本书的研究过程是对管理案例资料的实证性研究,通过统计处理抽取可靠的管理冲突参数和原理解集。案例的选取需要集中于一般管理领域的创新资料,以促使研究的结论反映一般管理参数的冲突化解规律,并且资料中基本不要进行大量的理论评述(这一特点在MBA教学案例中往往比较突出),避免资料本身对分析过程的误导。
管理案例的一个重要来源是哈佛大学编写的用于MBA学员管理学案例训练的案例教程。这些案例资料的优势在于,出于案例讨论性研究的教学传统,哈佛大学的案例编写侧重表述一般的管理问题,并不进行人为的专业领域划分和描述;此外,案例本身注重大量背景材料和管理事件过程的一般陈述,较少有倾向性的表述和理论抽象的倾向,有利于研究者的无偏性分析。研究还采用了我国北京大学编写的部分MBA教学案例,其中有更多的国内管理案例材料,并能反映国内学者的一些观察视角,可以在很大程度上保障资料数据的全面性,使研究结论更为可靠。
案例资料的分析主要是进行文献内容分析,过程是:首先对资料进行通读,作整体把握;然后抽取其中的“管理事件”资料,管理事件一般能呈现一个完整的管理问题的解决过程,当然,一个案例可以包括若干个管理事件过程,管理事件既可能贯穿于整个案例(即企业的整个发展过程),也可能存在于案例的某些部分(即企业发展中的某个或某些过程);最后,从提取的事件资料中抽象分析所化解的管理冲突和所运用的创新原理。本次研究的案例分析主要基于研究者自身的管理学研究经验。
