数据架构与业务架构和应用架构都是有关系的,体现这一关系的是数据/业务和数据/系统分布分析。数据分布,一方面是分析数据的业务,即分析数据在业务各环节的分布关系,这是数据/业务分布分析;另一方面是分析数据在系统内和系统间的分布关系,即数据/系统分布分析。
1.数据/业务分布分析
数据/业务分析就是从业务架构出发,分析每一个业务环节涉及哪些数据,重点是分析数据在哪个环节、由谁创建。当然,这一分析除了要考虑业务因素外,还要遵循以下几大原则。
● 当期数据与历史数据的分离。
● 生产数据与分析数据按不同的数据组织方式分离。
● 操作数据与查询数据分离,减少生产系统压力。
● 体现数据的生命周期管理的需求,包括数据的产生、数据的采集、数据的加工、数据的利用和数据的归档几个阶段。
图6-5是某企业的数据/业务分布示例。
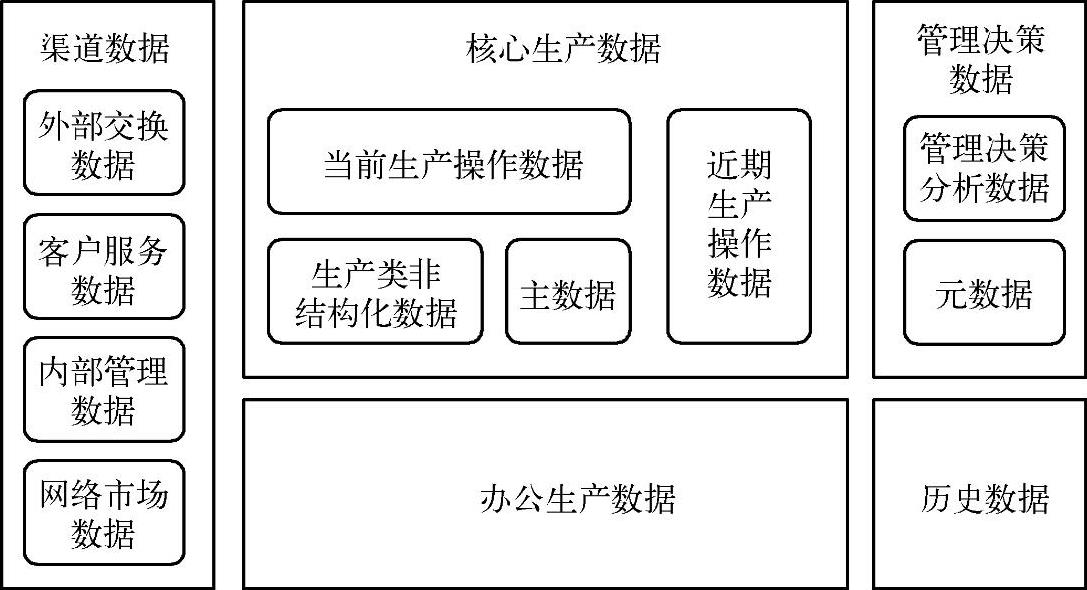
图6-5 某企业数据/业务分布示例
图6-5所示的是某企业数据/业务分布的顶层框架图,包含以下几类数据。
1)渠道数据:主要是企业与外部交互的数据,包括外部交换数据,即与合作伙伴、银行和政府等交换的数据;客户服务类数据,即与客户交互的服务类数据;内部管理数据,即企业向外公布的数据,包括公告、新闻和财报等;网络市场信息,即从互联网上抓取的市场类、竞争对手类信息。
2)核心生产数据:主要是支撑企业运营的核心类数据,包括当期生产类数据,即为了维持生产需要的研发、采购、生产和物流类数据;生产类非结构化数据,即与生产相关的文档、图片和视频等非结构化数据;主数据,即与生产相关的产品、供应商和物料等主数据;近期生产操作数据,即与当期生产数据同构但需要保持更长时间的生产类操作数据。
