1.高度规格化的关系数据库模型(Online Transaction Processor,OLTP)
几乎所有的OLTP系统都是使用高度规格化的关系模型设计的,尤其在复杂的系统中更34是如此,如SAP ERP。图2-32显示了有关销售订单的一个非常简单的示例。正如图中描绘的那样,规格化是一个把重复数据从一个表中移到辅助连接表的流程,从而使原始表变得更小。尺寸的缩小,加上只保留最基本的索引模式,便有助于创建、更新和删除记录。为获得这一优势而付出的代价就是分析类型查询性能的降低。
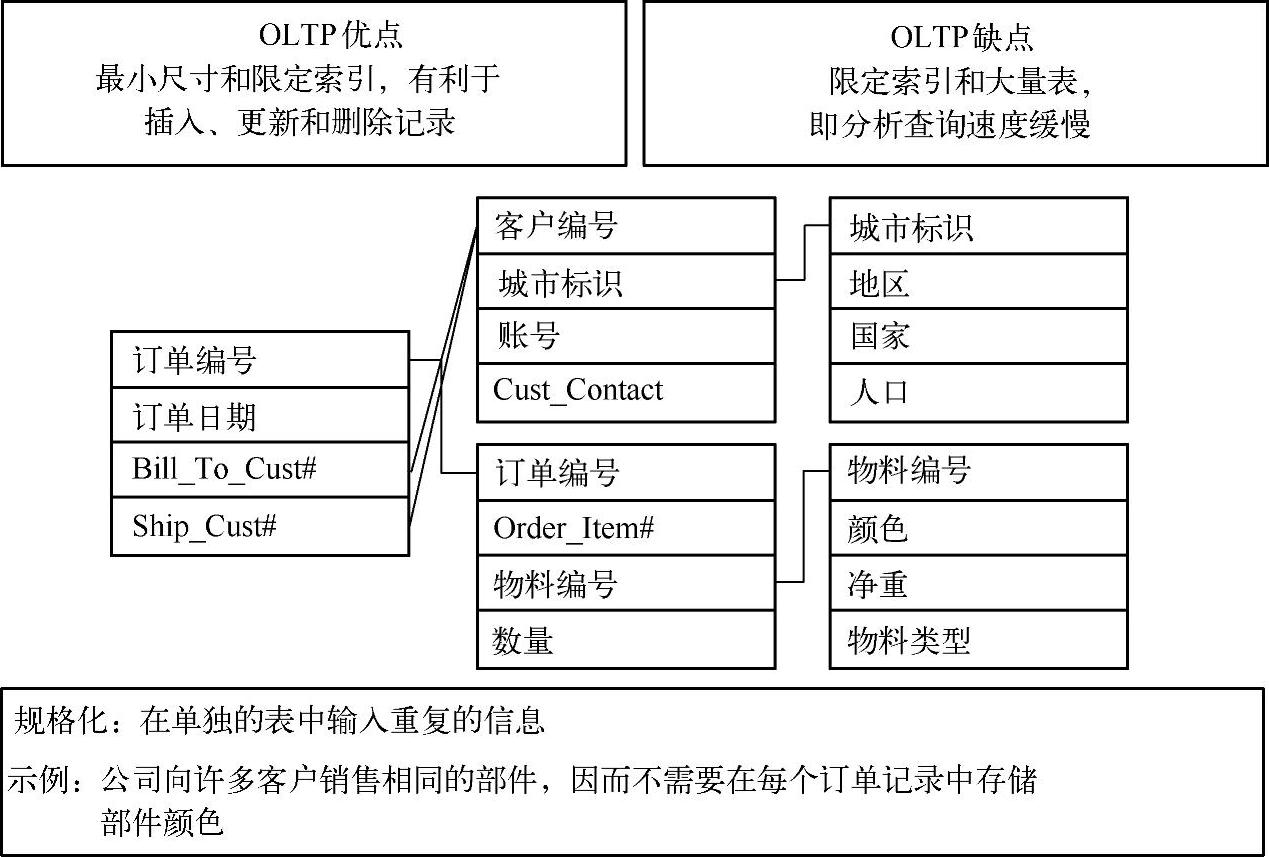
图2-32 OLTP系统的特点概览
2.经典星形模型——EDW数据库模型
为了创建企业数据仓库或OLAP应用程序,换句话说,出于分析应用的目的,需要使用多维数据模型。OLTP规格化设计的问题使其无法被用来支持复杂的特殊数据分析。如图2-33所示,对于关系数据库而言,经典星形模型是使用最频繁的多维模型。这个数据库模型归类出两组数据,即事实(如销售金额或数量)和维度属性(如客户、物料或时间)。事实有时也称为可计量的值,是业务流程分析的重点。事实数据(数据的值)存储在高度规格化的数据表中。从技术角度讲,维度属性的值存储在各种非规格化的维度表中。从业务角度讲,这些表总体称为业务流程维度,简称维度。此处,逻辑相关的维度属性作为层次结构(父项和子项的关系)存储在维度表内。这些维度表借助于键值关系与中心数据表关联式地连接在一起。在显示的星形模型设计中,维度表的键值是机器生成的维度键(DIM ID),它唯一定义了维度属性值的组合。在数据表中,DIM ID(连续分配的编号)是一个外键。这样就可以唯一识别数据表中的所有数据记录,如图2-33所示。