以下以“电子计算器的将军”案例为例,简要展示文献分析的过程。
通过案例的通读,“电子计算器的将军”案例材料只涉及一个“管理事件”,是关于夏普公司在电子计算器市场的新产品开发的问题。提取案例文献中与管理事件相关的内容如下:
“……夏普为何能在多年的竞争中屹立不倒呢?这是不断开发新技术,逐步生产更便宜、更良好的机种的缘故。”
“当年,夏普产品中的半导体部分,全部都得依赖别人,连计算器的主体也是向外采购。当时的夏普,事实上只是个装配品而已……为了提高电子计算器的性能,势必只有改采LSI(大规模集成电路)为构造的主体。因为原来使用的IC,功能实在有限,但是光是从IC转换到LSI,就不是一件容易的事……毅然决定走上自制LSI的路。”
“夏普所以能开发出日本第一台‘电子翻译机’及世界最小的普通纸复印机等,都是高度运用LSI的结果……”
可以看出,夏普有进行自主新产品开发的强烈意愿,但开发怎样的技术和产品以适应市场的需要却很难把握,抽象为试图优化“30.研究与开发”参数、并避免“12.适应性”参数劣化的管理冲突问题。夏普既没有坚持单纯的技术模仿、技术依赖,也没有采用全面技术开发的策略,而是专注于核心技术的开发(不对称原理);而且核心技术往往具有较好的产品拓展能力,惠普就是适时依据新的市场需求,不断将所掌握的LSI技术引入新的产品结构中,大大降低了产品开发的风险和周期(等势原理)。这样,夏普应用的创新原理是“4.不对称”和“12.等势”。
本书研究共进行了211个管理案例的抽象研究分析,其中来自哈佛大学的案例有123个,约占案例总数的58%;北京大学的案例88个,约占42%。通过案例分析共形成了361条抽象数据。表6-8显示了部分数据的情况,完整的数据情况详见附表B。
表6-8 管理案例分析(部分)
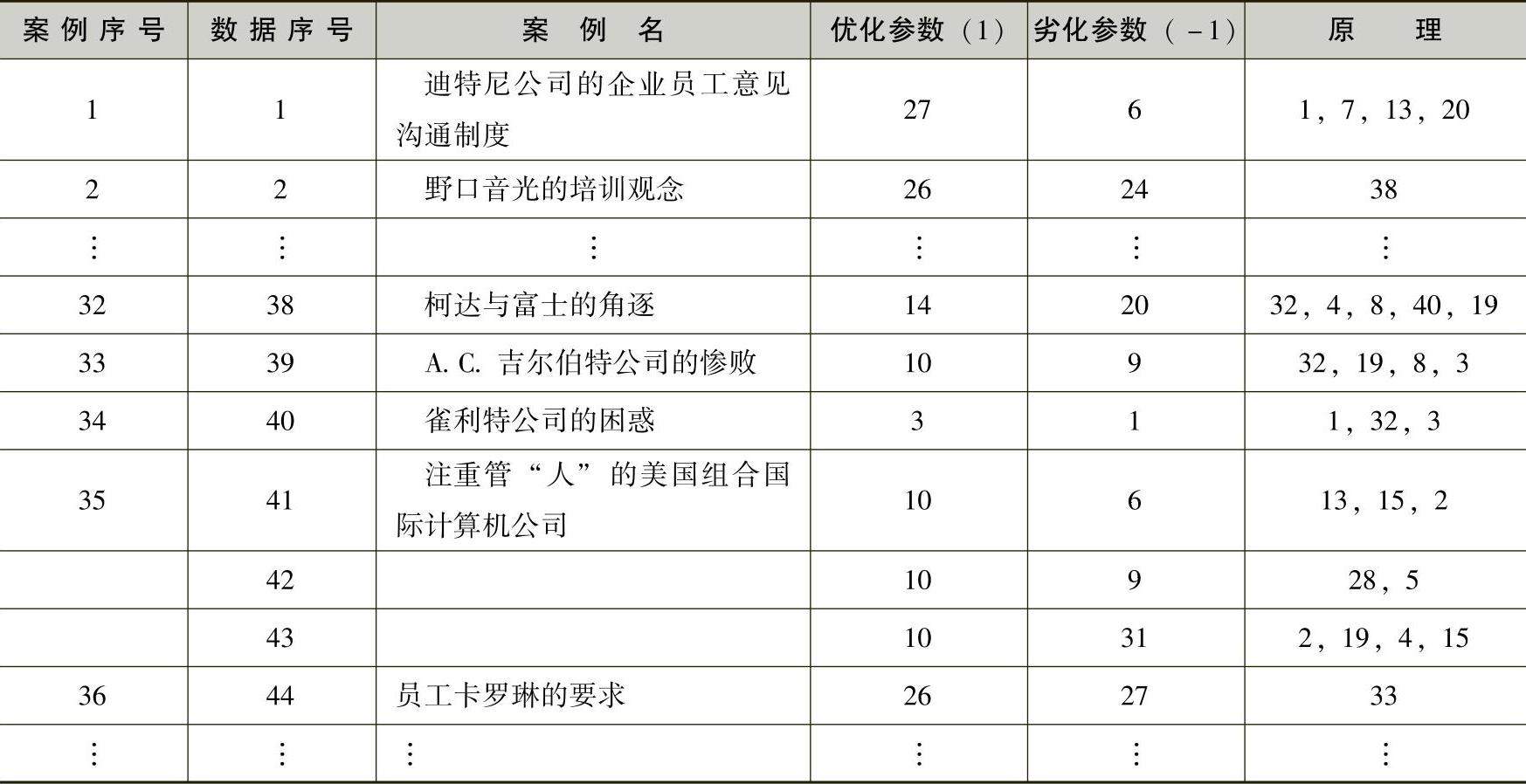
将附表B数据转化为如前表6-7样式的统计二维表格式,以便于统计软件SPSS的处理(由于这一转化只是涉及数据格式的简单转变,表6-7数据的详细情况不再列出)。其中,表6-7中“记录”的序号对应为附表B或表6-8中的“数据序号”。
6.2.3.1 层次聚类过程
出于稳健处理数据的考虑,这一层次聚类过程采取的是SPSS提供的组间平均距离法(Between-.roups Linkage)。大量的实践证明,组间平均距离法是一种非常优秀和稳健的方法,在多数情况下表现最为优异。