3)行政办公数据:主要是支撑核心业务运营的综合行政管理类、财务类及人事类等综合管理数据。
4)决策支持数据:主要是支撑分析与决策支持类的数据,包括数据仓库和数据集市中的决策分析数据;还包括元数据,即记录数据抽取路径和数据分析指标体系的元数据。
5)历史数据:分析数据中的业务明细数据经过一定时间后迁移到历史业务明细数据中;归档的历史数据可以脱机存放,按照数据生命周期管理的理念建议存放在速度快、容量高的磁带库中。
2.数据/系统分布分析
数据/系统分布分析数据在系统中的分布关系,包含数据/系统总体分布框架、单一应用系统中的数据结构分析、多个系统间的数据引用关系分析,以及数据的存放模式分析等内容。
(1)数据/系统总体分布框架(https://www.daowen.com)
应用架构与数据密切相关,应用架构是数据架构的前提,应用架构的划分是数据/系统分布的重要的、核心的输入,最终影响数据架构中的数据分布设计;同时,在应用架构中,各个应用系统之间的数据如何交互也决定了数据架构中数据的存储位置及数据间交换的方式。因此,数据/系统分布设计要结合应用架构的划分,并综合考虑数据的内容、分类、特点及数据的逻辑分布状况,将数据在系统中进行合理布局和存储设计。
一般来说,在进行数据/系统分布分析时要遵循以下几大原则。