在图2-34中,业务流程变成了与上图的销售数据相对的成本中心交易,并且添加了一些从先前有关特性的课程中获取的详细信息。这样就生成了一张BW星形模型的功能视图。这一设计的好处在于,它适用于该业务的所有方面。
3.维度表
在维度表中,无论语义相关的维度属性有多少,都存储在一个层次结构(父项与子项的关系为1×N)中。在图2-35中,时间维度表由维度属性“会计年度”和“会计期间”构成。如果维度属性之间存在M∶N的关系,则它们通常存储在不同的维度表中。
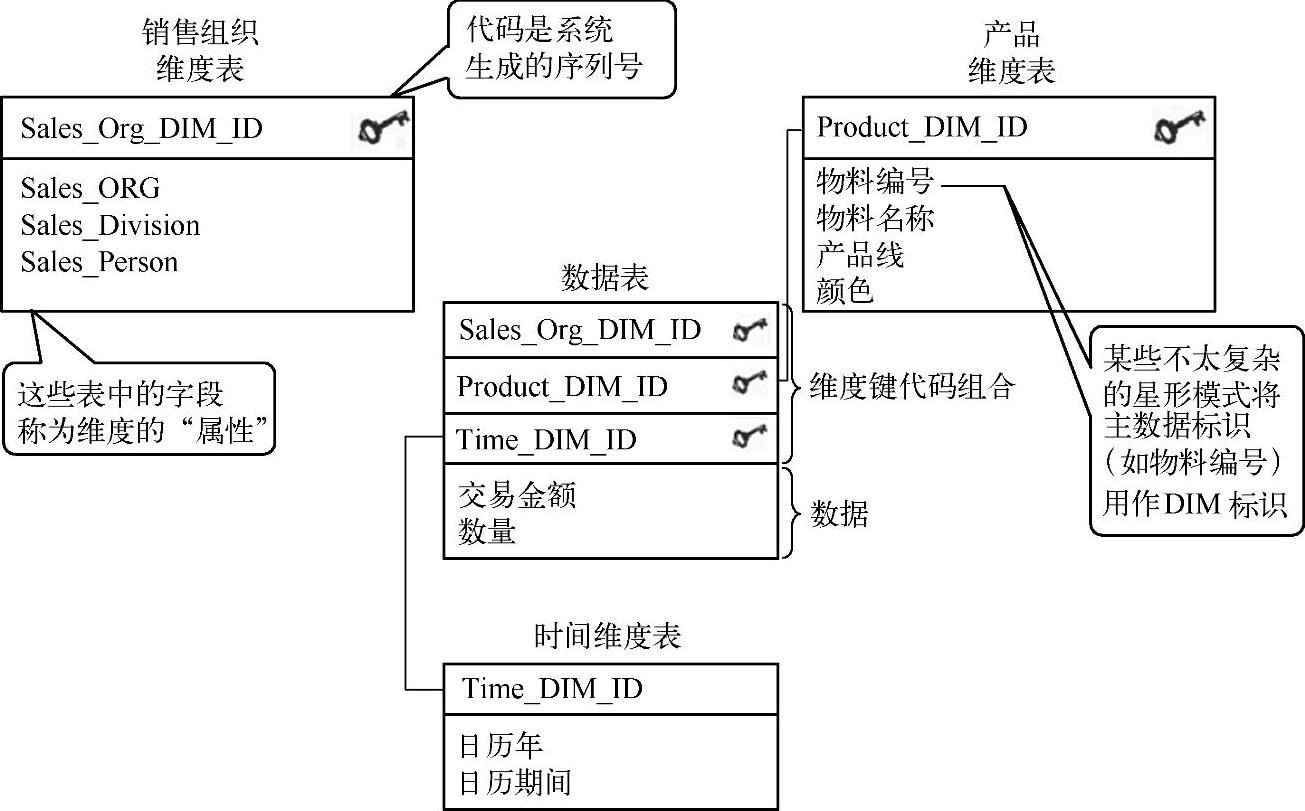
图2-33 经典的星形模型
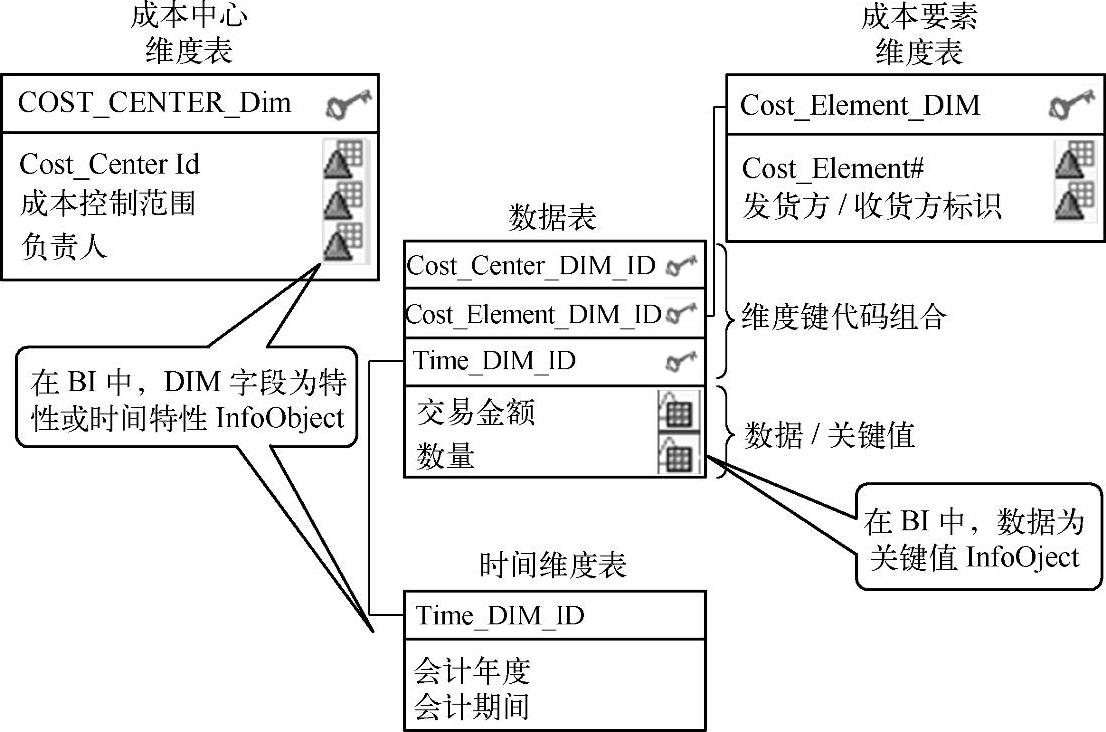
图2-34 经典的星形模型结构举例
与销售信息块有关的另一示例是产品维度,它包含单个产品。在大多数公司中,产品分为产品线和次产品线或类别。例如,产品X是巧克力块,它是食品类别中糖果产品线的组成部分。这只是一个简单的示例,重点是,领域类别、产品线和其他项应该位于维度表中。
在经典星形模型中,维度属性可以拥有任意数量的描述属性,也称作非维度属性,它们可用作补充信息源。描述属性与维度属性之间总是1∶1的关系。在图2-33中,“物料名称”是物料维度表中维度属性“物料”的描述属性。
维度属性/描述属性包含任意数量的值。例如,“硬件”和“软件”会分配到维度属性“物料组”,值“监控器”和“键盘”会分配到描述属性“物料名称”。
从语义上讲,经典星形模型中的维度表通常称为维度。维度定义了用户(决策者)可能的数据查看视角。
