1.迭代局部搜索算法
带容量限制和时间窗的团队定向问题的迭代局部搜索算法原理:在每次的迭代中,通过插入操作构造局部最优解,当达到局部最优解时,对其做适当的扰动,以跳出局部最优,进行下一次的迭代,经过一定的迭代次数达到优化的目的。插入操作中的启发式规则为收益/时间大者优先插入。
(1)迭代局部搜索算法的插入操作
插入操作就是在路径容量和点的时间窗的限制条件下,按收益/时间大者优先插入的启发式规则将尚未被选择的点不断插入到路径中,达到容量限制为止的过程。对当前路径P上的某个点vi,其时间窗为[ei,li],到达时间为ri,最大服务延迟时间为Maxshifti,设vj是vi的紧后点,它们之间有这样的关系式
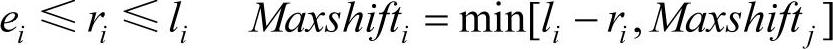
若有尚未被选择的点vx要插入到vi和vj之间,则其插入时所花费的时间
inserttimex=tix+τx+txj-tij
为了不影响点vj的服务时间,则有关系式
inserttimex≤Maxshiftj
inserttimex≤Maxshiftj可以作为点vx能否插入vi和vj之间的一个判断条件。若点vx满足该关系式,且满足自身的时间窗(rx=ri+τi+tix∈(ex,lx))及路径容量限制(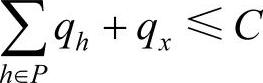 ),则点vx可以插入到vi和vj之间。点vx插入到路径中的不同位置,会有不同的inserttimex。从可行位置中选择点vx的最小inserttimex对应的位置作为点vx在当前路径中的适当位置,此时的inserttimex记为inserttime*x。从尚未被选择的点中选择wx/inserttime*x最大的点vy插入到当前路径中。更新当前路径,即P*=P∪{vy}。同时,点vy的插入改变了原路径上点的部分时间参数。点vy后的所有点的到达时间均向后推迟了inserttime*x,且路径上所有点的最大延迟服务时间也相应改变。假设点vy被插入到了vi和vj之间,点vj的到达时间r*j=rj+inserttime*x,最大服务延迟时间Maxshift*j=min[lj-r*j,Maxshifth](vh是vj的紧后点),vi点的最大服务延迟时间Maxshift*i=min[li-ri,Maxshifty]。
),则点vx可以插入到vi和vj之间。点vx插入到路径中的不同位置,会有不同的inserttimex。从可行位置中选择点vx的最小inserttimex对应的位置作为点vx在当前路径中的适当位置,此时的inserttimex记为inserttime*x。从尚未被选择的点中选择wx/inserttime*x最大的点vy插入到当前路径中。更新当前路径,即P*=P∪{vy}。同时,点vy的插入改变了原路径上点的部分时间参数。点vy后的所有点的到达时间均向后推迟了inserttime*x,且路径上所有点的最大延迟服务时间也相应改变。假设点vy被插入到了vi和vj之间,点vj的到达时间r*j=rj+inserttime*x,最大服务延迟时间Maxshift*j=min[lj-r*j,Maxshifth](vh是vj的紧后点),vi点的最大服务延迟时间Maxshift*i=min[li-ri,Maxshifty]。
按照上述的关系式更新vy点后的其他点的到达时间、最大服务延迟时间、vy点前的其他点的最大服务延迟时间。更新完路径以及路径上点的相关时间参数后继续进行插入操作,一直到所有尚未选择的点都没有可行位置可插入为止。
(2)迭代局部搜索算法的扰动操作
扰动操作前需要确定连续扰动的点数shakepoints和扰动开始的位置shakeplace。动态的shakepoints和shakeplace可以更好地跳出局部最优。本节的迭代局部搜索算法将初始的shakepoints设为1,shakeplace设为2,每迭代完一次,更新shakeplace*=shakeplace+shakepoints,shakepoints*=shakepoints+1。当shakepoints=n/(3m)时,将shakepoints重新设置为1;当shakeplace大于团队路径中点数最少的路径的点数-2时,将shakeplace重新设置为2;当扰动操作到达路径中倒数第二个点时仍未结束,则继续从路径开始的第2个点扰动。
带容量限制和时间窗的团队定向问题的迭代局部搜索算法基本流程如图10-9所示。输入数据包括:点集V={v1,v2,…,vn}(其中v1为路径起点,vn为路径终点),点的需求量向量Q=(q1,q2,…,qn),服务时间向量Γ=(τ1,τ2,…,τn),收益向量W=(w1,w2,…,wn),m为团队成员个数,成员的最大载重C=(c1,c2,…,cm),点的时间窗矩阵
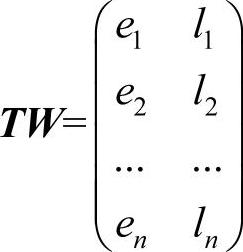