1)生产数据库和分析型数据库分离。根据数据应用的业务特点及技术特点,可以看到不同的数据其业务重要性、实时性不同,数据应用的系统资源消耗和对系统造成的压力也有所不同。从前台交易型业务到管理审批型业务再到统计分析型业务,其业务的时效性要求逐步降低;从技术角度看,系统资源的消耗却在逐步增加。因此,建议采用生产数据库与分析型数据库分离的原则,将生产型数据和管理决策分析型数据分别部署在不同的数据库上,以确保生产交易型业务稳定高效地运行,不受管理决策分析应用的影响。同时为确保生产交易型数据向管理决策分析型业务迁移过渡过程的持续稳定,且不会对生产交易业务产生性能压力。
2)不同生命周期的数据分别存放。业务过程数据记录着业务发生的过程,会随着时间的推移而不断增长。为了保持系统的高效运行,必须把陈旧的业务过程数据从生产数据库中清理出去。同时为了维持数据的完整性和业务的可追溯性,需要建立历史数据库,将历史的、陈旧的业务过程数据进行封存。
3)结构化数据和非结构化数据分离。在业务处理过程中会产生大量的信息,这些数据既有结构化数据,又包含大量的非结构化数据,建议将两者分开,实现结构化数据和非结构化数据的分别存储,减少生产的库容量,提高生产库的性能和保障。当然,在大数据系统中,可以将两者整合在一起进行存储和处理。
图6-6所示是某企业数据/系统分布设计总体框架图。
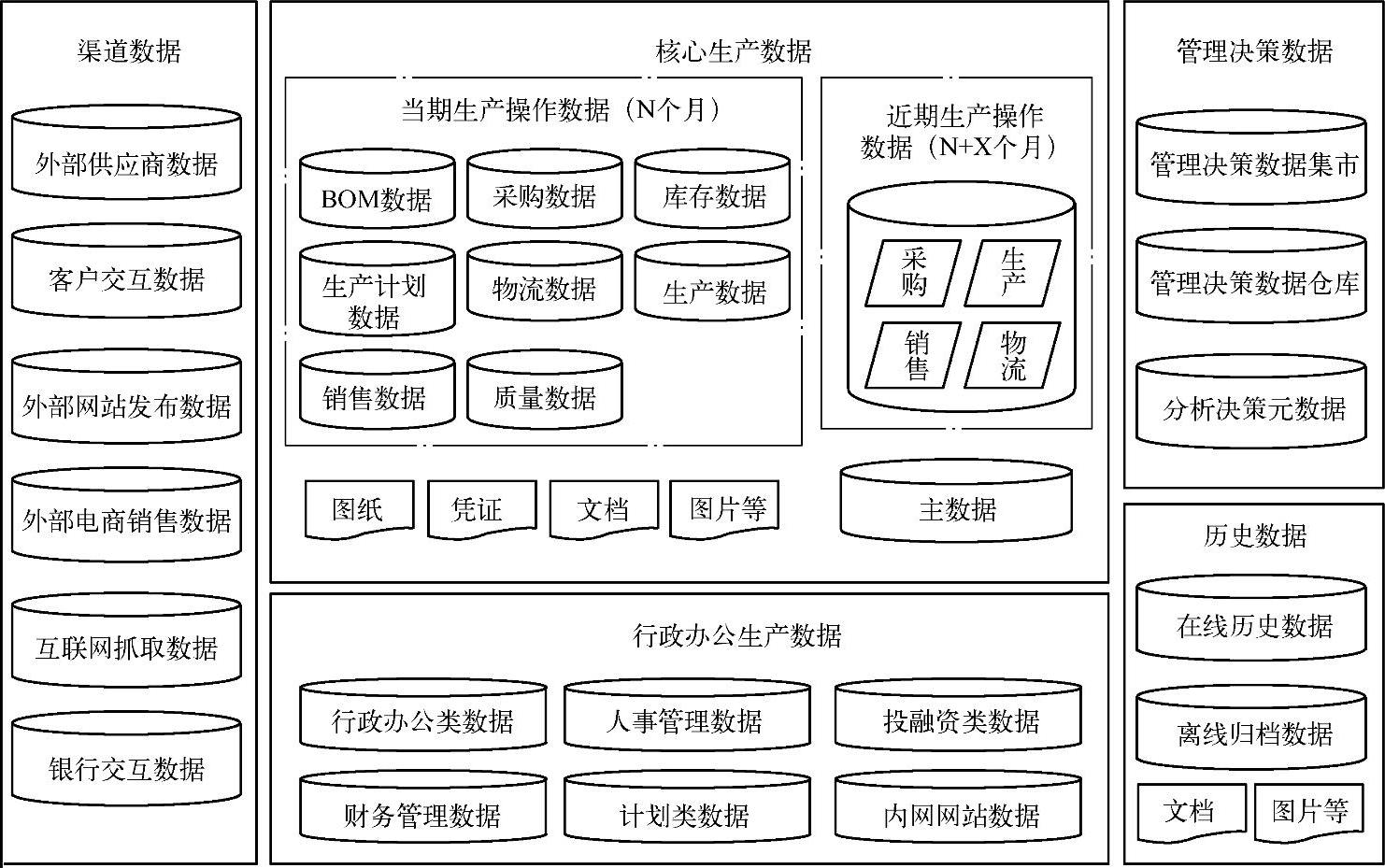
图6-6 某企业数据-系统分布总体框架图