每个经典星形模型包含一个或多个维度表。每个维度表包含一个主键,称为维度键。在上述示例中,它是一个机器生成的序列号。在其他更基本的设计中,这个键由具有最高细节层级的维度属性决定。如果我们展示的是一个更基本的销售星形模型,那么产品标识就会是产品维度的键值。这些维度表借助于键关系与中心数据表连接在一起。这些维度表完全是非规格化的,换句话说,与OLTP示例一样,重复的信息未分解到不同的表中。
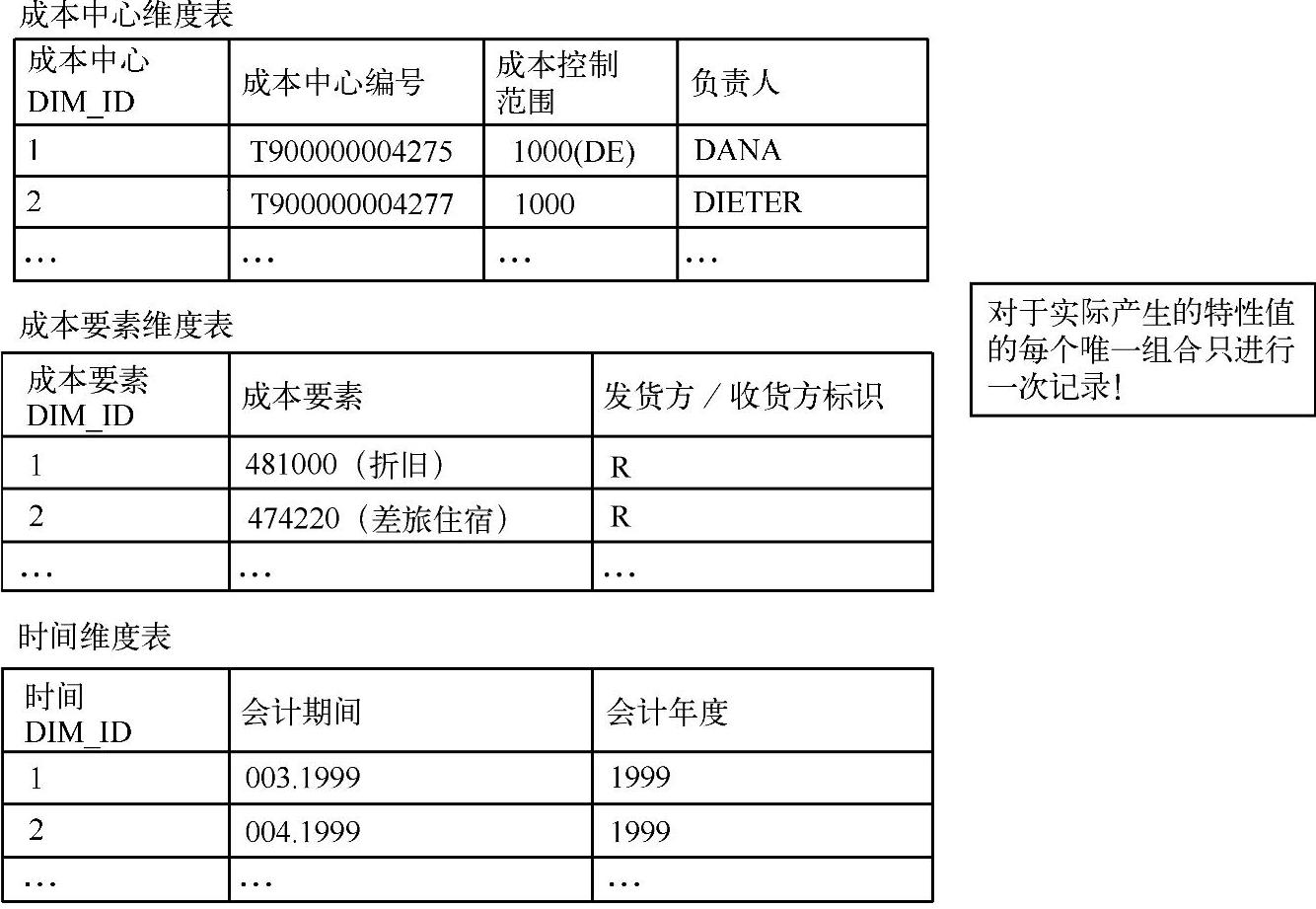
图2-35 经典的星形模型的维度表
4.数据表和完整的星形模型
数据表在星形模型中发挥中心表的作用。计量值或数据(BW术语称其为关键值)通过数据表集合在一起。
1)每个经典星形模型恰好由一个数据表构成。
2)数据表中包含事实数据,包括带有事实数据(50000、3000、100000等)的销售数据和带有事实数据(100、60、250等)的数量。
3)中心数据表通过唯一键与周围的维度表相连。所有维度键(外键)一起构成了数据表的主键。在图2-36中,数据表的主键由维度键COST_CENTER_DIM_ID、COST_ELEMENT_DIM_ID和TIME_DIM_ID构成,其结果是可以唯一识别数据表中的所有数据记录(因此也能唯一识别所有的事实数据)。例如,事实数据(50000/100)可以通过维度键的值的组合(1,1,1)唯一识别。
4)该数据表是高度规格化的。
图2-36显示了维度表和数据表在星形框架中是如何布置的,还展示了非规格化维度表与高度规格化数据表之间的连接。
在经典星形模型中,存储数据会使其得到优化,以用于报表。它允许用户从各种角度(维度)查看数据。用户可能有兴趣找到以下问题的答案:
1)产生的大部分差旅住宿费用由谁负责支付?
