下面将从数据分类的角度,分析数据在未来数据架构各个逻辑库上的分布及流转。
对于逻辑库的设计原则,可以包含以下几个方面,如图3-22所示。

图3-22 逻辑库的设计原则
(1)数据的共享性
减少数据复制并降低数据的冗余度,提高数据的共享性。
(2)数据的管理性
考虑系统对于数据管理方面的要求,特别是数据质量的管理。
(3)数据的高性能
基于性能的考虑,可以将加工和查询分开。
(4)数据的可用性
确保系统对外服务的时间窗口尽可能延长,减少停机的时间。
对于数据架构的分布和流转,需要先了解逻辑库包含哪些内容,如图3-23所示。
●ODS
主要存储贴数据源的最近一期的数据。
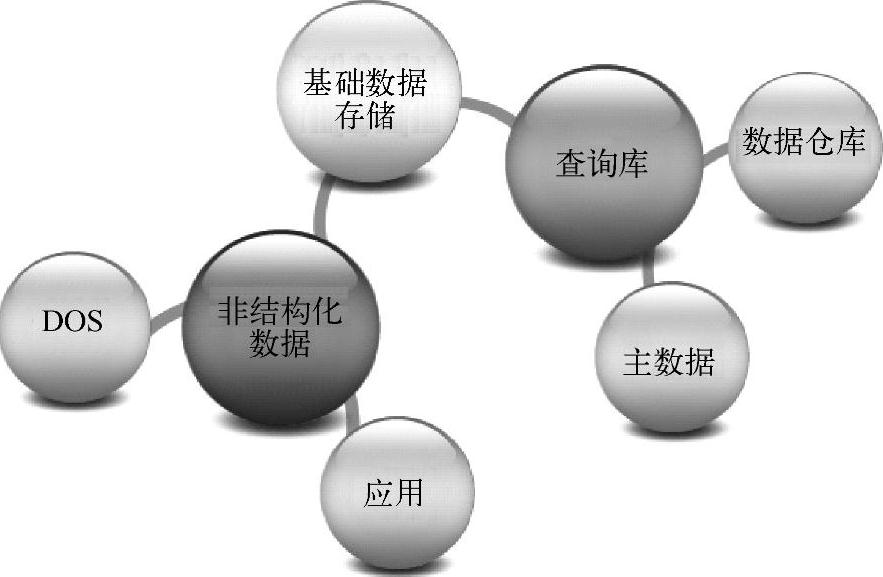
图3-23 逻辑库相关内容
●基础数据存储
主要存储校验过的明细的基础数据,存储的期限根据业务需求制定。
●非结构化数据
主要存储互联网或者其他渠道获得的经过处理的非结构化数据。
●查询库
主要进行数据加工或者产品加工,保存过程数据。
●数据仓库
主要保存基础的历史数据,或者主数据、产品的信息,供后续加工和使用。
●主数据
主要存储核心业务实体和实体之间关系的数据,如唯一身份识别信息。(www.daowen.com)
