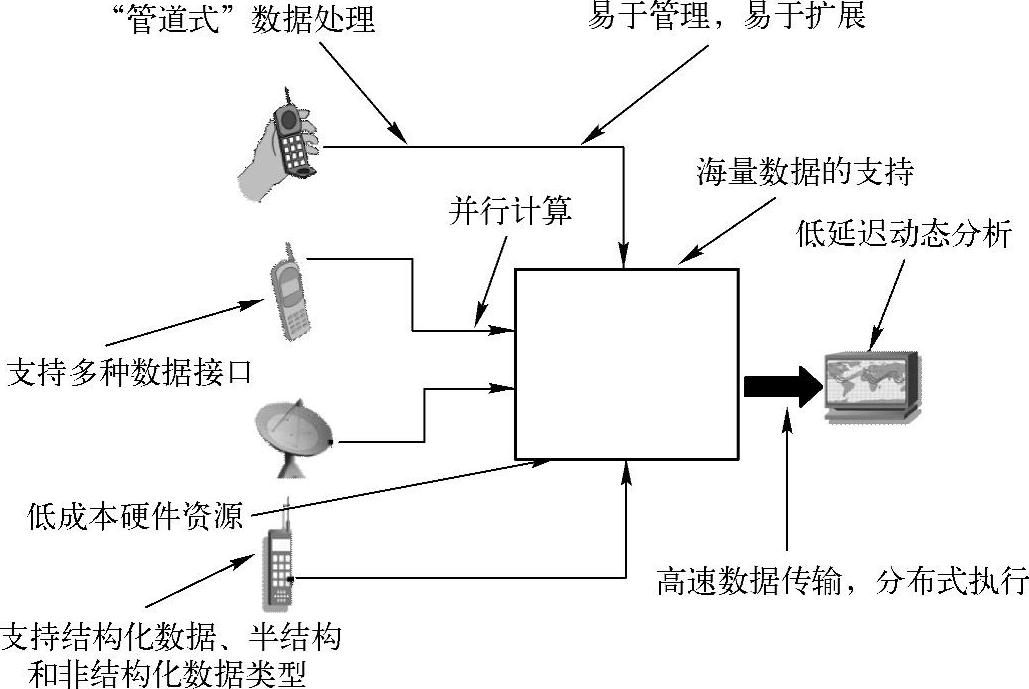
图5-10 流数据特性(www.daowen.com)
流数据具有“管道式”的数据处理方式,易于管理、易于扩展,支持并行计算和多种数据接口,以及各种低成本硬件资源。同时支持结构化数据、半结构化数据和非结构化数据类型,也支持高速数据传输和低延迟动态分析等。
流分析的主要过程如图5-11所示。
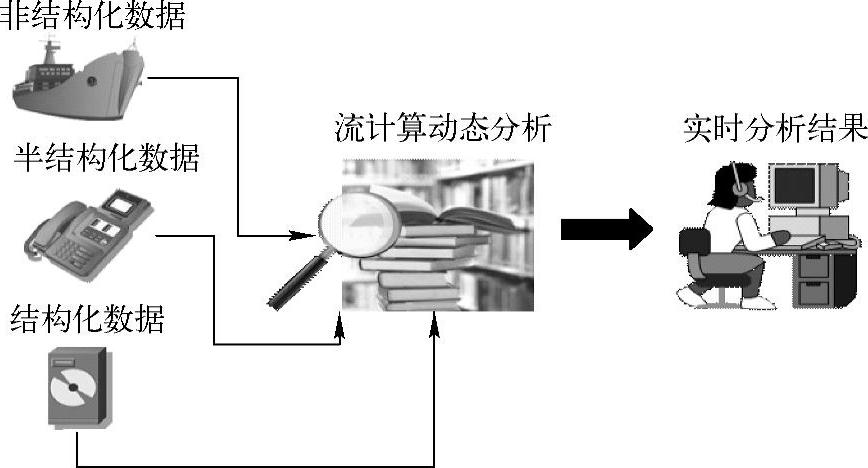
图5-11 流分析的主要过程
流数据有哪些作用?
流数据可以保障数据处理的实时性,提高数据分析和决策的实时性,同时实现数据挖掘、分析和展现的有效融合,降低延迟性。
大数据的处理流程
大数据的处理流程主要包括大数据的采集、对数据的统计分析和对数据的挖掘等三个阶段。
(1)大数据的采集
通过数据库接收来自客户端的数据,同时进行查询和处理。例如,Oracle、MySQL、HBase和MongoDB等,这些产品有各自的特点。
(2)对数据的统计分析
对于繁杂、粗糙的、庞大的数据来说,一旦经过提炼和加工,便可能带来巨大的经济效益。可以利用分布式技术对海量数据进行查询和汇总。特点是查询的数据量大,查询的请求多。包含的产品包括Hadoop、Oracle Exadata,可以做离线分析和实时分析。
(3)对数据的挖掘
对查询的数据进行挖掘分析,满足高级的数据分析,但涉及的算法复杂,数据量巨大。
银行每天都在处理千万量级的交易,它记录了我们每一笔的收入和支出情况,包括资金的汇入和汇出情况。在未来,数据将以40%的速度快速增长,大数据为银行带来的价值是不可估量的。
商业银行可以分析客户使用网银的习惯,将最常用的功能展示在登录界面上,省去了用户在菜单中跳转所花费的时间。同样,我们也可以基于对数据的采集和识别,评估信用卡申请人提交的信息和证明材料,包括其他信用卡发行商提供的申请人交易信息和还款信息。一些营销专家和数据分析专家可以借助数据挖掘工具,对用户的信息进行提炼和分析,然后基于对海量数据的挖掘,进行风险控制和用户营销。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