2)哪个成本要素(差旅、工资支出或折旧)是我们的最大支出?
3)所有成本中心加起来的总费用是多少?
4)这些成本是什么时候产生的?
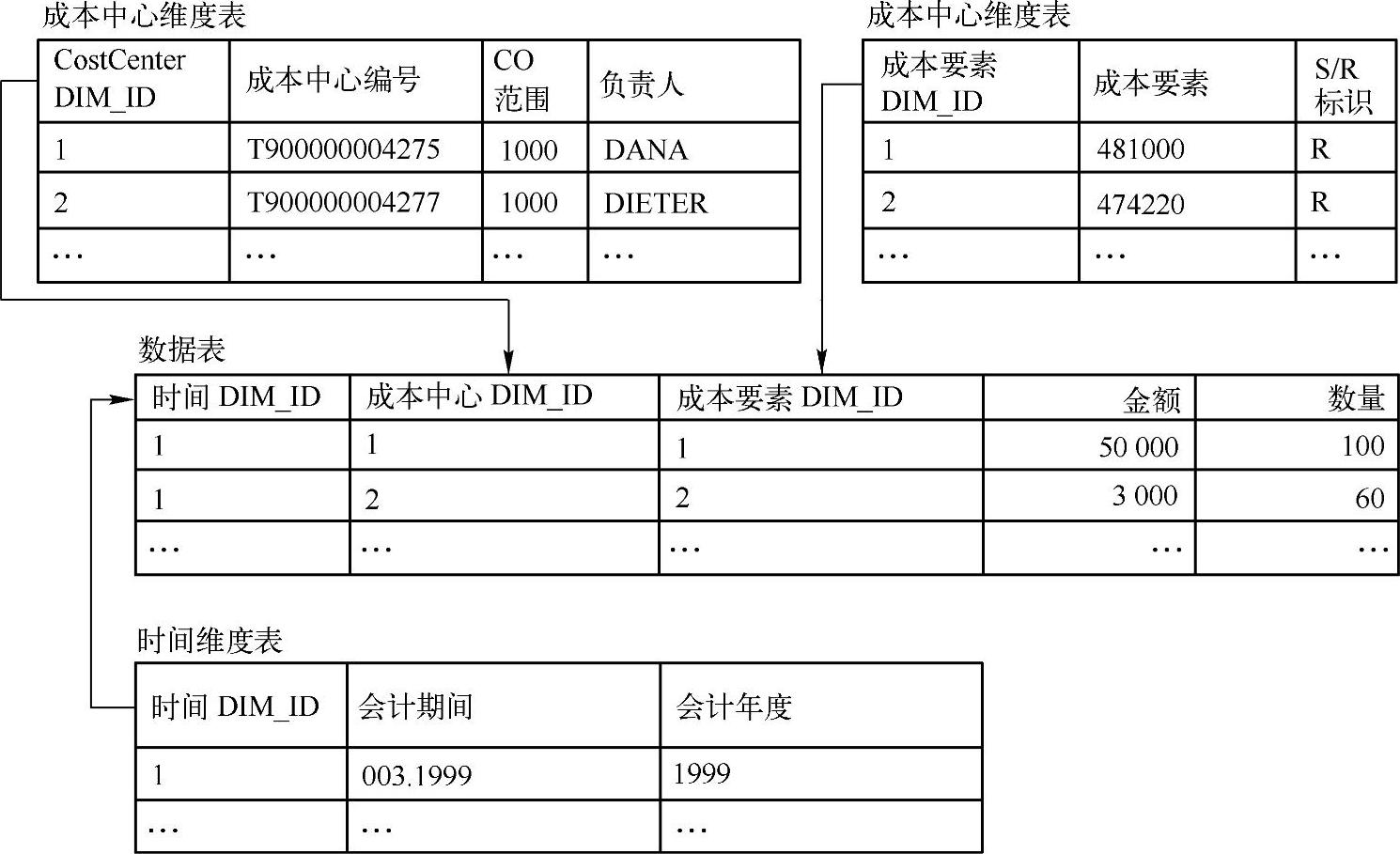
图2-36 经典的星形模型数据关系举例
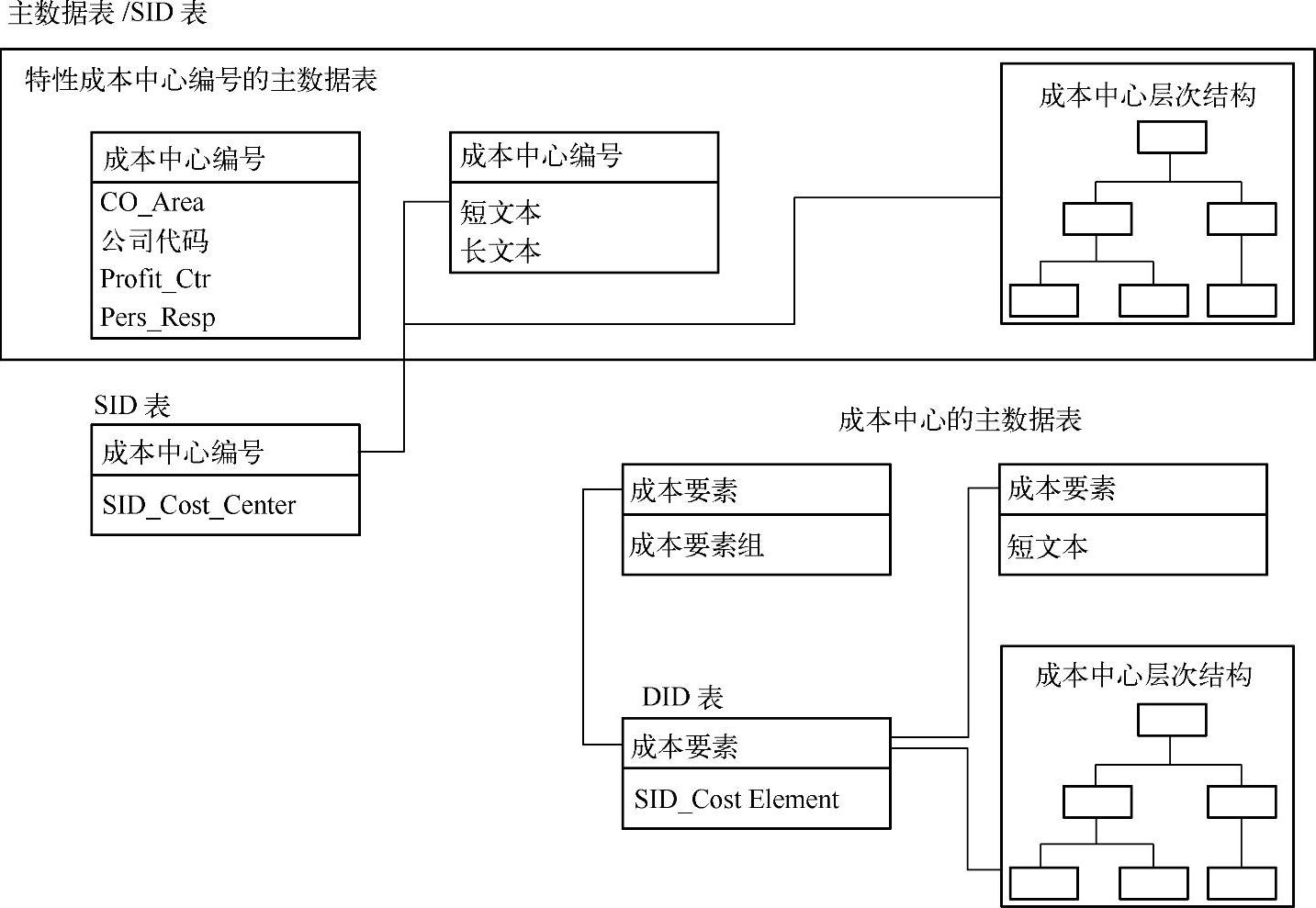
图2-37 扩展的星形模型
说明:在激活信息对象时,会产生一个“S”表,该表用于存储系统生成的SID编号和特性值的对照关系。
5.BW模型——一种扩展的星形模型
尽管图2-36所示的是星形模型的功能定义,但从BW系统的角度讲,它是不完整的。在构建大部分EDW时所基于的完整BW模型是一个大大增强(完善)的星形模型。这些改进消除了经典星形模型经历过的技术和业务报表问题。在深入探讨BW信息块模型之前,需要回顾一下特性对象,其中需要重点关注具有主数据的特性。图2-37显示了BW交付的众多具有主数据的特性中的两个。尽管特性对象在维度表中是属性字段,但是在整体模型设计中,使自己的主数据表与自身相连的特性是十分重要的。(https://www.daowen.com)
