目前多数企业的数据治理组织多以临时组织的方式存在,这样的组织类似于项目部,对企业来说组织构建和培养上没有连续性,缺少数据管理经验和知识的有效传递;数据治理组织要实现由无组织向临时组织,由临时组织向实体与虚拟结合的组织,最终发展到专业的实体组织,设立各类职能部门,加强数据治理的专业化管理,并建立起专业化数据治理团队。
1.按照层级划分的数据治理组织结构
数据治理是一项复杂的系统工程,从组织层级角度看,需要决策层、管理层和执行层等3个层面相互配合才能完成。
1)决策层:主要由领导组成,确定数据应用战略发展方向,制定数据治理制度、重要决策等。
2)管理层:由业务和IT的部门负责人组成,其中业务部门领导负责相关业务数据标准、数据定义、数据质量和管理体系的确认,数据需求管控、项目管控等工作;IT技术部门领导负责相关技术实现,数据清洗、数据整理、数据存储、数据模型等,数据管理平台提供,数据需求分析,以及项目实施等。
3)执行层:由系统操作人员组成,主要职责是按照数据治理、要求和规范采集数据,并向相关组织提供需求和建议。
2.按照职责划分的数据治理组织结构
如果按照在数据管理中的分工来划分,数据治理组织可以分为4种角色:数据生产者、数据使用者、数据管理者和数据加工者。
1)数据生产者:数据的生产部门,一般是业务操作人员,负责数据的录入与质量初审,他们的工作决定着后期数据的质量。
2)数据加工者:专职进行数据集成、数据挖掘、数据管理平台开发与运维的部门,一般是IT部门人员承担,他们还负责数据质量的绩效评估工作,通过工具发现数据质量存在的问题。
3)数据使用者:是数据的分析与利用部门,一般是业务领导或对数据依赖性较高的业务部门,需要基于数据进行决策和业务运作。
4)数据管理者:专职对数据管理体系进行管控的部门,承担数据标准制定、数据治理体系制定与完善等职责。具体如图8-6所示。
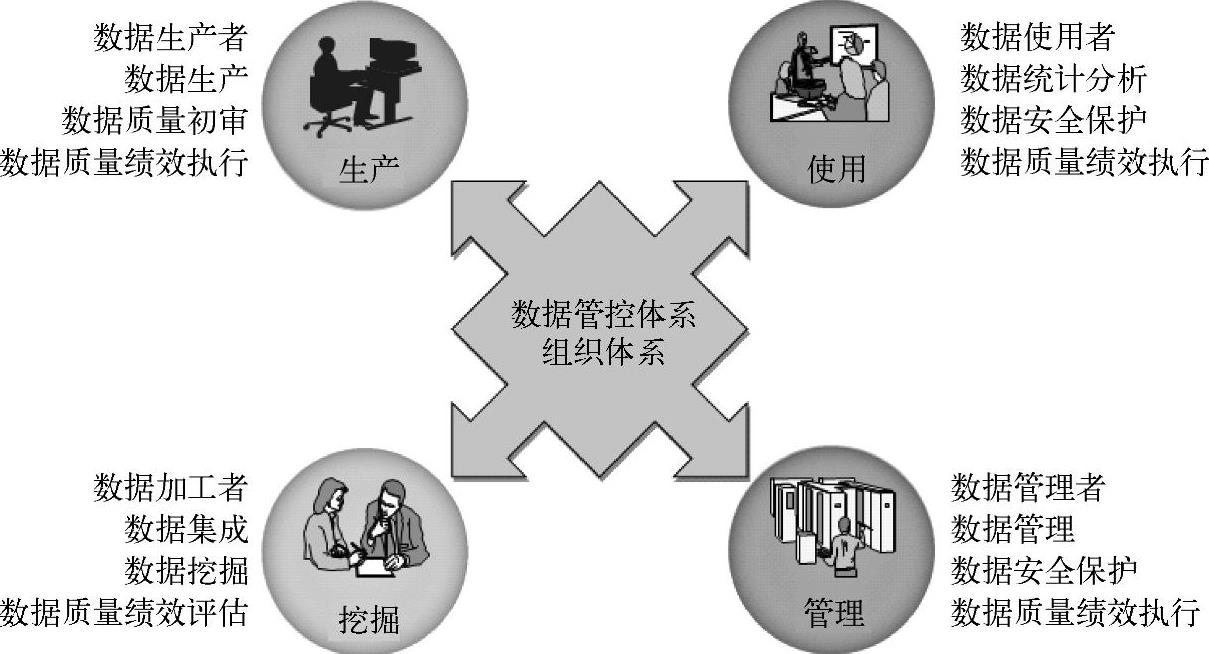