●应用
存储复制的数据并提供对外服务。
一、数据架构的分布
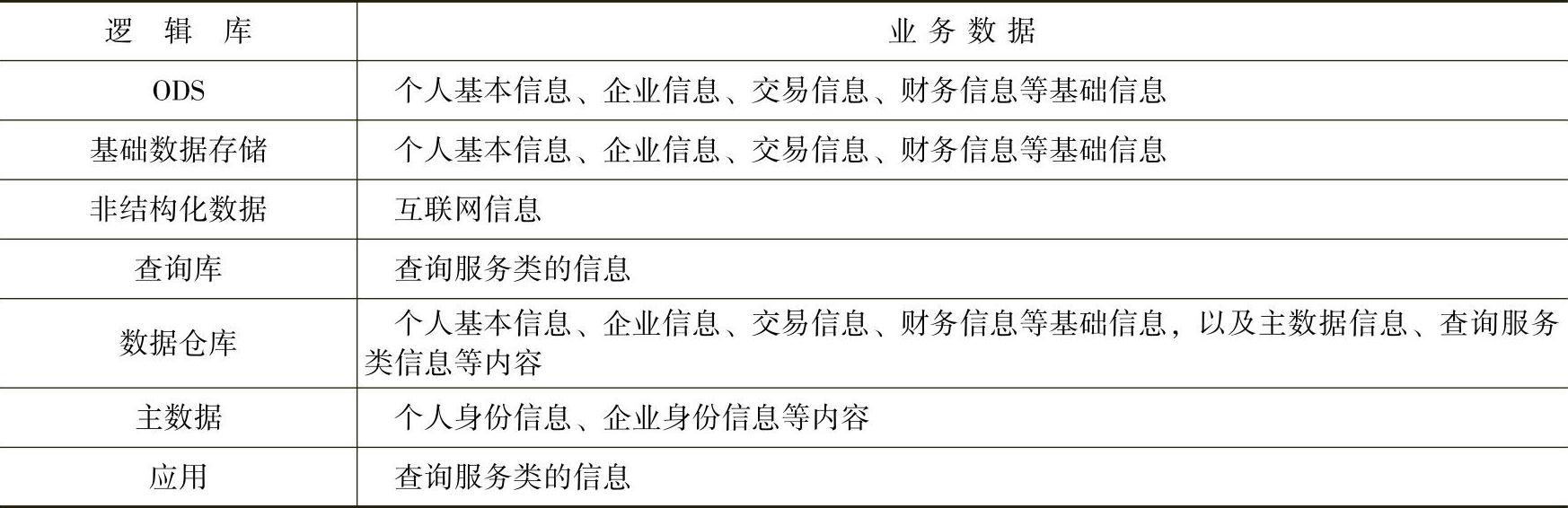
数据分布主要分析业务数据在多个系统之间和多个环节之间的分布情况。下面主要分析业务数据在各个逻辑库之间的分布状况,举例见表3-2。
表3-2 业务数据在各个逻辑库之间的分布状况
二、数据架构的流转规划
数据流转是描述业务分类在各个逻辑库之间的流转情况,如图3-24所示。
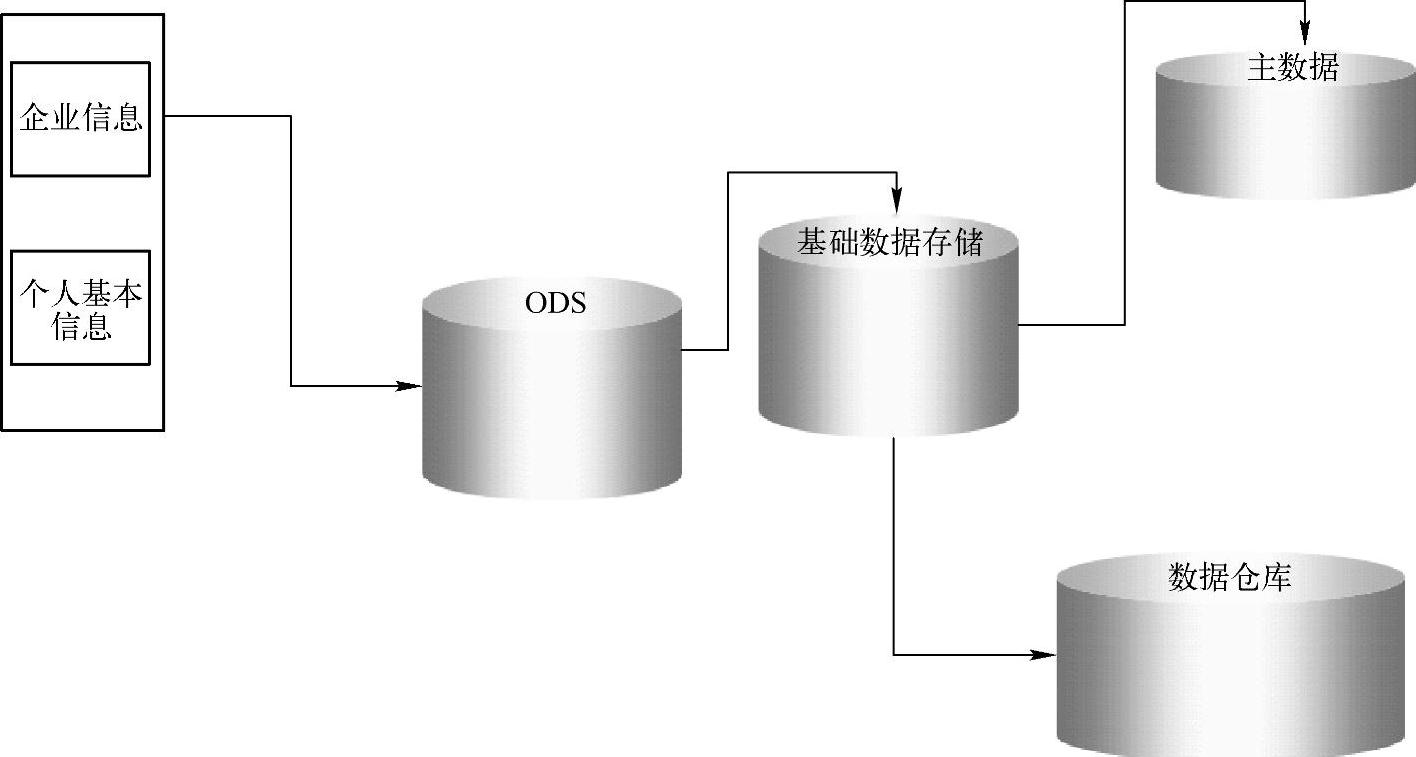
图3-24 数据流转
首先,企业信息和个人基本信息在ODS中临时存储并且进行校验,当校验通过后存放到基础数据存储中,然后,将这些信息加载到主数据中进行企业身份信息整合和个人身份信息整合,最后,将个人基本信息和企业信息加载到数据仓库中。
合理的数据分布和流转可以提高数据的一致性,减少数据冗余,从而提高数据的灵活性和可扩展性。
首先,核心的数据尽量不要反复地分布在不同的数据库中,这样可以降低数据不一致性的风险,但是有时候基于系统性能的考虑,有些合理的冗余是可以存在的。