图2-38使用成本中心交易作为示例,展示了经典星形模型与BW星形模型之间的交叉关系。特别注意,信息块的维度中所使用的具有主数据的特性是如何与它的主数据相连接的。
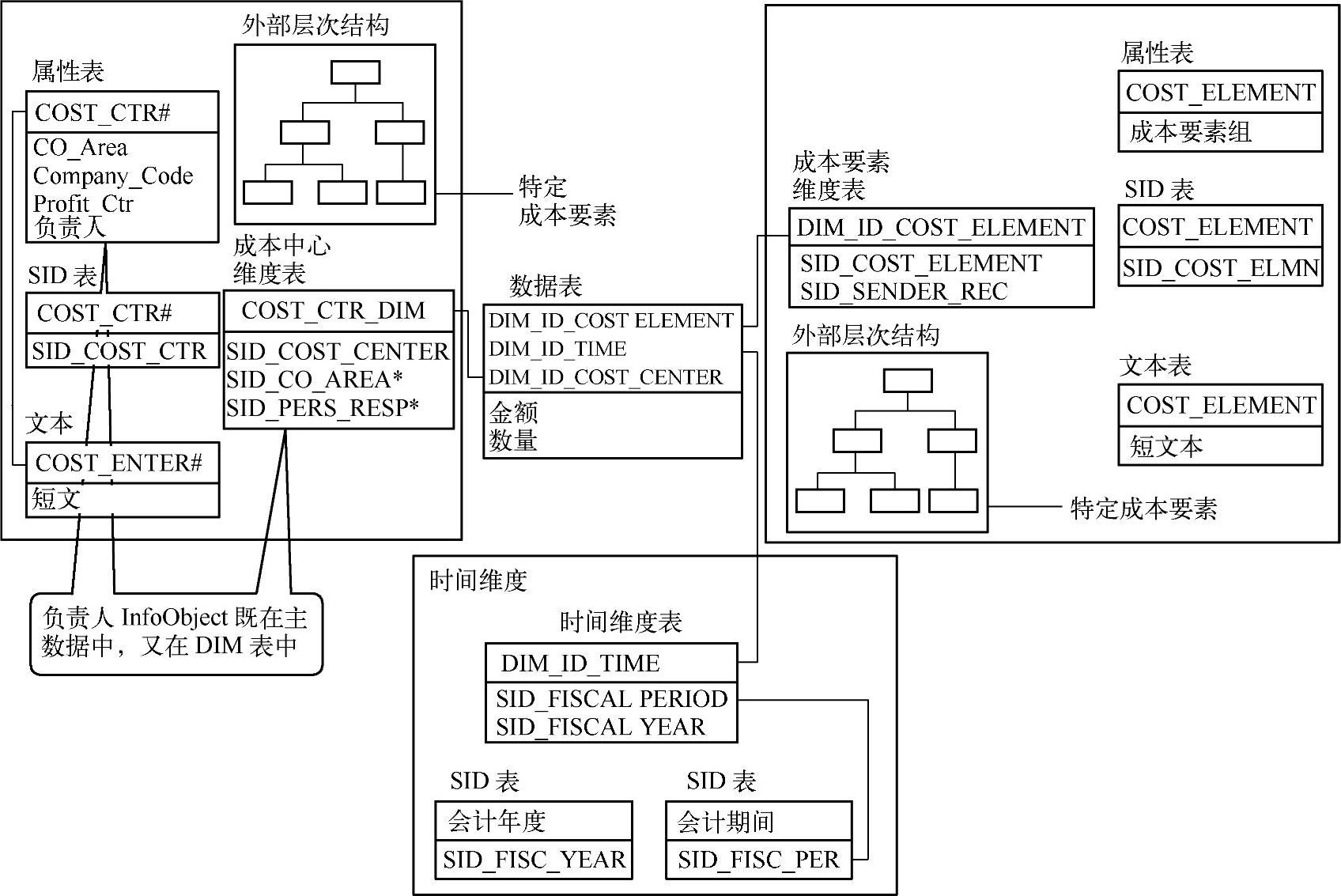
图2-38 扩展的星形模型举例
在图2-39中可以看到,BW星形模型是如何在经典星形模型的基础上增强的。该增强表现在维度表不包含主数据信息,主数据信息存储在单独的表中,这些表称为主数据表。主数据表“扩展了”星形模型,从而产生出一种扩展的星形模型。
6.BW信息块(InfoCube)
信息块是BW中多维模型的核心对象,大多数BEx报表和分析都直接或间接地基于这些对象,大多数的数据也都存储在信息块中。从报表角度讲,信息块描述了业务范围内的独立数据集,可以为其定义查询。
信息块中包含多维度布置的大量关系表,也就是说,它包含一个中心数据表,该表周围又有多个维度表,而同时,维度表中的SID编号又把这些维度表连接到与它们对应特征的各个主数据表(P、Q、X、Y和T表)。