另外,对于一个拥有众多分支机构的集团企业,还要考虑统一系统在不同组织与地区之间的分布策略。从地域的角度看,数据分布有数据集中存放和数据分布存放两种模式。数据集中存放是指数据集中存放于企业总部数据中心,其分支机构不放置和维护数据;数据分布式存放是指数据分布存放于企业总部和分支机构,分支机构需要维护管理本分支机构的数据。企业要根据自身需求及技术实现能力确定数据在总部和分支机构间的分布策略。
(2)单一系统数据库结构分析
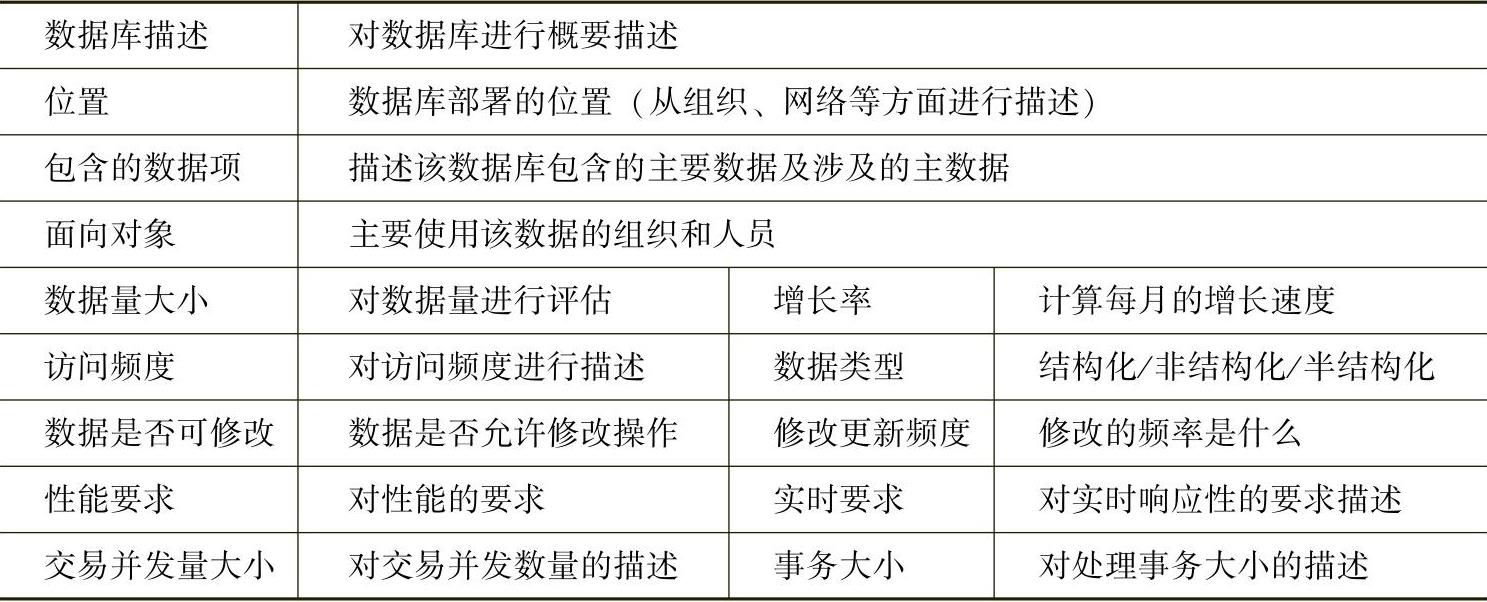
确定了总体的数据/系统分布框架后,还要对每一个数据库进行详细的描述,描述可以从数据库的位置、包含的数据项、面向对象、数据量大小、数据增长率、访问频度、数据类型及性能要求等因素入手。对某一个数据库的描述可以通过表6-2来进行。
表6-2 单一数据库描述表格模板
(3)多个系统间的数据关系分析
在清晰了单一数据库结构后,还要明确多个系统间的数据关系,尤其是主要数据在多个系统间的引用关系,要解决这一问题,就需要CRUD模型。CRUD是建立(Create)、读取(Read)、更新(Update)及删除(Delete)这4项操作的缩写。通过数据CRUD规划,可以明确系统中的核心数据由哪些系统产生,哪些系统有权去读取这些数据,这些数据的更新权和删除权又属于哪些系统,确保实体对象来源的唯一性和一致性,以及在数据不一致时很容易确定以哪个系统的数据为准。图6-7所示是某企业的CRUD示例。
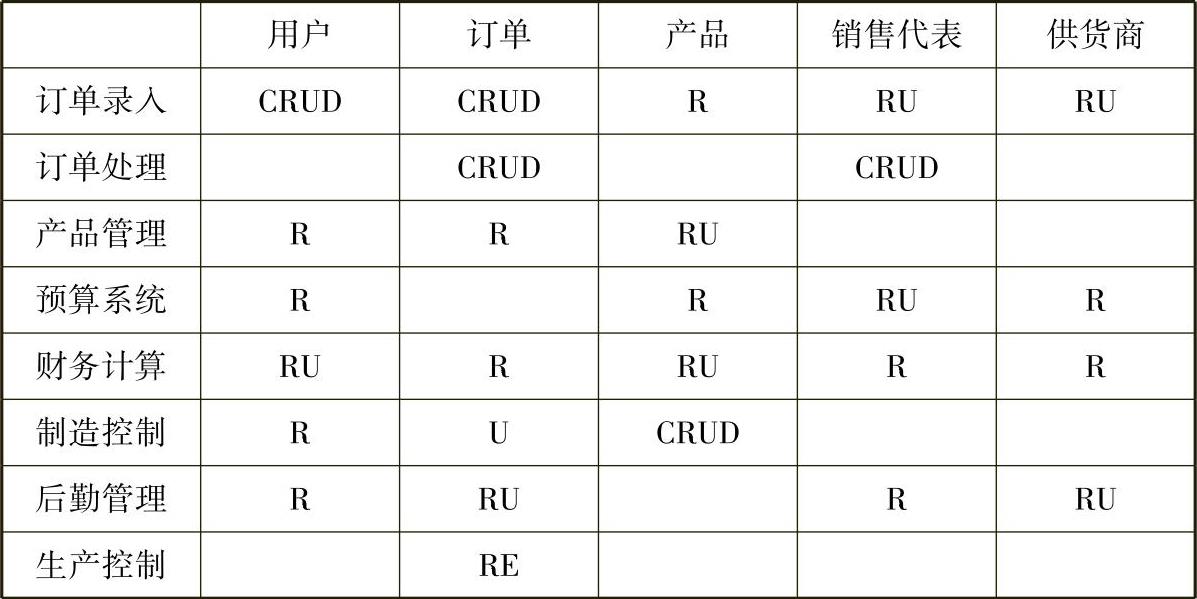
图6-7 某公司数据与应用的CRUD分析示例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