层次聚类最重要的两个输出是聚类过程表(Agglomeration Schedule)和谱系图(Dendro-gram)。本层次聚类过程主要目的在于确定合适的聚类类别数量,所以可以不太在意谱系图的输出,而主要是对聚类过程表的分析,特别是对表中聚类系数(Coefficients)的分析。
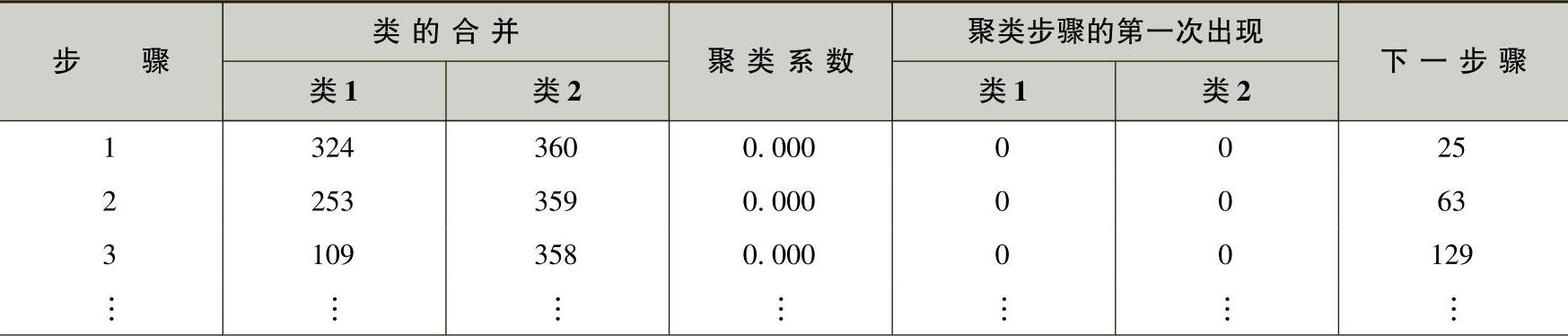
对表6-8数据进行层次聚类,形成聚类过程表(表略),表6-9列出了一些关键部分。聚类过程表中,第1列列出了聚类过程的步骤号;第2列和第3列列出了在某一步骤中,哪些记录参与了合并;第4列为每一聚类步骤的聚类系数;第5列和第6列表示参与合并的记录(类别)是在第几步中第一次出现的,0代表该记录是第一次出现在聚类过程中;第7列表示在这一步骤中合并产生的类别,下一次将在第几步中与其他类别再进行合并。
表6-9 聚类过程表
(续)
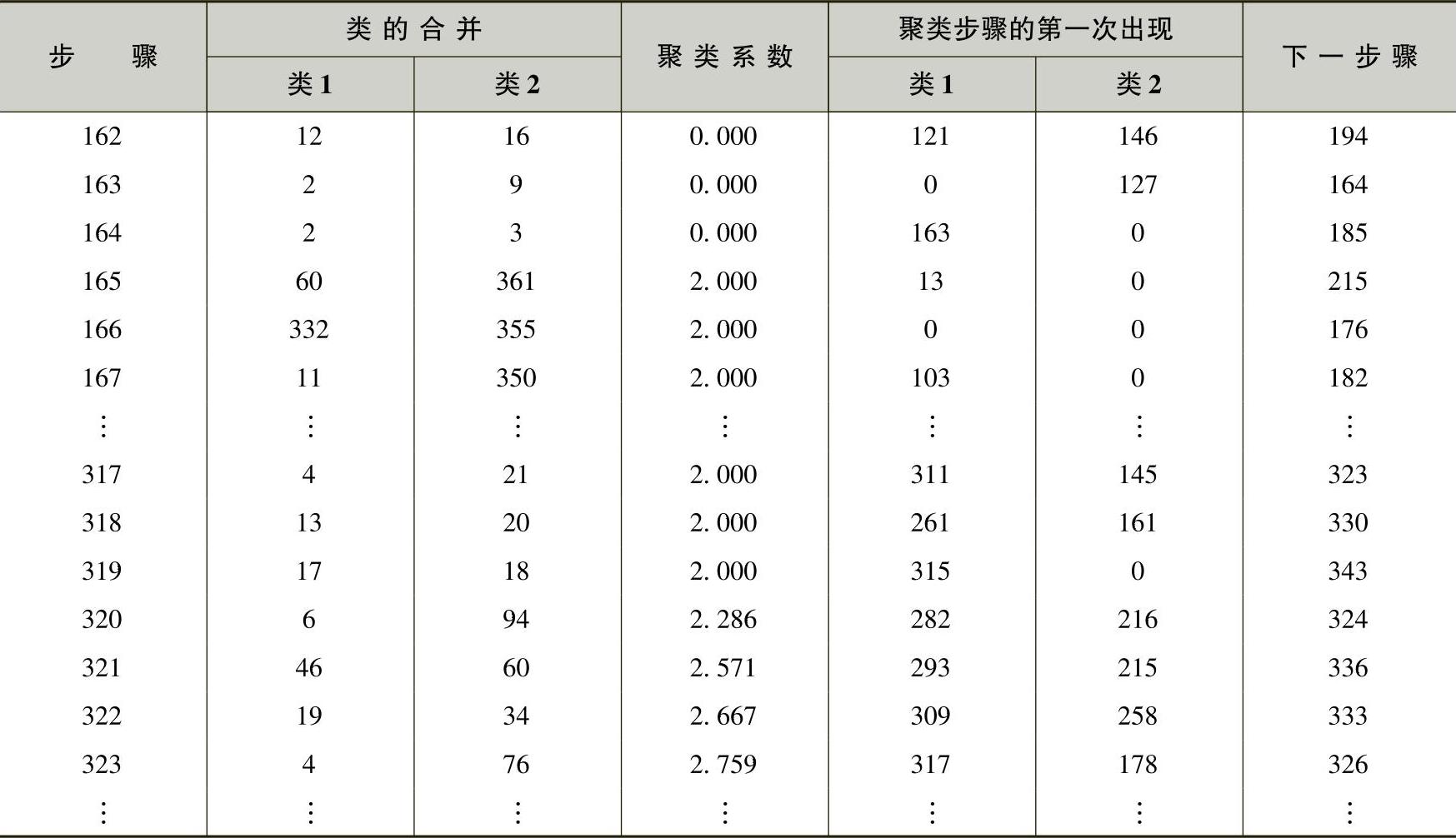
在需要判断数据应该分为多少类别时,聚类系数有着很好的参考价值。在本聚类过程中,从第164步到第165步,聚类系数发生巨大变化,可以从统计意义上认为聚类过程结束于第164步是合理的,此时所有数据被分为90类。