图2-40显示了更多维度和更多主数据。正如在前面部分所讨论的那样,事实表中的事实称为关键值,维度属性则称为特性。这些维度表借助于键值与中心数据表连接在一起。与经典星形模型不同,特性不是维度表的组成部分,换句话说,这些特性值不存储在维度表中。系统为每个特性都生成了一个数字的SID键。这个“别名”键替代了作为维度表组成部分的特性。此处,SID代表主数据标识或代理标识(替代键)。在具有主数据的特性图中,这些键都加上了前缀“SID_”。例如,SID_Cost_Center是成本中心这一特性的SID键。维度表包含一个生成的数字主键,称为维度键。维度表由前缀DIM_ID_表示,此处,DIM_ID_CostCenter是成本中心这一维度的维度键。与经典星形模型一样,数据表的主键由多个维度键组成。
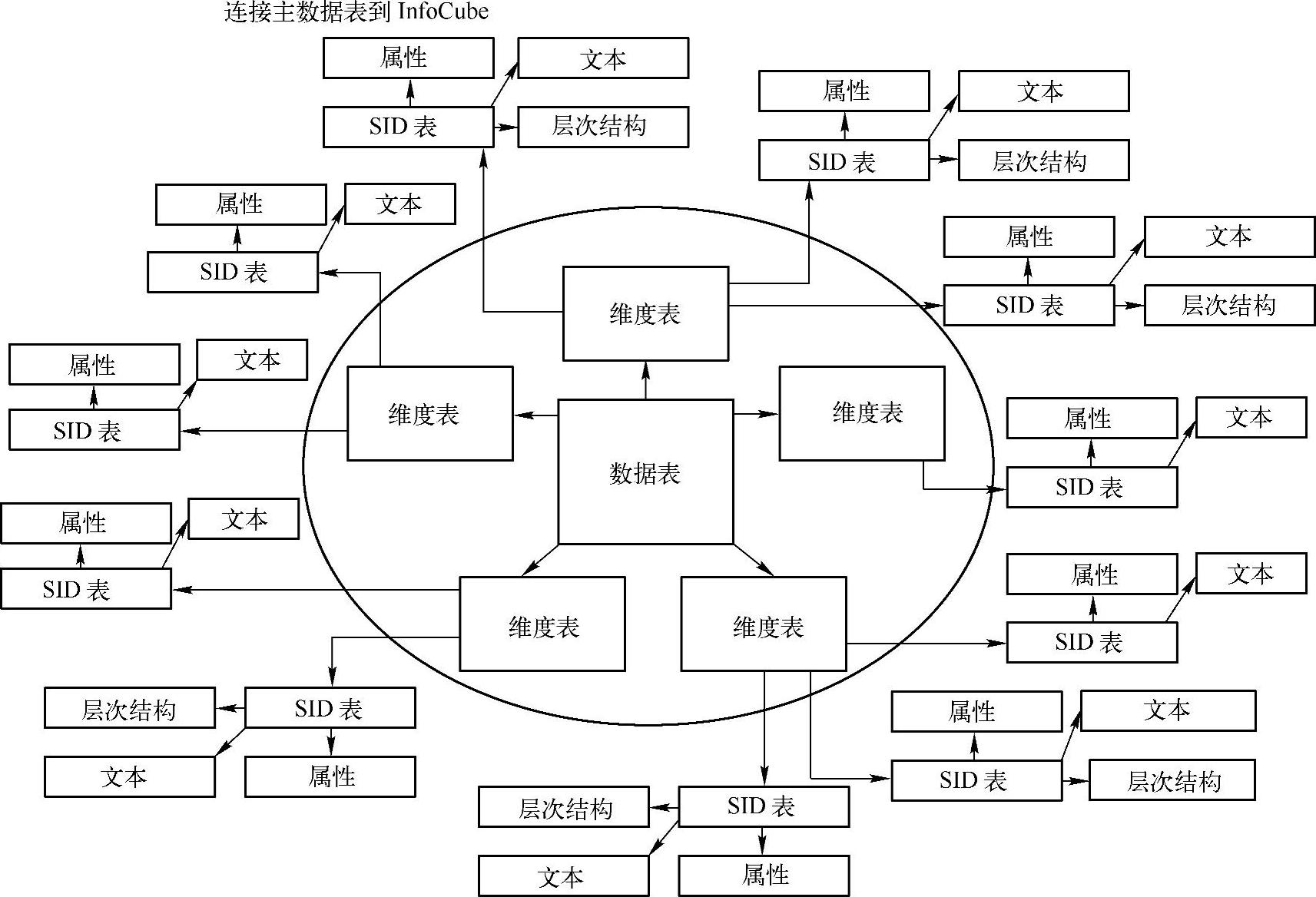
图2-39 主数据和信息块的连接关系示意图
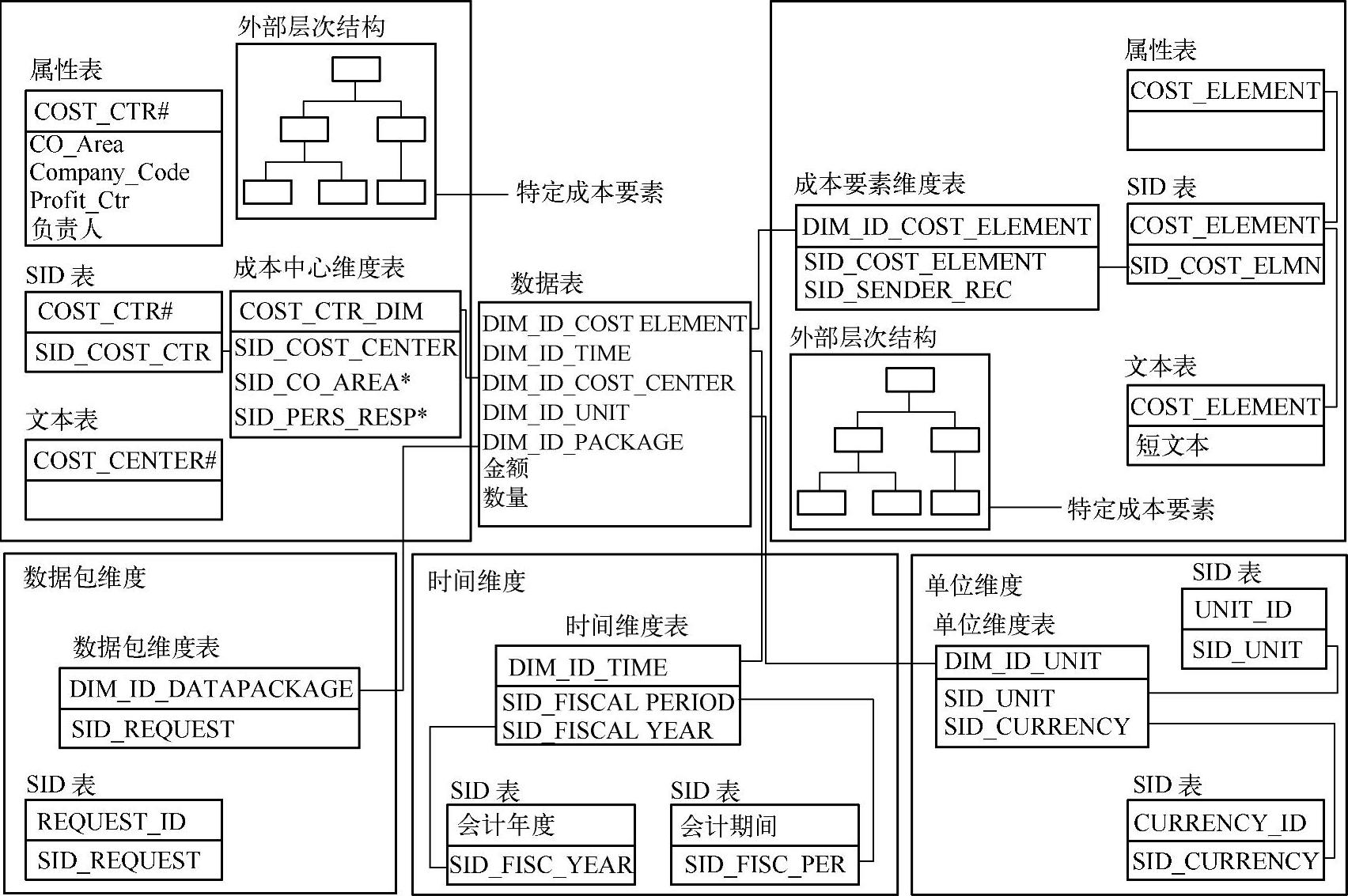
图2-40 主数据和维度表以及事实表的连接关系示意图