边E的时间矩阵
 (www.daowen.com)
(www.daowen.com)
每个成员的路径Pi等于P0={v1,vn},I为迭代次数,Imax为最大迭代次数。S为当前解(即当前团队获得的总收益),相应的m条路径(即当前团队m个成员的路径)的集合为PP={P1,…,Pm},BS为迭代过程中的最优解,相应的路径集合为BP。迭代Imax次后输出迭代过程中的最优解及相应的路径。
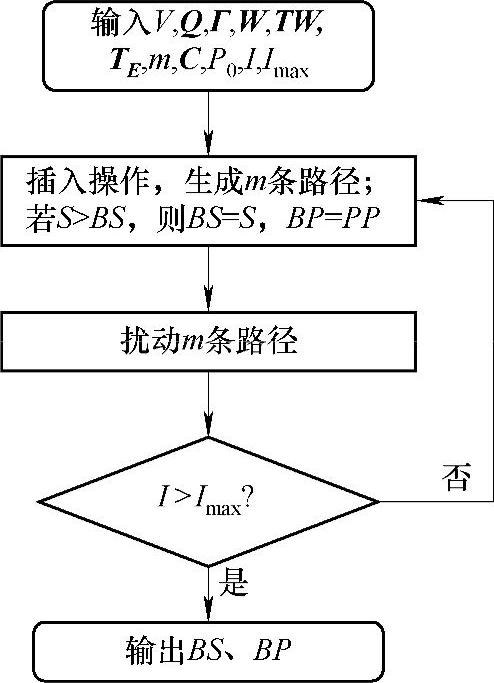
图10-9 迭代局部搜索算法基本流程图
2.遗传算法
带容量限制和时间窗的团队定向问题的遗传算法设计方案如下:
1)采用路径编码,如0→1→5→8→3→0→2→9→4→10→0,它表示团队成员甲从v0出发,依次经过v1、v5、v8、v3,并回到v0,团队成员乙则从v0出发,依次经过v2、v9、v4、v10,最终也回到v0。这种编码方法易于解码。
2)采用随机和启发式相结合的方法生成初始种群,使初始种群既具有多样性又具有较好的优良性。随机生成法首先生成团队成员数目个子路径,然后将它们连接起来形成一个完整个体。子路径的生成过程:从起点开始,按等概率选择当前点时间邻域中尚未被其他成员选择的点作为其紧后点,一直到路径累积需求量即将超过容量限制为止,形成一条子路径,也就是团队某成员的行走路径。将团队各成员的路径连接起来形成一条完整路径,也即得到种群的一个个体。启发式生成法指利用上一小节的迭代局部搜索算法先得到一个较优的解,然后对其进行多次微调,生成多个个体。随机和启发式生成法的比例为4:6,即随机法生成的个体数量占种群规模的40%,启发式法生成的个体数量占种群规模的60%。
3)适应度评价。由于带容量限制和时间窗的团队定向问题约束较多,因此采用目标函数和惩罚函数相结合的函数作为适应度函数,即
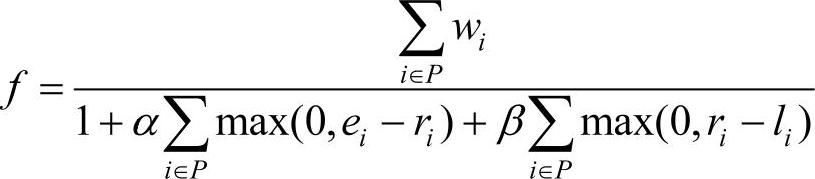
式中,i为基因,即客户;P是染色体;wi是为客户i服务可获得的收益;ei、li分别为客户i的最早、最晚服务时间窗;ri为到达客户i的时间;α、β分别为早到、晚到时的惩罚系数,β是一个很大的正数(可以取所有客户收益之和),如果到达客户的时间晚于客户的最晚服务时间,不仅需要赔偿客户损失,还可能损失客户。
4)选择。最优100%保留,而对其他个体则通过联赛竞争被保留下来,进行下面的交叉和变异操作。
5)交叉。在一条父代染色体上进行重组操作来产生新个体。一般的交叉操作是通过两条父代染色体彼此交换遗传信息产生子代。由于带容量限制和时间窗的团队定向问题有容量和时间窗约束,这种遗传操作在实数编码下会产生大量不可行的个体,因而只在一条父代染色体上进行操作产生新个体,以提高算法的效率。具体操作以染色体(0,1,5,8,3,0,2,9,4,10,0)为例。将该条染色体分成以基因0为首尾的基因片段(0,1,5,8,3,0)、(0,2,9,4,10,0)。分别判断每个基因片段各个基因(区域)所构成的边的大小,选出最大边长max、最小边长min,并计算平均边长ave,按公式
AVE=(max+4ave+min)/6
对这三类边长进行加权平均,所得值作为阈值。破坏边值大于阈值的边,将该边的后端基因从基因片段中删除。假如经过边破坏后,得到的染色体为(0,1,5,3,0,2,9,4,0)。分别对基因片段(0,1,5,3,0)、(0,2,9,4,0)进行插入操作,在基因片段的累积需求量不超过容量限制下,从不属于染色体上的点中,以概率pm选择点随机插入到基因片段中。经过插入操作后,得到新染色体(0,1,10,5,3,0,2,6,9,4,0)。
6)变异。以变异概率pm对交叉产生的染色体进行替代和交换操作。替代操作指在不影响容量限制下,随机从染色体外的其他基因中替代任意染色体中的非0基因。交换操作指在不影响容量限制下,从染色体中随机选择两个非0基因,彼此交换位置。对每一个操作均重复5次,选择(Wnew-Wold)/(Tnew-Told)最小的染色体作为原染色体的变异体。Wold、Wnew分别为插入操作前和插入操作后染色体的适应度值,也即路径的总收益,Told、Tnew分别为插入操作前和插入操作后路径所花费的时间。变异操作一方面增加了种群的多样性,另一方面使部分染色体的适应性更好。
7)控制参数。种群规模为50;进化的代数最大为50;交叉概率pc=0.9-(0.9-0.65)G/Gmax,其中,G、Gmax分别为当前进化代数、最大进化代数,交叉概率随进化代数的增加而减小;变异概率pm=0.001+(0.01-0.001)G/Gmax。动态的交叉和变异概率可以加快收敛速度,同时在一定程度上防止“早熟现象”的发生,提高收敛效果。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