同样,从第319步到第320步聚类系数也发生了大的变化,可以认为聚类过程结束于第319步也是合理的,此时所有数据被分为125类,这说明数据被分为125类也是合理的。这样,数据类别为90类或125类都是具有明显统计意义的。下一步的分析将分别按90类和125类进行快速聚类过程。
6.2.3.2 K.均值聚类过程
1.最终类别中心点
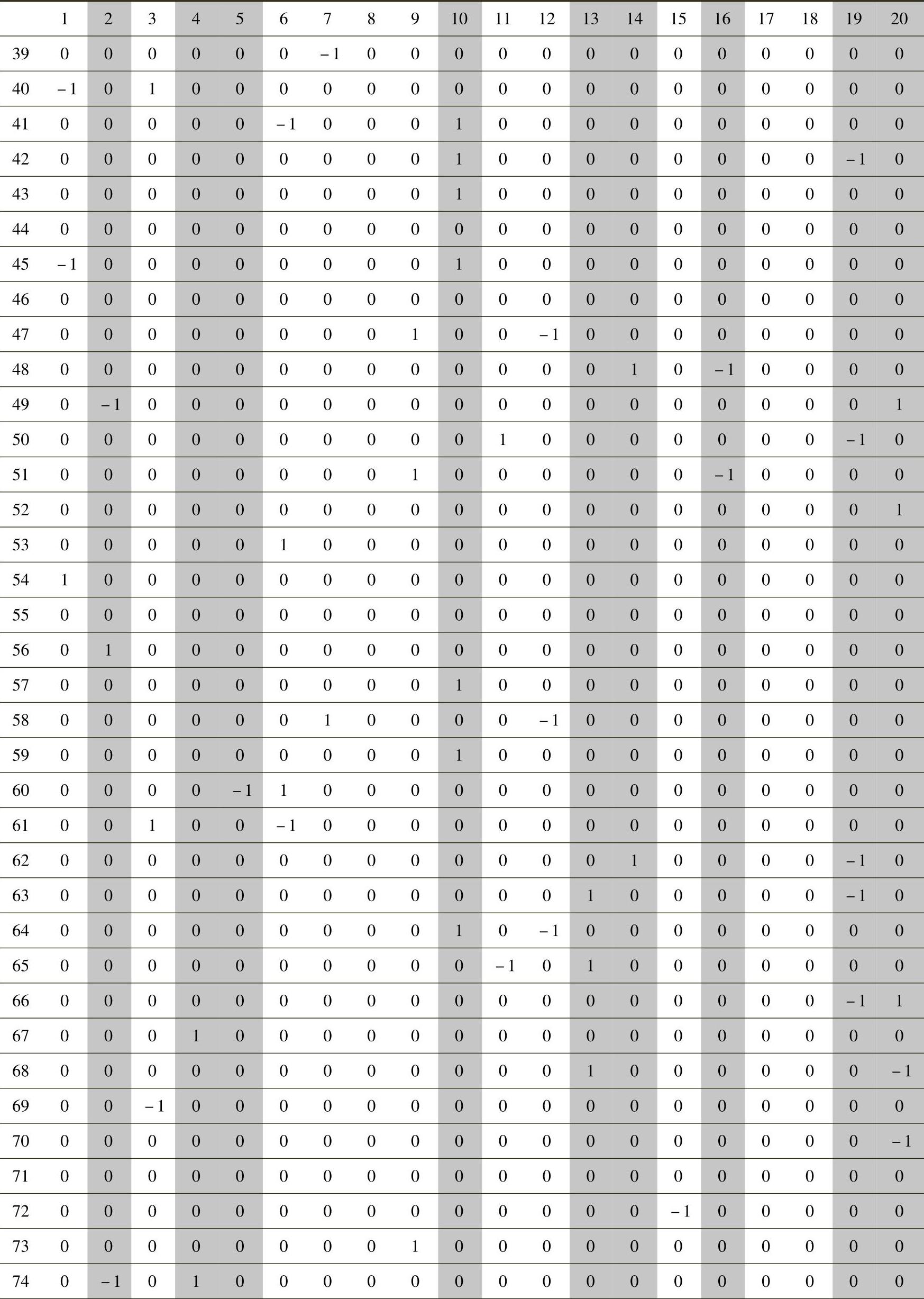
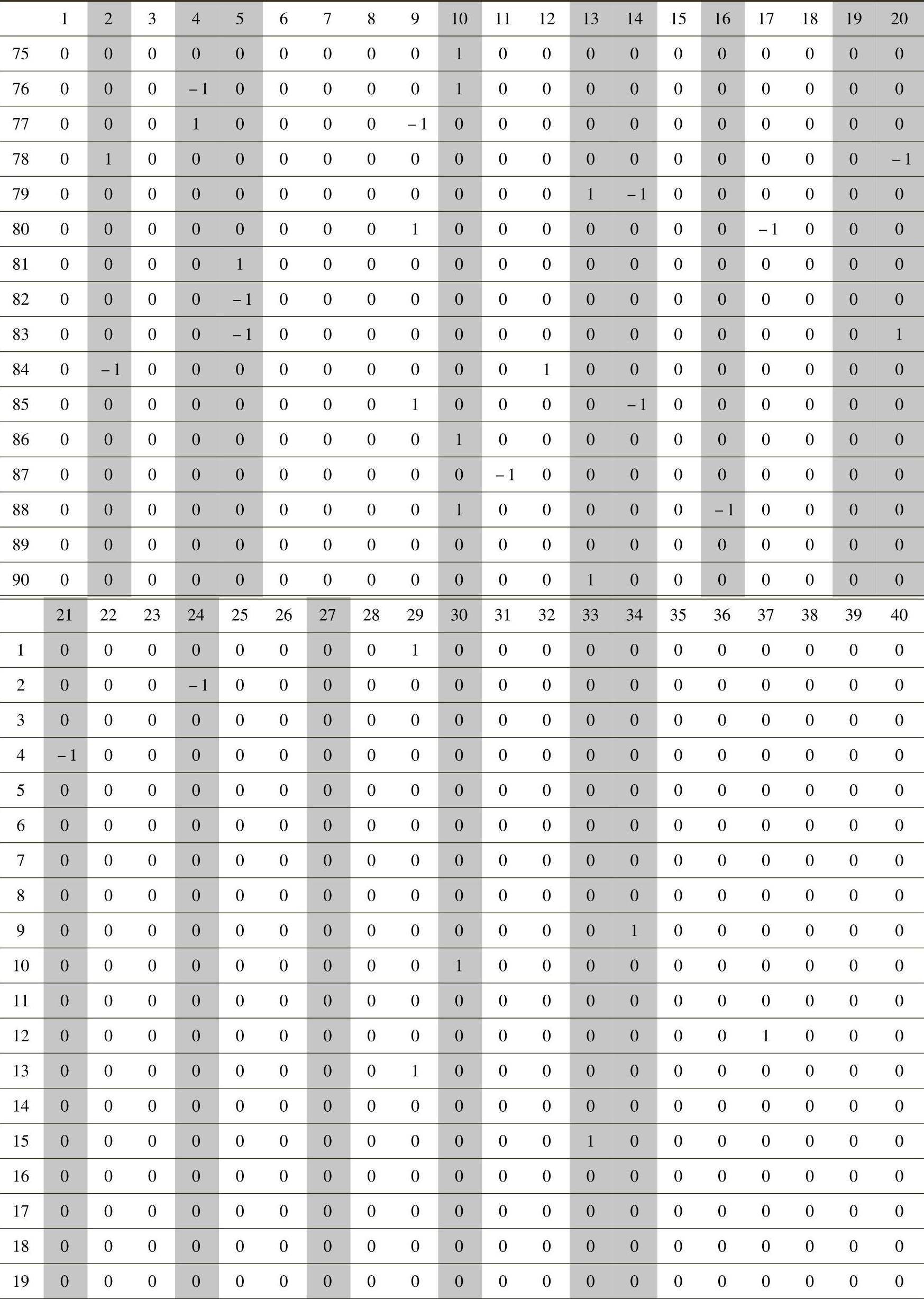
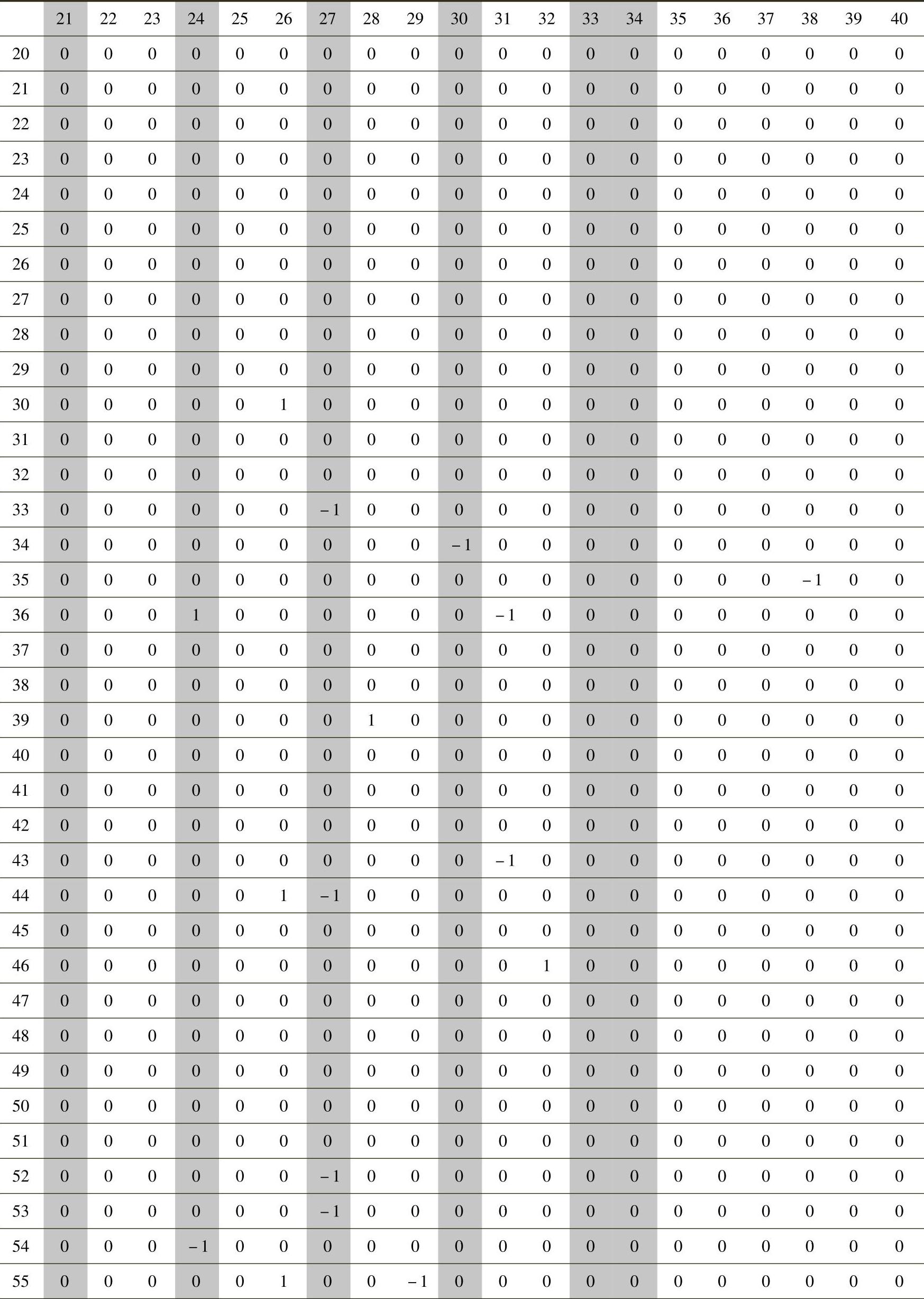
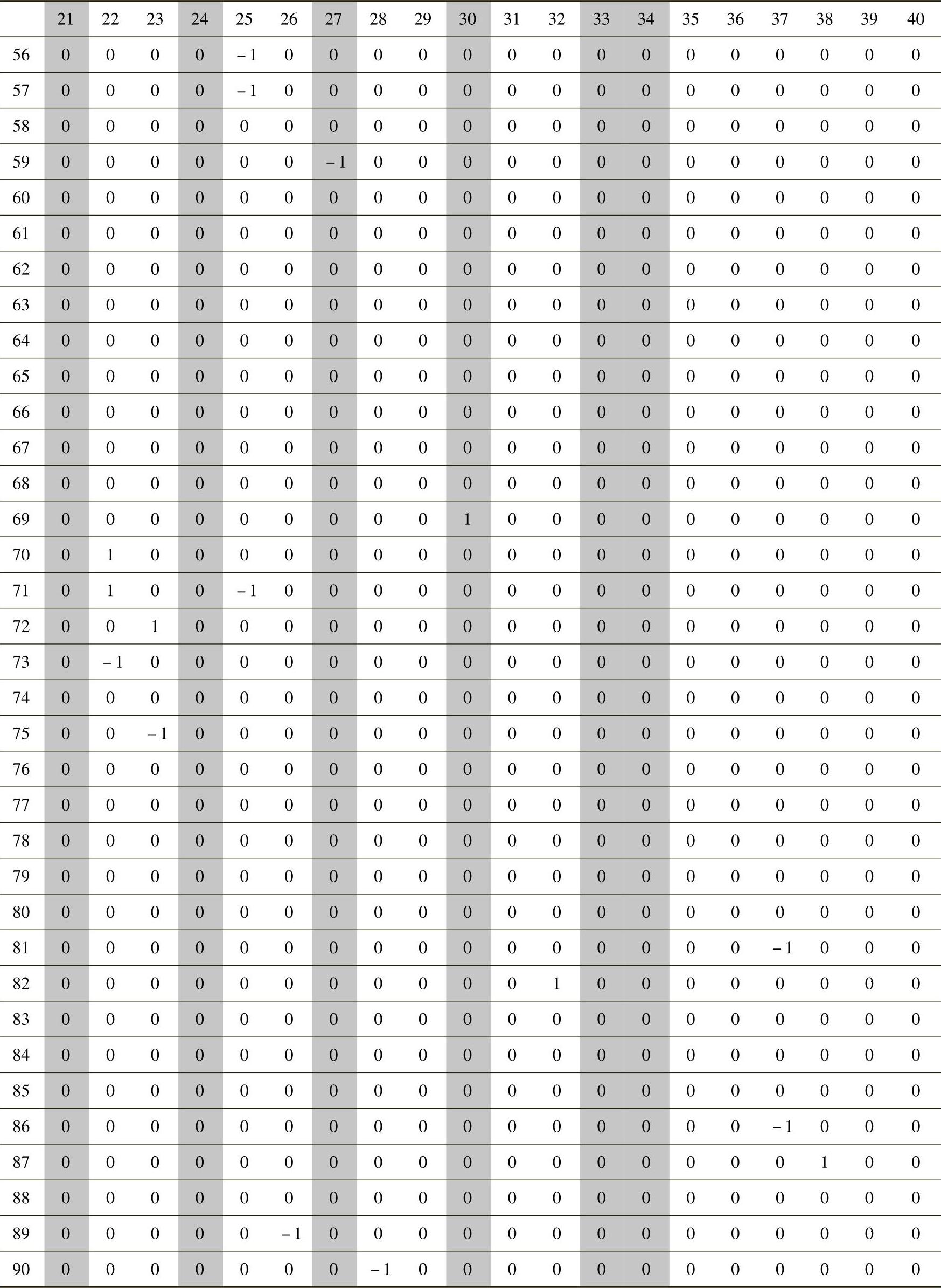
SPSS的“K-Means”过程提供快速聚类的整个迭代过程。其中,比较重要的结果是最终类别中心点,显示聚类完成时各个类别在各个变量上的平均值。对于本问题中的实际意义在于,各类中平均值为1或-1的参数变量即为相应创新问题类别中倾向优化或劣化的变量。
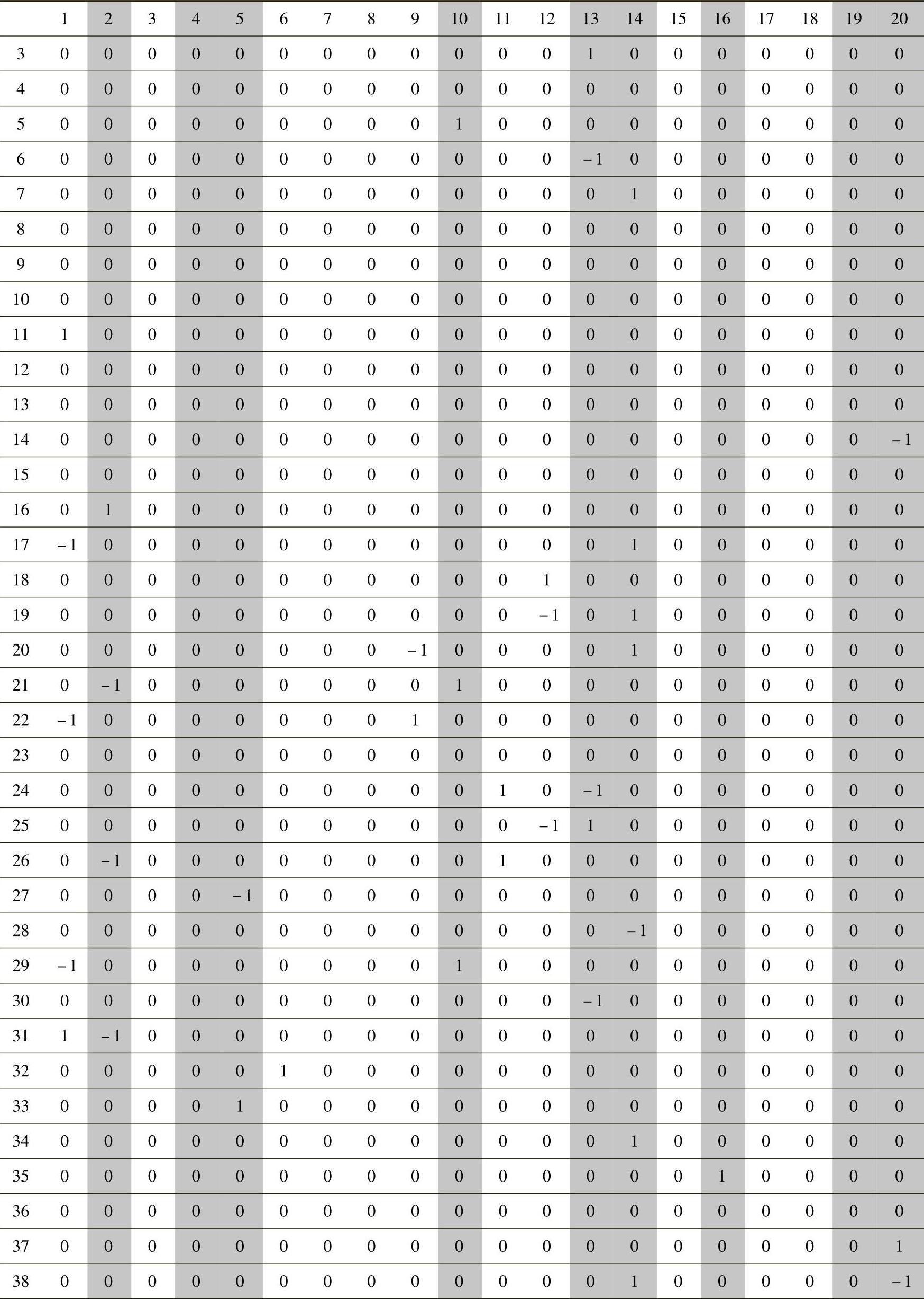