信息块中维度表的总个数最多为16个,其中3个由SAP提供,即技术维度(DIM_ID_DATAPAKET)、时间维度(DIM_ID_TIME)和单位维度(′DIM_ID_UNITS),因此用户可以为一个信息块定义多达13个维度表,并且必须至少定义一个。由于需要用交易的时间来增加意义,因此时间维度是必要的。单位维度存储计量单位或关键值的货币,因此也是一条关键信息。数据包维度是一个技术装载标识符,存储请求号以及数据包号等技术信息。
使用主数据的一个特殊好处是能够在不同的信息块间分享和使用共同的主数据。达到此目的的方法是,通过使用SID技术创建链接,把主数据从维度表中移除,其结果是,不同的信息块可以共享全BW系统唯一的主数据,换句话说就是,主数据独立于信息块存在,而且可以同时由多个查询在独立于多个不同信息块的情况下使用。图2-41所示阐述了这一概念。
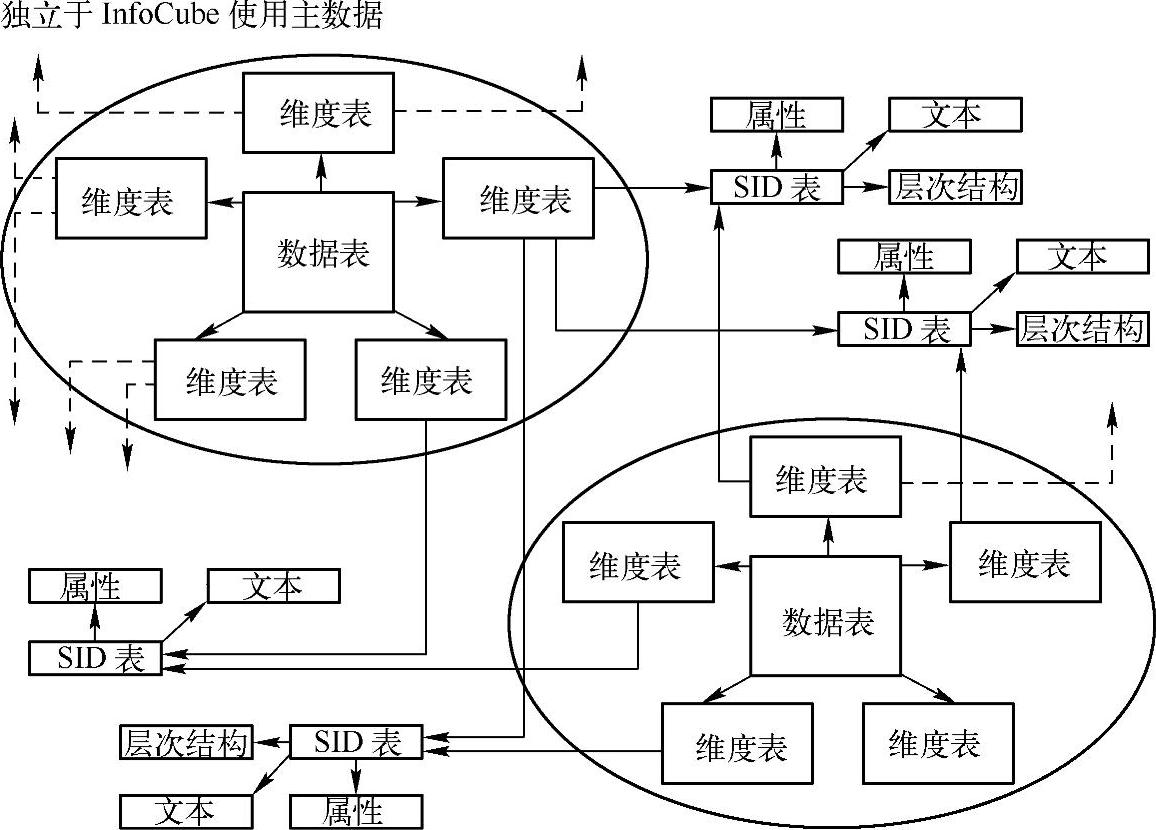
图2-41 信息块之间的主数据共享
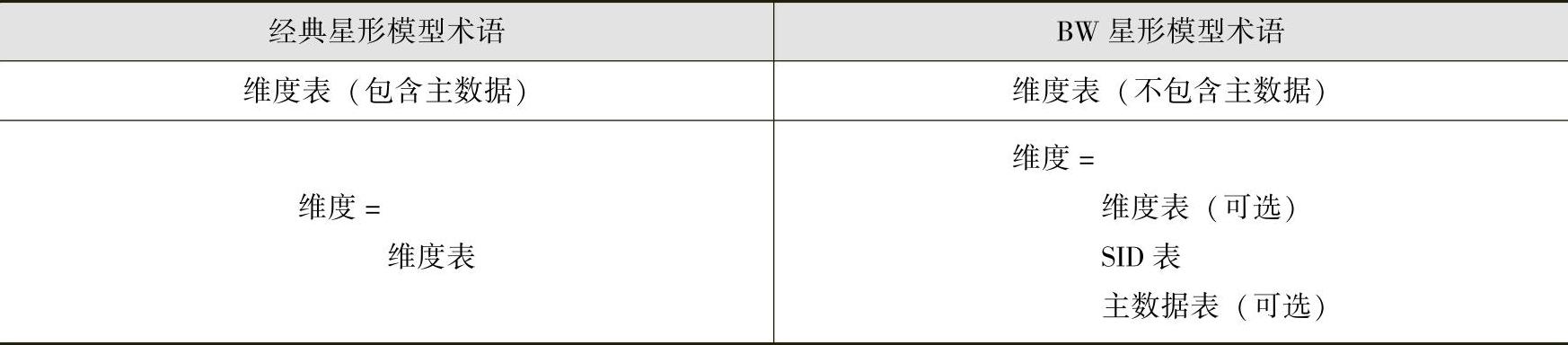
7.经典星形模型与BW星形模型的对比
首先比较两种模型的术语,具体见表2-1。
表2-1 两种星形模型的术语比较

(续)
(1)经典星形模型的优势和劣势
1)优势:由于只有少量的联合操作(只有数据表和相关维度表之间的联合操作),因此能相当好地执行数据访问。
2)劣势:
●维度表中存在冗余的条目。
●与事实数据(通过时间维度表提供时间参考)的历史记录(如何对时间建模)不同,维度(缓慢更改的维度)的历史记录不易于建模。
●繁琐的多语言能力,即在多语言环境下需要对所有语言在维度表中予以存储。
●对维度中的一些层次结构类型(如不平衡的并行层次结构)进行建模可能导致异常。
●由于集合和基本事实数据存储在相同表(数据表)中,因此降低了查询性能。
(2)BW星形模型的优势
1)得益于SID以及从维度表到主数据的连接,使下列建模成为可能:
●对缓慢移动的维度(时间相关的主数据)轻松建模。
●多语言能力。
●跨信息块使用主数据(共享主数据)。
●有能力处理特性的空值。
2)使用自动生成的INT4键(SID键和DIM ID键)访问数据,比通过长长的字母、数字键(所有的大数据量表都是100%编号)来访问数据,速度更快。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