其次,在数据分布中需要建设一个唯一可信的数据源,这样保证在后续的加工过程中有依据可查,同时提高了数据的一致性。
再次,尽量缩短数据加工链条。例如,身份信息在主数据中加工,然后对应用和数据仓库供数,基础数据存储为数据仓库、主数据和查询库提供增量数据,这几条链路单独加工,并行处理,提高了效率。
三、数据归档
数据归档是指定期将基础数据存储、应用的数据进行归档保存,它的目的是为了保存原始数据。原则上数据归档对中间数据或者临时数据不进行归档操作。
数据归档可以帮助数据再次核对和备查。数据归档包括在线存储、近线存储和离线存储,如图3-25所示。
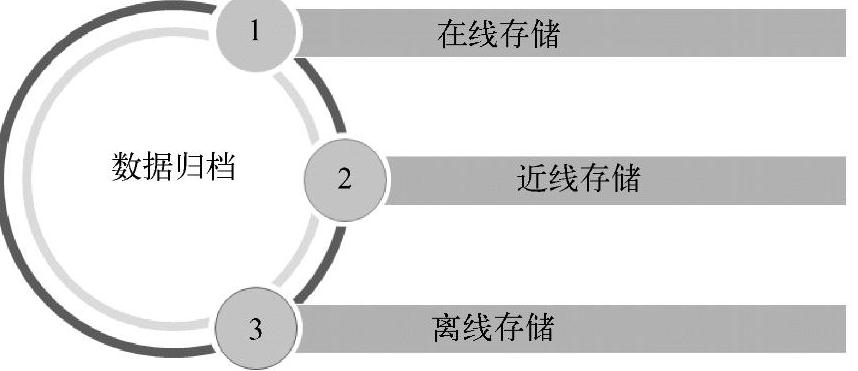
图3-25 数据归档
(1)在线存储
在线存储主要保存近期业务数据,对在线存储的访问频率相对较高。可以使用高速磁盘对数据进行保存。
(2)近线存储
近线存储主要保存访问频率相对较低的数据,一般使用低速磁盘进行存储。
(3)离线存储
离线存储主要保存数据访问频率低,很少存在加工需求的数据,可以使用光盘,磁带等价格低廉的介质保存。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