表6-10为进行90个聚类类别时的最终类别中心点情况。其中,第1行序号为40个管理参数序号,第1列序号为聚类过程后的90个类别序号。例如,第1类中6和29号变量的均值分别为-1和1,显示第1类别是优化参数为29(管理方便性)、劣化参数为6(制度化)的一类管理问题。
表6-10 最终类别中心点

(续)
(续)
(续)(https://www.daowen.com)
(续)
(续)
同样,可以得出进行125个聚类类别时的最终类别中心点情况,此处不再具体展示。
2.单因素方差分析
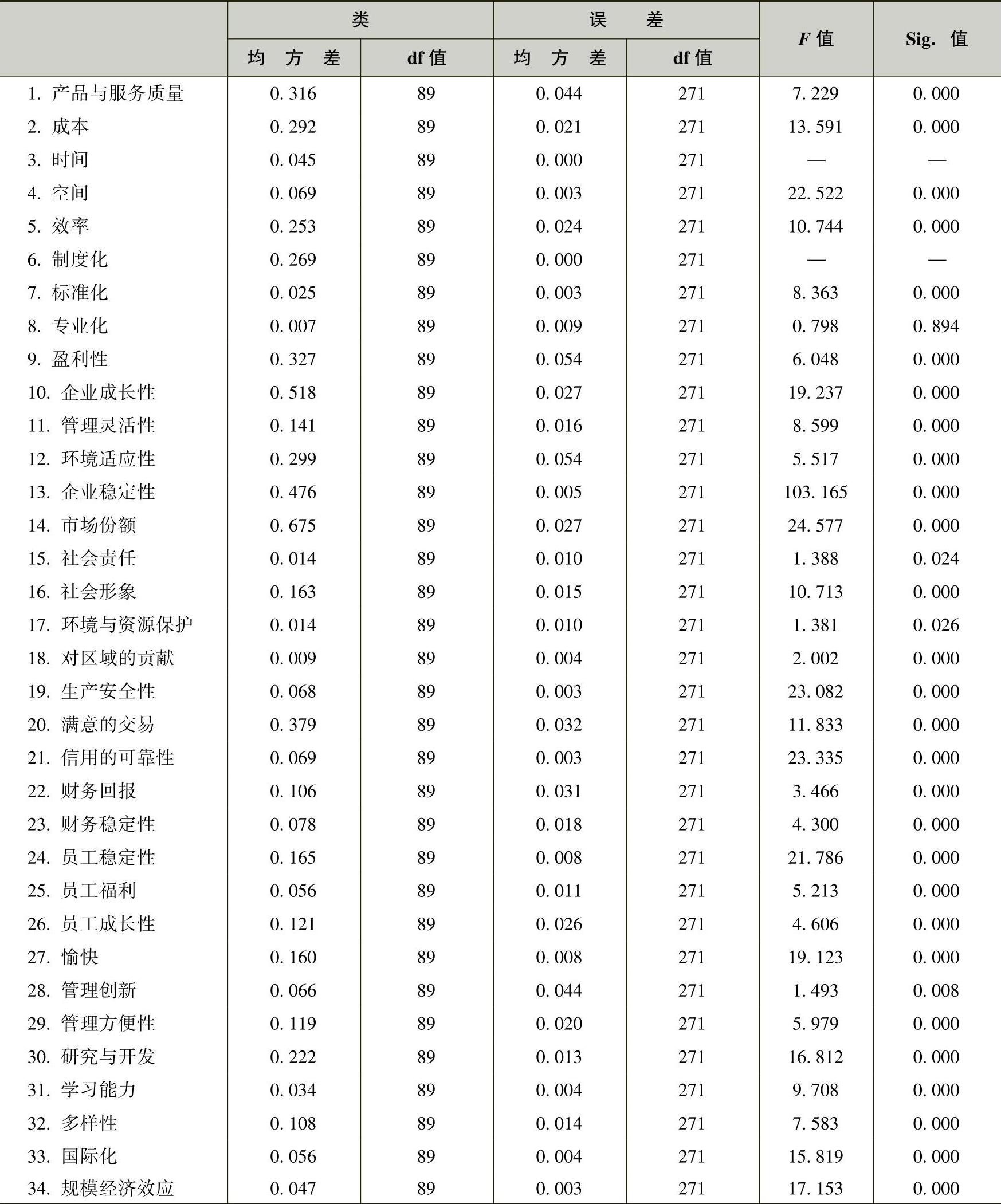
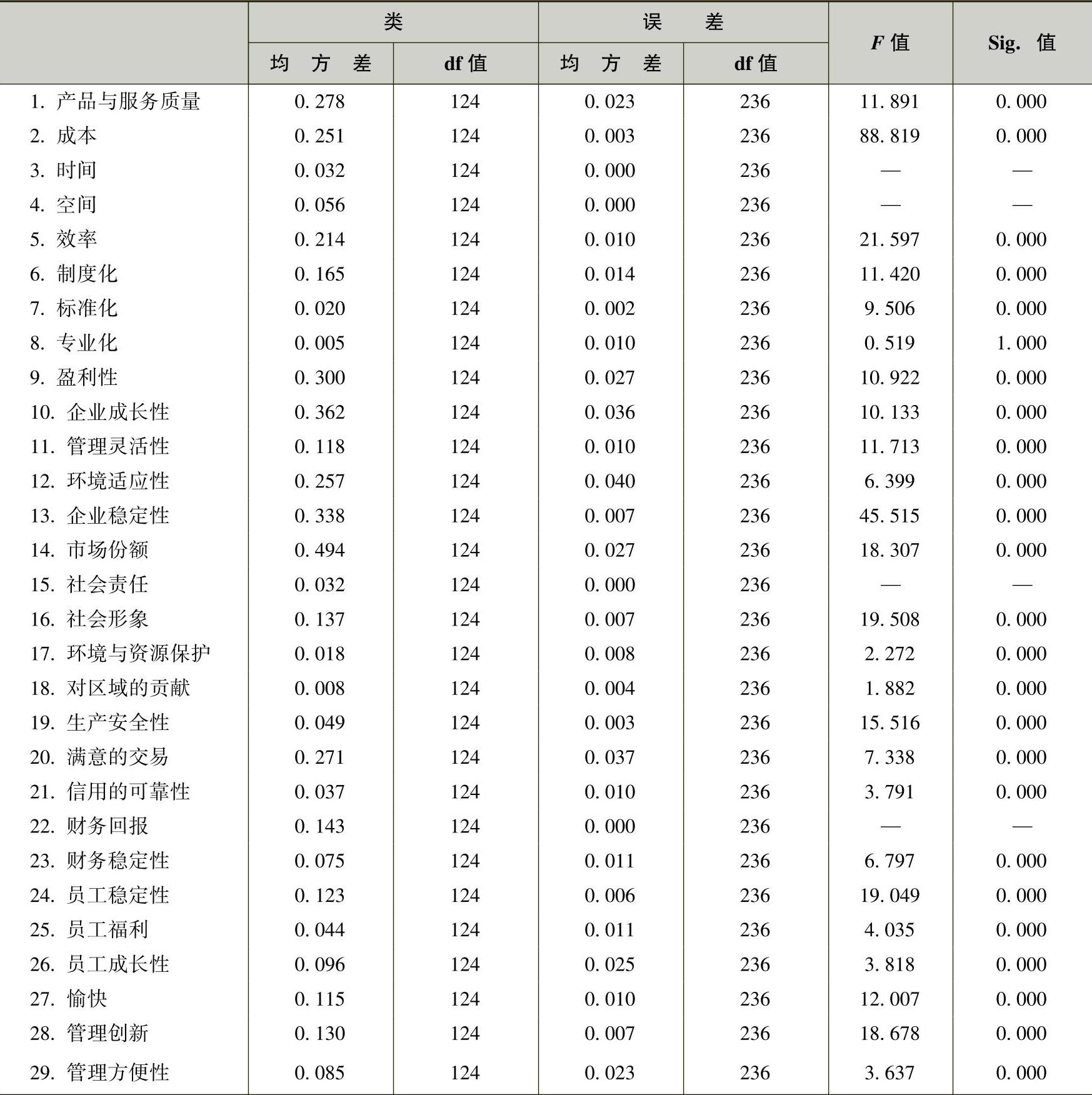
快速聚类过程还给出了方差分析(ANOVA)表。实际上是按照类别分组后对所有变量依次进行单因素方差分析,并将结果汇总到一张表格中。表6-11和表6-12就是分别进行90个聚类类别和125个聚类类别时的单因素方差分析情况。
表6-11 单因素方差分析(90类)
(续)
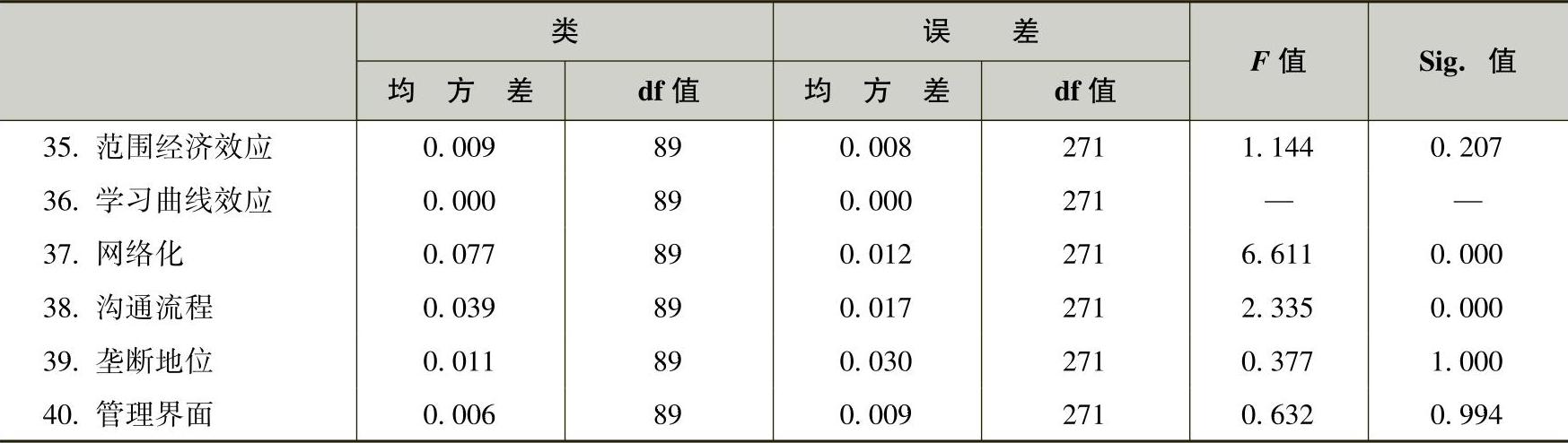
注:F检验仅用于描述的目的,因为各类已经通过最大化不同类间数据的差异被选择开来。所观察到的显著性水平不能为聚类作修正,因而也不能看作一种假设检验,以验证聚类方法是胜任的。
表6-12 单因素方差分析(125类)
(续)