图8-6 数据管理的角色划分示意(www.daowen.com)
上述4种角色中,数据的生产者和数据的管理者这两种角色是比较清晰的,但数据加工与数据使用者两种角色具有不同的划分方式。
第一种方式:数据加工部门既负责数据的集成、数据管理平台建设与运维等技术工作,还负责数据建模、分析等数据应用性工作,数据分析完成后将结果推送到数据使用部门。
这种模式下,数据加工部门相当于一个Hub,解决一个组织大部分的数据需求。当数据使用部门需要数据时,他们提交需求给数据加工部门,然后数据加工部门开始抽取、运算和分析,把数据和结果返回给业务部门。
第二种方式:数据加工部门仅负责数据的集成、数据管理平台建设与运维等技术工作,数据使用部门负责数据的建模与分析工作,自主根据业务需求进行模型构建和数据分析。
这种模式下,数据分析人员分布到各个业务部门去。他们帮助业务部门运用数据系统来获取和处理数据,并与业务人员一起更直接、更快捷地解读数据,并将结果直接应用于业务。
这两种模式在现实中都存在,其优劣势比较如表8-1所示。
表8-1 两种数据分析模式的优劣势对比

采用第一种方式的组织,在最开始开展数据分析时可能会进展很快,但他们很快会发现,自己没日没夜地工作越来越难以满足业务部门的需求,自身价值和定位都受到质疑。原因是数据分析人员不了解业务,他们不能深刻、及时地了解业务部门的需求。
正确的做法是让数据分析人员回归业务部门,而不是龟缩在数据加工部门中。数据属于业务,数据分析人员当然也属于业务,让数据分析师分布到各个业务部门去。因此,第二种模式才是一种科学、长久的机制。
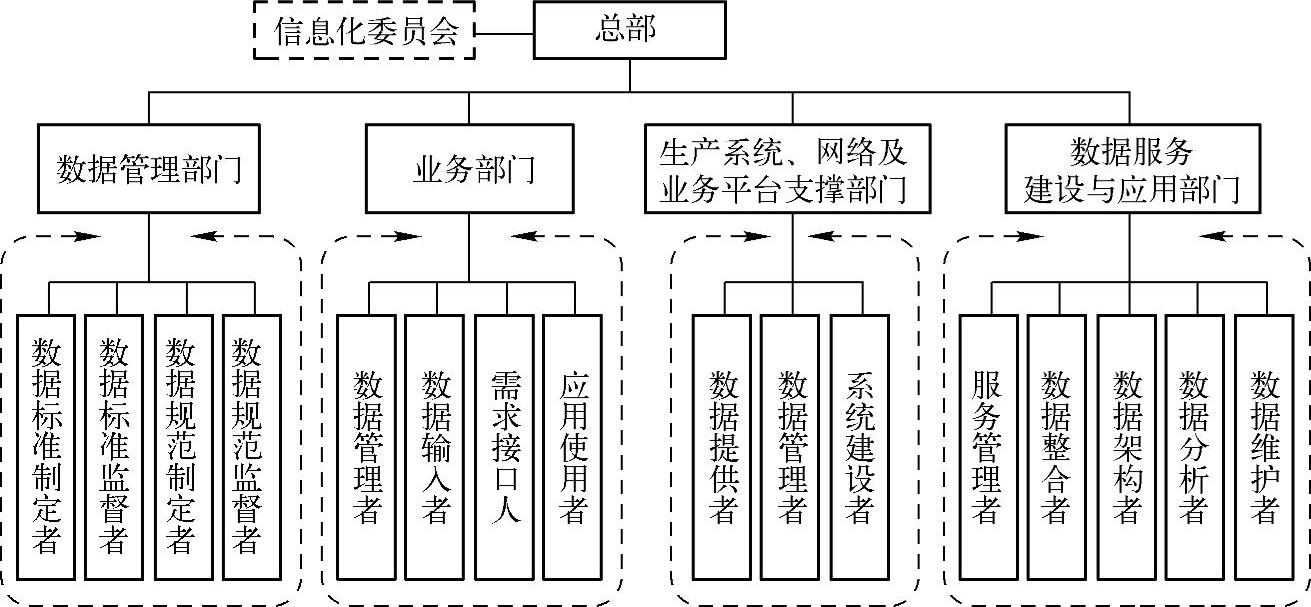
图8-7 某企业数据治理组织结构设置示例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