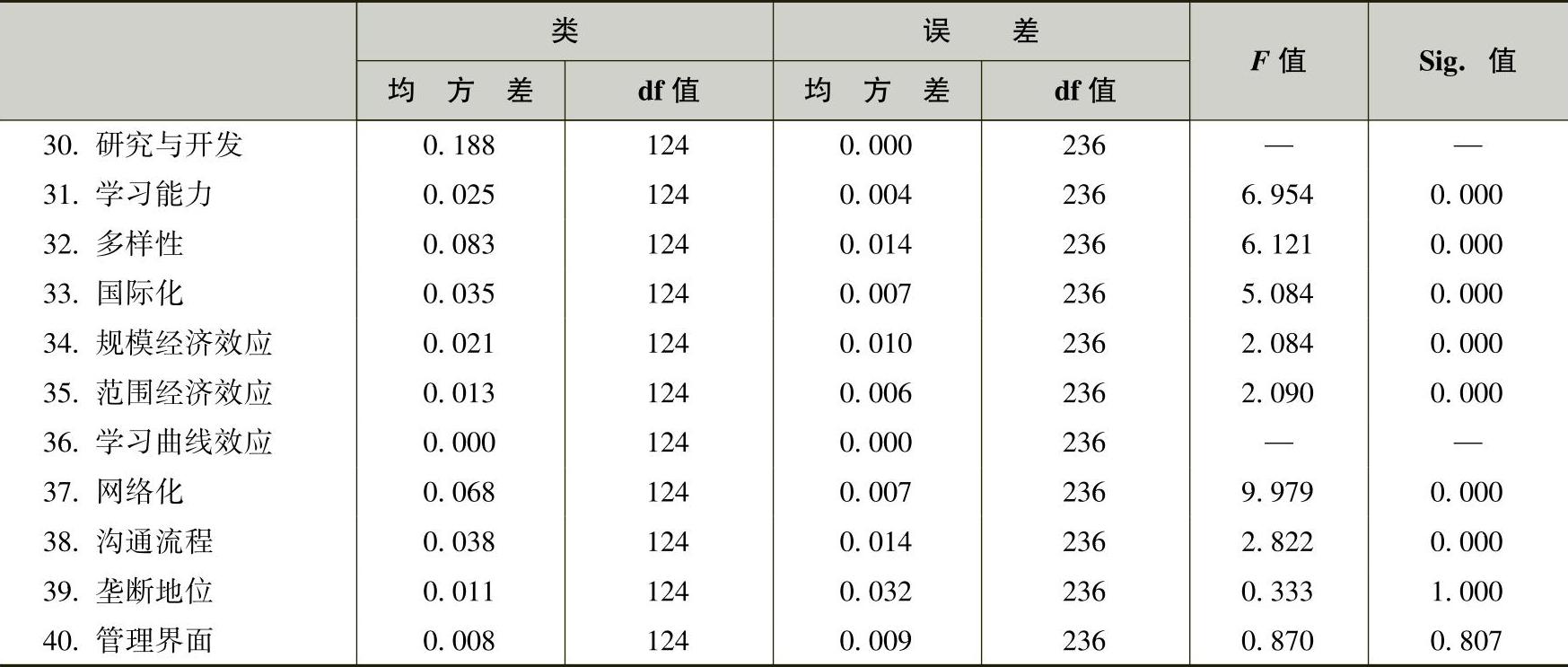
注:F检验仅用于描述的目的,因为各类已经通过最大化不同类间数据的差异被选择开来。所观察到的显著性水平不能为聚类作修正,因而也不能看作一种假设检验,以验证聚类方法是胜任的。
从方差分析中可以看出哪些变量在各类间的差异具有统计学意义。本问题的实际意义是哪些管理参数对于不同管理问题的区分具有主导价值,或者说,基于已有的管理案例分析,哪些管理参数对描述管理创新问题具有主导作用。
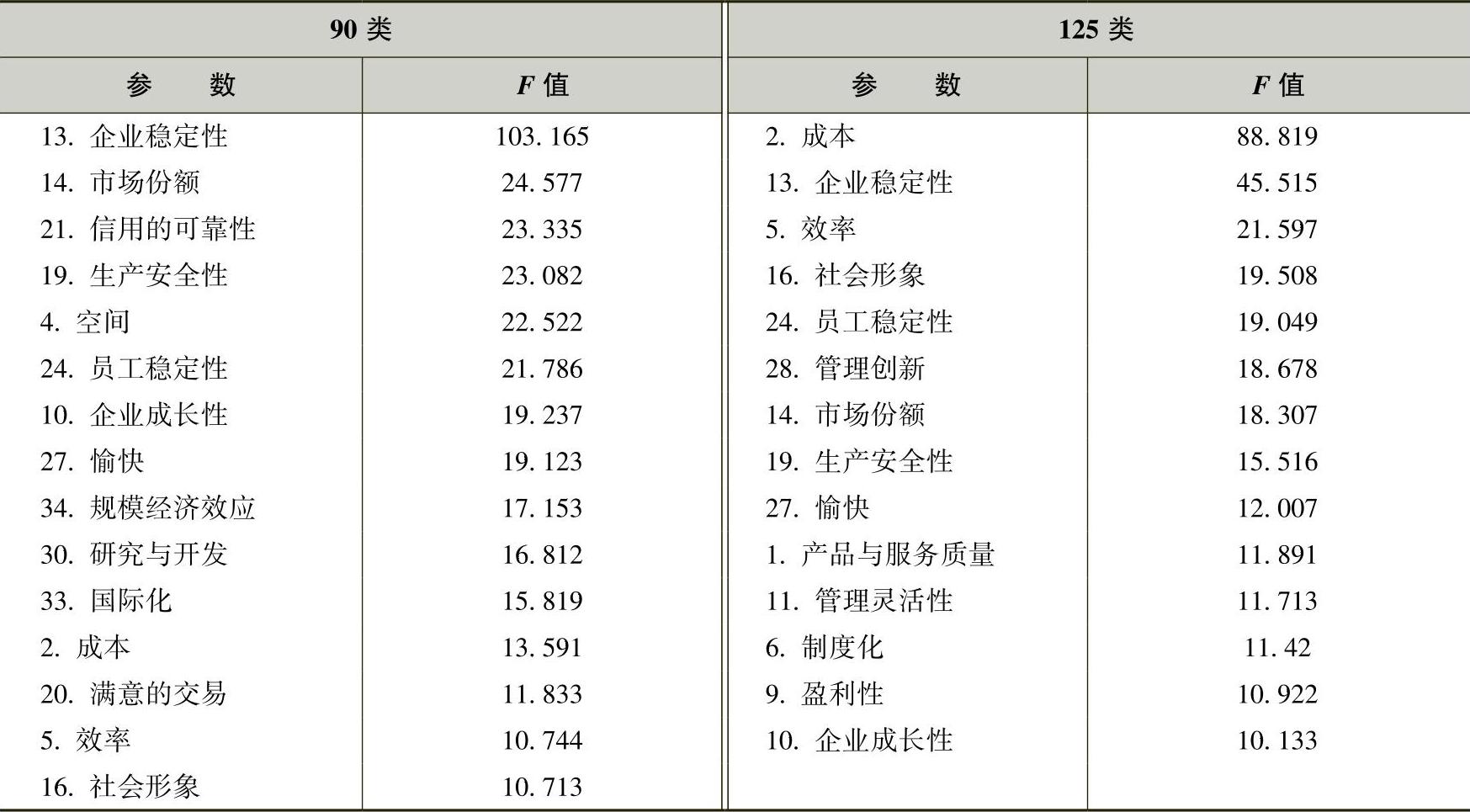
表中F值的大小最有价值,可以近似得到哪个变量在聚类分析中的作用更大的结论。在这一分析中,取F值大于10的管理参数作为聚类的主导性变量。表6-13为经整理后,分别聚类90类和125类时的F值大于10的从大到小的参数排序,也就是管理参数对聚类过程主导作用从大到小的排序。
表6-13 单因素方差分析(ANOVA)中的F值排序
3.聚类类别的整理
SPSS会在原始数据中为每一条记录增加一个变量序号,来显示该数据记录所属类的序号。依据这一输出,对所有数据记录进行类别整理(详细过程与表略)。
在某一类中,如果某一变量在两条以上的数据记录中的取值为1,则这一变量为该数据类别(即一类管理问题)的“优势的优化变量”;在某一类中,如果某一变量在两条以上的记录中的取值为-1,则这一变量为该数据类别(即一类管理问题)的“优势的劣化变量”。
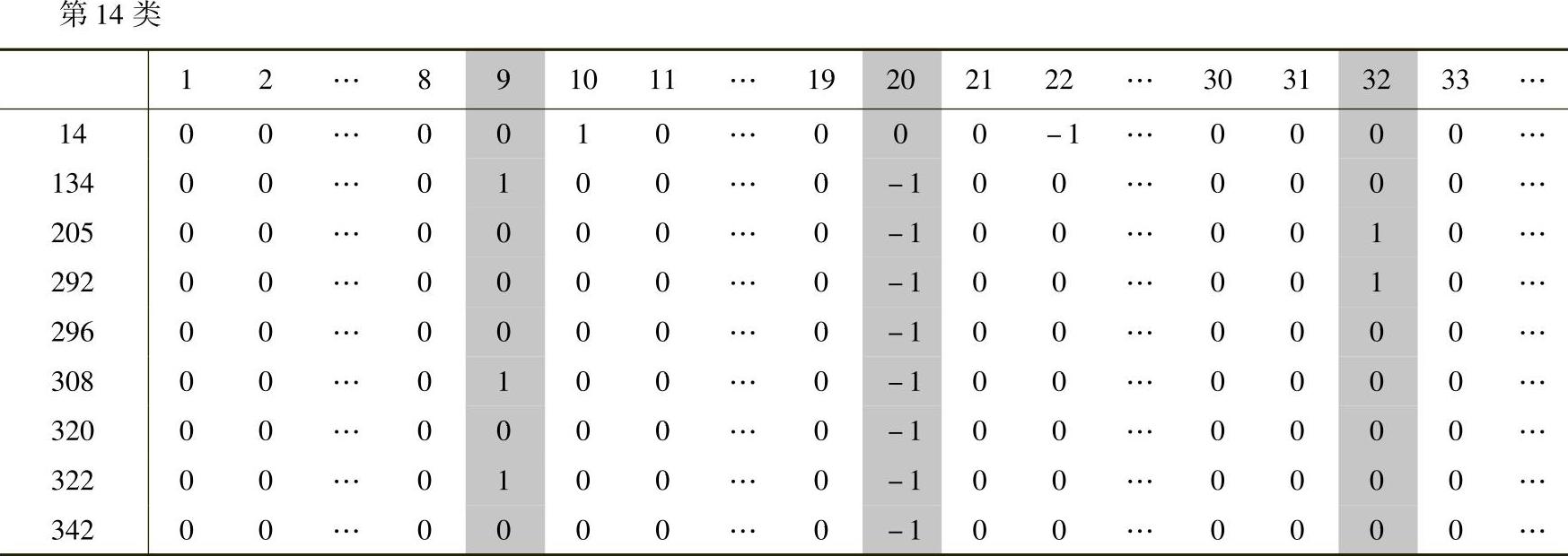
例如,表6-14为第14类的聚类情况,显示参数“9.盈利性”和参数“32.多样性”为优势优化变量,参数“20.满意的交易”为优势劣化变量,并在此类中形成两个冲突对,即9-20,32-20,在表6-14中反灰显示。
表6-14 第14类的聚类情况
对于只有一条记录的类别,就没有整理和分析的价值。此外,在某些类别中,只有优势的优化变量或只有优势的劣化变量,不能形成相冲突的参数对,也不再能进行进一步的冲突参数对的分析。例如,表6-15显示的第18类的聚类情况,其中就只有优势的优化变量,故没有相冲突的优势变量对。
表6-15 第18类的聚类情况

但是,需要特别注意的是,被放弃进行冲突分析的类别数据并不是没有用处了,随着更多案例数据以及其他形式数据的引入,可能使其中的一些类别具有冲突参数分析的价值。这些数据需要保留,以用于进一步的研究中。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





